 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMER-DG: Modality-Entropy Regularization for Multimodal Domain Generalization
May 03, 2026Deploying multimodal models in real-world scenarios requires generalization to new environments where recording conditions differ from training, a challenge known as multimodal domain generalization (MMDG). Standard architectures employ separate encoders for each modality and a fusion module, training the system end-to-end by optimizing on the fused features. In this paper, we identify that such joint optimization causes encoders to exploit cross-modal co-occurrences, statistical relationships between modalities that arise from source-specific recording conditions, rather than learning domain-invariant features. We term this failure mode Fusion Overfitting. To address this, we propose Modality-Entropy Regularization for Domain Generalization (MER-DG), which maximizes the entropy of each encoder's feature distribution to preserve feature diversity. MER-DG is architecture-agnostic and integrates into existing multimodal frameworks as an additive loss term. Extensive experiments on EPIC-Kitchens and HAC benchmarks demonstrate average improvements of approximately 5% over standard fusion and approximately 2% over state-of-the-art methods.
Hierarchical and Multimodal Data for Daily Activity Understanding
Apr 24, 2025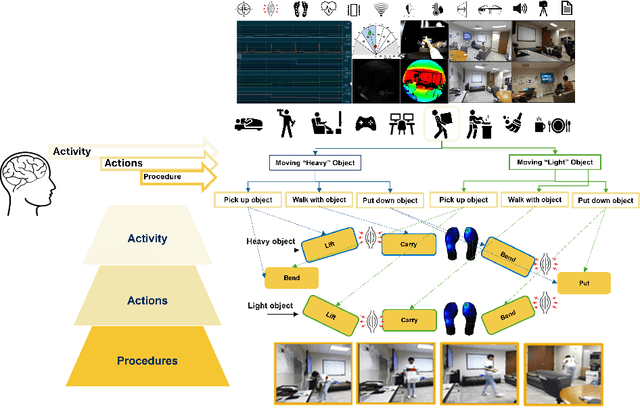


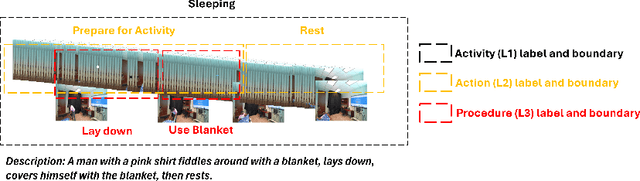
Daily Activity Recordings for Artificial Intelligence (DARai, pronounced "Dahr-ree") is a multimodal, hierarchically annotated dataset constructed to understand human activities in real-world settings. DARai consists of continuous scripted and unscripted recordings of 50 participants in 10 different environments, totaling over 200 hours of data from 20 sensors including multiple camera views, depth and radar sensors, wearable inertial measurement units (IMUs), electromyography (EMG), insole pressure sensors, biomonitor sensors, and gaze tracker. To capture the complexity in human activities, DARai is annotated at three levels of hierarchy: (i) high-level activities (L1) that are independent tasks, (ii) lower-level actions (L2) that are patterns shared between activities, and (iii) fine-grained procedures (L3) that detail the exact execution steps for actions. The dataset annotations and recordings are designed so that 22.7% of L2 actions are shared between L1 activities and 14.2% of L3 procedures are shared between L2 actions. The overlap and unscripted nature of DARai allows counterfactual activities in the dataset. Experiments with various machine learning models showcase the value of DARai in uncovering important challenges in human-centered applications. Specifically, we conduct unimodal and multimodal sensor fusion experiments for recognition, temporal localization, and future action anticipation across all hierarchical annotation levels. To highlight the limitations of individual sensors, we also conduct domain-variant experiments that are enabled by DARai's multi-sensor and counterfactual activity design setup. The code, documentation, and dataset are available at the dedicated DARai website: https://alregib.ece.gatech.edu/software-and-datasets/darai-daily-activity-recordings-for-artificial-intelligence-and-machine-learning/
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Aug 20, 2024



Crowdsourcing annotations has created a paradigm shift in the availability of labeled data for machine learning. Availability of large datasets has accelerated progress in common knowledge applications involving visual and language data. However, specialized applications that require expert labels lag in data availability. One such application is fault segmentation in subsurface imaging. Detecting, tracking, and analyzing faults has broad societal implications in predicting fluid flows, earthquakes, and storing excess atmospheric CO$_2$. However, delineating faults with current practices is a labor-intensive activity that requires precise analysis of subsurface imaging data by geophysicists. In this paper, we propose the $\texttt{CRACKS}$ dataset to detect and segment faults in subsurface images by utilizing crowdsourced resources. We leverage Amazon Mechanical Turk to obtain fault delineations from sections of the Netherlands North Sea subsurface images from (i) $26$ novices who have no exposure to subsurface data and were shown a video describing and labeling faults, (ii) $8$ practitioners who have previously interacted and worked on subsurface data, (iii) one geophysicist to label $7636$ faults in the region. Note that all novices, practitioners, and the expert segment faults on the same subsurface volume with disagreements between and among the novices and practitioners. Additionally, each fault annotation is equipped with the confidence level of the annotator. The paper provides benchmarks on detecting and segmenting the expert labels, given the novice and practitioner labels. Additional details along with the dataset links and codes are available at $\href{https://alregib.ece.gatech.edu/cracks-crowdsourcing-resources-for-analysis-and-categorization-of-key-subsurface-faults/}{link}$.
Explaining Representation Learning with Perceptual Components
Jun 11, 2024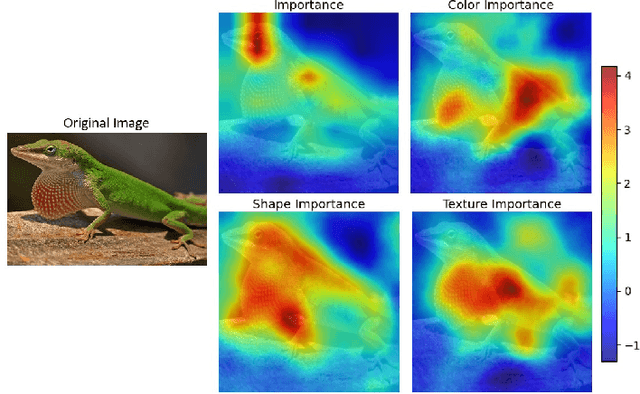

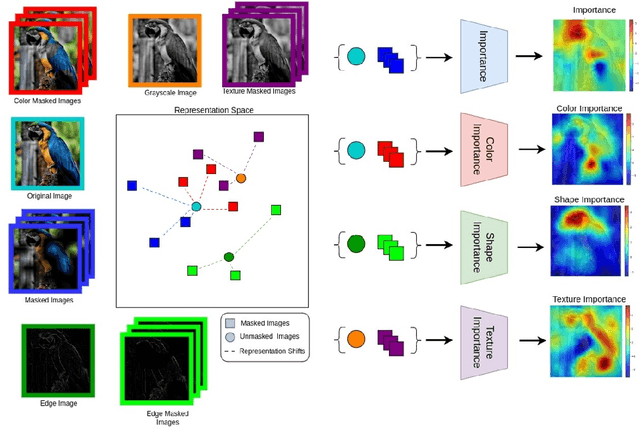
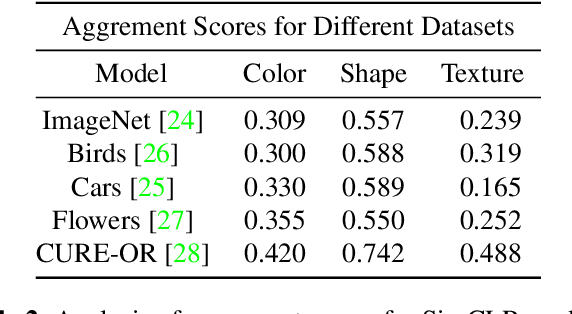
Self-supervised models create representation spaces that lack clear semantic meaning. This interpretability problem of representations makes traditional explainability methods ineffective in this context. In this paper, we introduce a novel method to analyze representation spaces using three key perceptual components: color, shape, and texture. We employ selective masking of these components to observe changes in representations, resulting in distinct importance maps for each. In scenarios, where labels are absent, these importance maps provide more intuitive explanations as they are integral to the human visual system. Our approach enhances the interpretability of the representation space, offering explanations that resonate with human visual perception. We analyze how different training objectives create distinct representation spaces using perceptual components. Additionally, we examine the representation of images across diverse image domains, providing insights into the role of these components in different contexts.
Taxes Are All You Need: Integration of Taxonomical Hierarchy Relationships into the Contrastive Loss
Jun 10, 2024



In this work, we propose a novel supervised contrastive loss that enables the integration of taxonomic hierarchy information during the representation learning process. A supervised contrastive loss operates by enforcing that images with the same class label (positive samples) project closer to each other than images with differing class labels (negative samples). The advantage of this approach is that it directly penalizes the structure of the representation space itself. This enables greater flexibility with respect to encoding semantic concepts. However, the standard supervised contrastive loss only enforces semantic structure based on the downstream task (i.e. the class label). In reality, the class label is only one level of a \emph{hierarchy of different semantic relationships known as a taxonomy}. For example, the class label is oftentimes the species of an animal, but between different classes there are higher order relationships such as all animals with wings being ``birds". We show that by explicitly accounting for these relationships with a weighting penalty in the contrastive loss we can out-perform the supervised contrastive loss. Additionally, we demonstrate the adaptability of the notion of a taxonomy by integrating our loss into medical and noise-based settings that show performance improvements by as much as 7%.
Exploiting the Distortion-Semantic Interaction in Fisheye Data
May 06, 2023



In this work, we present a methodology to shape a fisheye-specific representation space that reflects the interaction between distortion and semantic context present in this data modality. Fisheye data has the wider field of view advantage over other types of cameras, but this comes at the expense of high radial distortion. As a result, objects further from the center exhibit deformations that make it difficult for a model to identify their semantic context. While previous work has attempted architectural and training augmentation changes to alleviate this effect, no work has attempted to guide the model towards learning a representation space that reflects this interaction between distortion and semantic context inherent to fisheye data. We introduce an approach to exploit this relationship by first extracting distortion class labels based on an object's distance from the center of the image. We then shape a backbone's representation space with a weighted contrastive loss that constrains objects of the same semantic class and distortion class to be close to each other within a lower dimensional embedding space. This backbone trained with both semantic and distortion information is then fine-tuned within an object detection setting to empirically evaluate the quality of the learnt representation. We show this method leads to performance improvements by as much as 1.1% mean average precision over standard object detection strategies and .6% improvement over other state of the art representation learning approaches.