 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
OSDEnhancer: Taming Real-World Space-Time Video Super-Resolution with One-Step Diffusion
Jan 28, 2026Diffusion models (DMs) have demonstrated exceptional success in video super-resolution (VSR), showcasing a powerful capacity for generating fine-grained details. However, their potential for space-time video super-resolution (STVSR), which necessitates not only recovering realistic visual content from low-resolution to high-resolution but also improving the frame rate with coherent temporal dynamics, remains largely underexplored. Moreover, existing STVSR methods predominantly address spatiotemporal upsampling under simplified degradation assumptions, which often struggle in real-world scenarios with complex unknown degradations. Such a high demand for reconstruction fidelity and temporal consistency makes the development of a robust STVSR framework particularly non-trivial. To address these challenges, we propose OSDEnhancer, a novel framework that, to the best of our knowledge, represents the first method to achieve real-world STVSR through an efficient one-step diffusion process. OSDEnhancer initializes essential spatiotemporal structures through a linear pre-interpolation strategy and pivots on training temporal refinement and spatial enhancement mixture of experts (TR-SE MoE), which allows distinct expert pathways to progressively learn robust, specialized representations for temporal coherence and spatial detail, further collaboratively reinforcing each other during inference. A bidirectional deformable variational autoencoder (VAE) decoder is further introduced to perform recurrent spatiotemporal aggregation and propagation, enhancing cross-frame reconstruction fidelity. Experiments demonstrate that the proposed method achieves state-of-the-art performance while maintaining superior generalization capability in real-world scenarios.
RLSLM: A Hybrid Reinforcement Learning Framework Aligning Rule-Based Social Locomotion Model with Human Social Norms
Nov 14, 2025Navigating human-populated environments without causing discomfort is a critical capability for socially-aware agents. While rule-based approaches offer interpretability through predefined psychological principles, they often lack generalizability and flexibility. Conversely, data-driven methods can learn complex behaviors from large-scale datasets, but are typically inefficient, opaque, and difficult to align with human intuitions. To bridge this gap, we propose RLSLM, a hybrid Reinforcement Learning framework that integrates a rule-based Social Locomotion Model, grounded in empirical behavioral experiments, into the reward function of a reinforcement learning framework. The social locomotion model generates an orientation-sensitive social comfort field that quantifies human comfort across space, enabling socially aligned navigation policies with minimal training. RLSLM then jointly optimizes mechanical energy and social comfort, allowing agents to avoid intrusions into personal or group space. A human-agent interaction experiment using an immersive VR-based setup demonstrates that RLSLM outperforms state-of-the-art rule-based models in user experience. Ablation and sensitivity analyses further show the model's significantly improved interpretability over conventional data-driven methods. This work presents a scalable, human-centered methodology that effectively integrates cognitive science and machine learning for real-world social navigation.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025


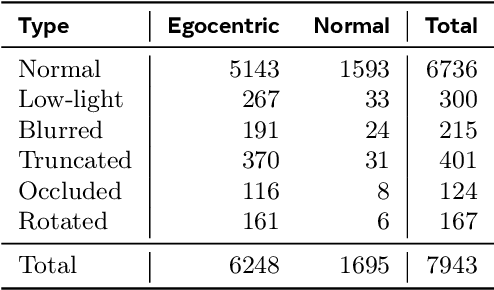
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
May 13, 2025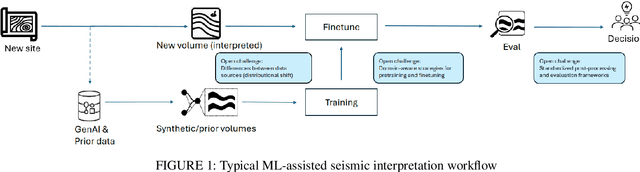
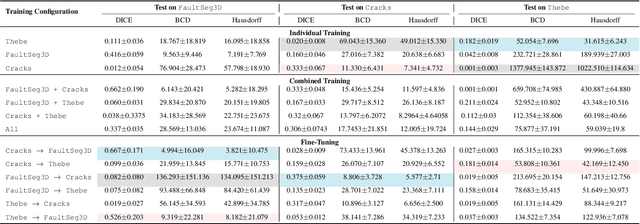
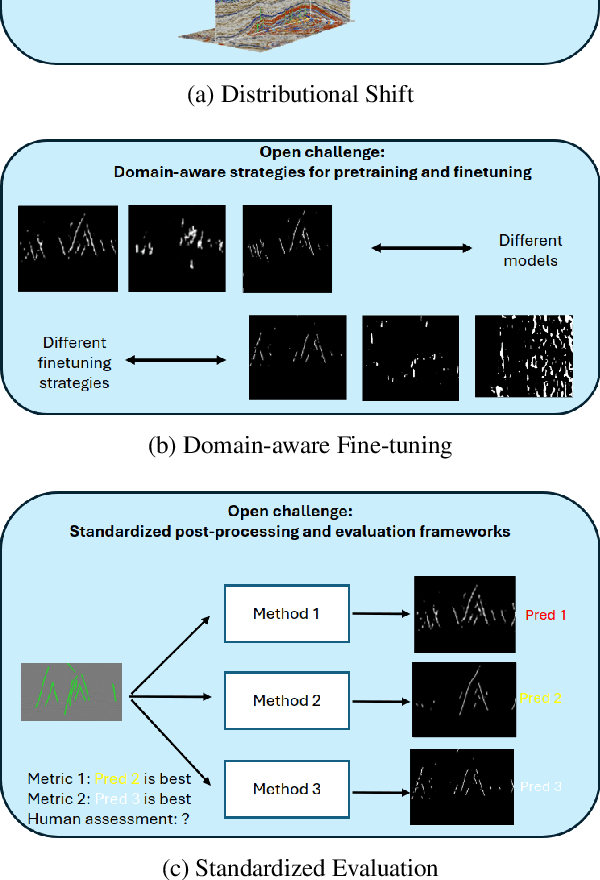
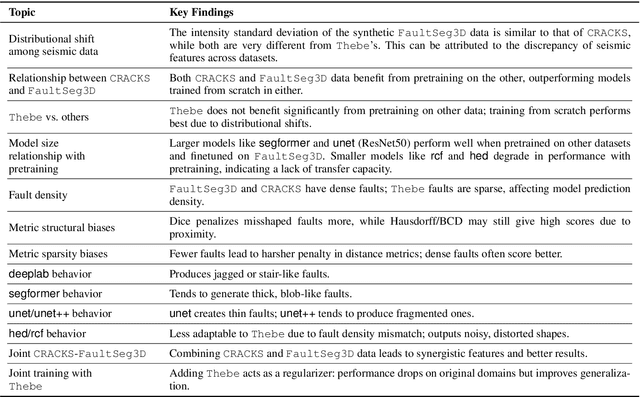
Machine learning has taken a critical role in seismic interpretation workflows, especially in fault delineation tasks. However, despite the recent proliferation of pretrained models and synthetic datasets, the field still lacks a systematic understanding of the generalizability limits of these models across seismic data representing a variety of geologic, acquisition and processing settings. Distributional shifts between different data sources, limitations in fine-tuning strategies and labeled data accessibility, and inconsistent evaluation protocols all represent major roadblocks in the deployment of reliable and robust models in real-world exploration settings. In this paper, we present the first large-scale benchmarking study explicitly designed to provide answers and guidelines for domain shift strategies in seismic interpretation. Our benchmark encompasses over $200$ models trained and evaluated on three heterogeneous datasets (synthetic and real data) including FaultSeg3D, CRACKS, and Thebe. We systematically assess pretraining, fine-tuning, and joint training strategies under varying degrees of domain shift. Our analysis highlights the fragility of current fine-tuning practices, the emergence of catastrophic forgetting, and the challenges of interpreting performance in a systematic manner. We establish a robust experimental baseline to provide insights into the tradeoffs inherent to current fault delineation workflows, and shed light on directions for developing more generalizable, interpretable and effective machine learning models for seismic interpretation. The insights and analyses reported provide a set of guidelines on the deployment of fault delineation models within seismic interpretation workflows.
PAL -- Parallel active learning for machine-learned potentials
Nov 30, 2024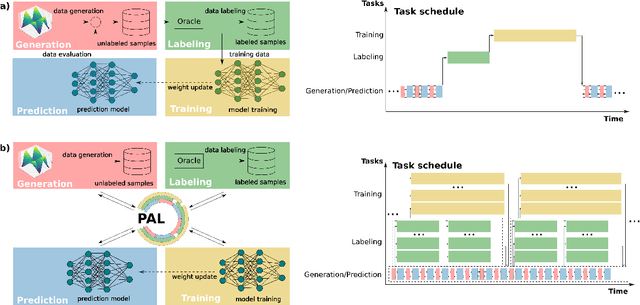

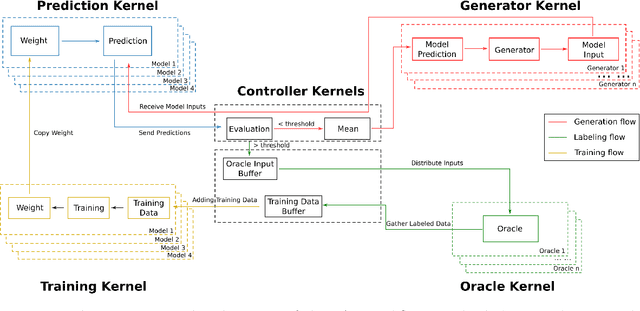
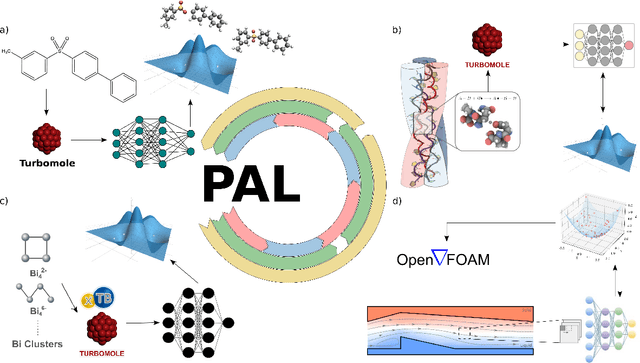
Constructing datasets representative of the target domain is essential for training effective machine learning models. Active learning (AL) is a promising method that iteratively extends training data to enhance model performance while minimizing data acquisition costs. However, current AL workflows often require human intervention and lack parallelism, leading to inefficiencies and underutilization of modern computational resources. In this work, we introduce PAL, an automated, modular, and parallel active learning library that integrates AL tasks and manages their execution and communication on shared- and distributed-memory systems using the Message Passing Interface (MPI). PAL provides users with the flexibility to design and customize all components of their active learning scenarios, including machine learning models with uncertainty estimation, oracles for ground truth labeling, and strategies for exploring the target space. We demonstrate that PAL significantly reduces computational overhead and improves scalability, achieving substantial speed-ups through asynchronous parallelization on CPU and GPU hardware. Applications of PAL to several real-world scenarios - including ground-state reactions in biomolecular systems, excited-state dynamics of molecules, simulations of inorganic clusters, and thermo-fluid dynamics - illustrate its effectiveness in accelerating the development of machine learning models. Our results show that PAL enables efficient utilization of high-performance computing resources in active learning workflows, fostering advancements in scientific research and engineering applications.
Scaling Particle Collision Data Analysis
Nov 28, 2024For decades, researchers have developed task-specific models to address scientific challenges across diverse disciplines. Recently, large language models (LLMs) have shown enormous capabilities in handling general tasks; however, these models encounter difficulties in addressing real-world scientific problems, particularly in domains involving large-scale numerical data analysis, such as experimental high energy physics. This limitation is primarily due to BPE tokenization's inefficacy with numerical data. In this paper, we propose a task-agnostic architecture, BBT-Neutron, which employs a binary tokenization method to facilitate pretraining on a mixture of textual and large-scale numerical experimental data. The project code is available at https://github.com/supersymmetry-technologies/bbt-neutron. We demonstrate the application of BBT-Neutron to Jet Origin Identification (JoI), a critical categorization challenge in high-energy physics that distinguishes jets originating from various quarks or gluons. Our results indicate that BBT-Neutron achieves comparable performance to state-of-the-art task-specific JoI models. Furthermore, we examine the scaling behavior of BBT-Neutron's performance with increasing data volume, suggesting the potential for BBT-Neutron to serve as a foundational model for particle physics data analysis, with possible extensions to a broad spectrum of scientific computing applications for Big Science experiments, industrial manufacturing and spacial computing.
Optimizing Multispectral Object Detection: A Bag of Tricks and Comprehensive Benchmarks
Nov 27, 2024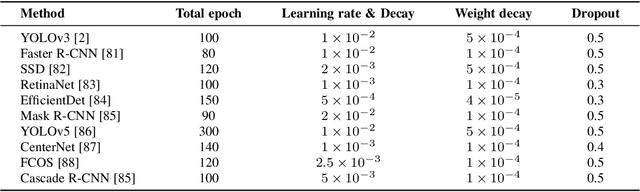
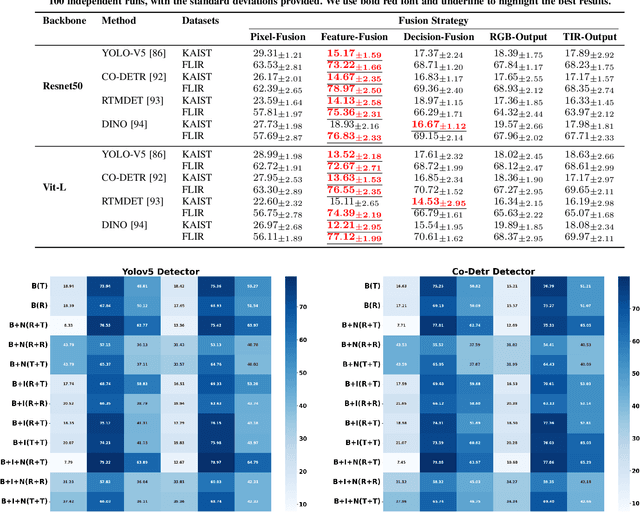
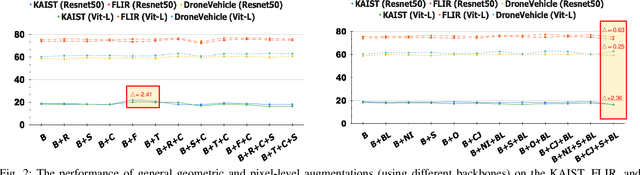
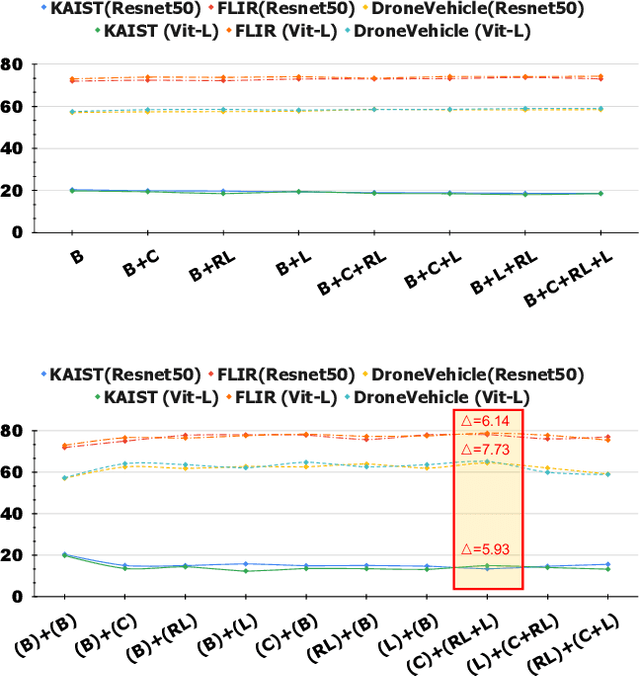
Multispectral object detection, utilizing RGB and TIR (thermal infrared) modalities, is widely recognized as a challenging task. It requires not only the effective extraction of features from both modalities and robust fusion strategies, but also the ability to address issues such as spectral discrepancies, spatial misalignment, and environmental dependencies between RGB and TIR images. These challenges significantly hinder the generalization of multispectral detection systems across diverse scenarios. Although numerous studies have attempted to overcome these limitations, it remains difficult to clearly distinguish the performance gains of multispectral detection systems from the impact of these "optimization techniques". Worse still, despite the rapid emergence of high-performing single-modality detection models, there is still a lack of specialized training techniques that can effectively adapt these models for multispectral detection tasks. The absence of a standardized benchmark with fair and consistent experimental setups also poses a significant barrier to evaluating the effectiveness of new approaches. To this end, we propose the first fair and reproducible benchmark specifically designed to evaluate the training "techniques", which systematically classifies existing multispectral object detection methods, investigates their sensitivity to hyper-parameters, and standardizes the core configurations. A comprehensive evaluation is conducted across multiple representative multispectral object detection datasets, utilizing various backbone networks and detection frameworks. Additionally, we introduce an efficient and easily deployable multispectral object detection framework that can seamlessly optimize high-performing single-modality models into dual-modality models, integrating our advanced training techniques.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Aug 20, 2024



Crowdsourcing annotations has created a paradigm shift in the availability of labeled data for machine learning. Availability of large datasets has accelerated progress in common knowledge applications involving visual and language data. However, specialized applications that require expert labels lag in data availability. One such application is fault segmentation in subsurface imaging. Detecting, tracking, and analyzing faults has broad societal implications in predicting fluid flows, earthquakes, and storing excess atmospheric CO$_2$. However, delineating faults with current practices is a labor-intensive activity that requires precise analysis of subsurface imaging data by geophysicists. In this paper, we propose the $\texttt{CRACKS}$ dataset to detect and segment faults in subsurface images by utilizing crowdsourced resources. We leverage Amazon Mechanical Turk to obtain fault delineations from sections of the Netherlands North Sea subsurface images from (i) $26$ novices who have no exposure to subsurface data and were shown a video describing and labeling faults, (ii) $8$ practitioners who have previously interacted and worked on subsurface data, (iii) one geophysicist to label $7636$ faults in the region. Note that all novices, practitioners, and the expert segment faults on the same subsurface volume with disagreements between and among the novices and practitioners. Additionally, each fault annotation is equipped with the confidence level of the annotator. The paper provides benchmarks on detecting and segmenting the expert labels, given the novice and practitioner labels. Additional details along with the dataset links and codes are available at $\href{https://alregib.ece.gatech.edu/cracks-crowdsourcing-resources-for-analysis-and-categorization-of-key-subsurface-faults/}{link}$.