 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Representation Learning with Perceptual Components
Paper and Code
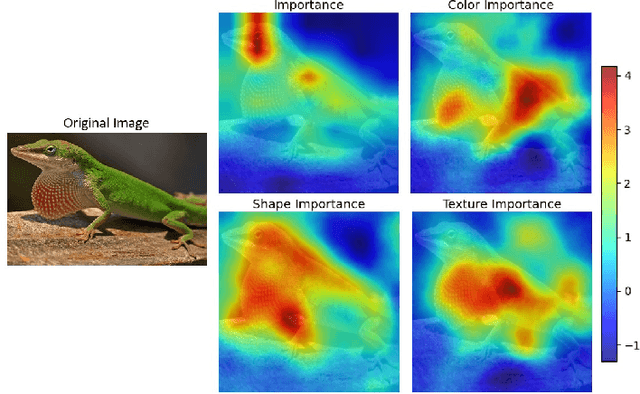

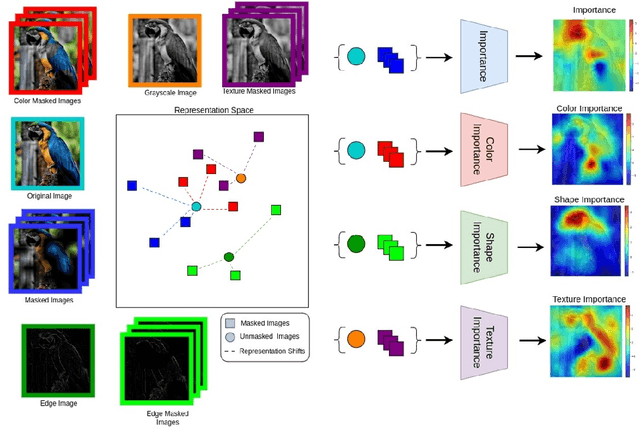
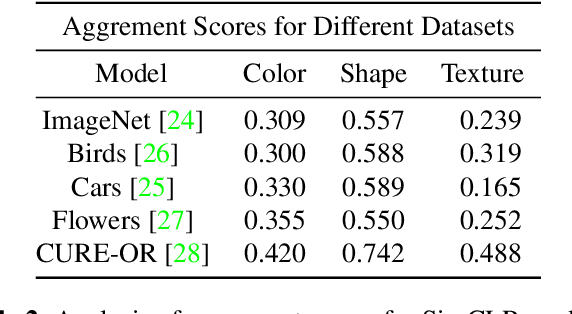
Self-supervised models create representation spaces that lack clear semantic meaning. This interpretability problem of representations makes traditional explainability methods ineffective in this context. In this paper, we introduce a novel method to analyze representation spaces using three key perceptual components: color, shape, and texture. We employ selective masking of these components to observe changes in representations, resulting in distinct importance maps for each. In scenarios, where labels are absent, these importance maps provide more intuitive explanations as they are integral to the human visual system. Our approach enhances the interpretability of the representation space, offering explanations that resonate with human visual perception. We analyze how different training objectives create distinct representation spaces using perceptual components. Additionally, we examine the representation of images across diverse image domains, providing insights into the role of these components in different contexts.