 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraPO: A Semi-Supervised Reinforcement Learning Framework for Boosting LLM Reasoning
Dec 15, 2025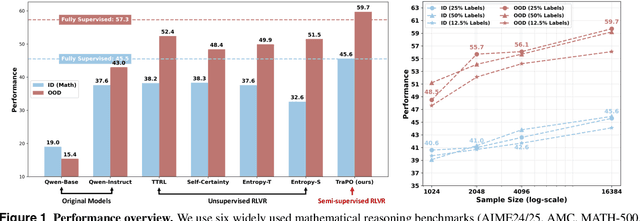
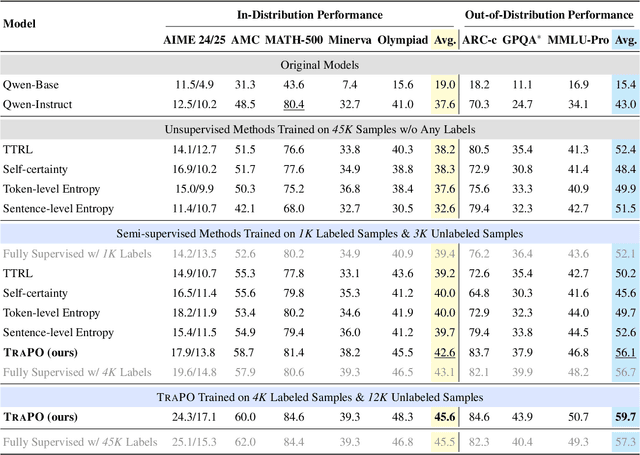
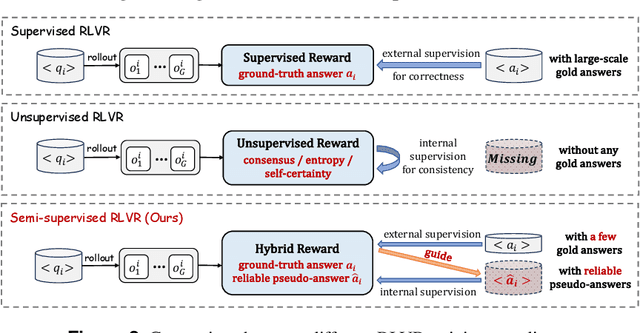
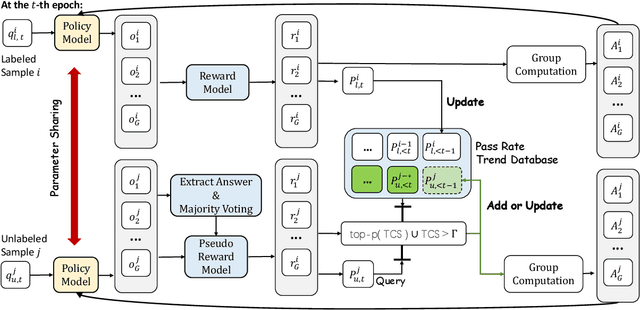
Reinforcement learning with verifiable rewards (RLVR) has proven effective in training large reasoning models (LRMs) by leveraging answer-verifiable signals to guide policy optimization, which, however, suffers from high annotation costs. To alleviate this problem, recent work has explored unsupervised RLVR methods that derive rewards solely from the model's internal consistency, such as through entropy and majority voting. While seemingly promising, these methods often suffer from model collapse in the later stages of training, which may arise from the reinforcement of incorrect reasoning patterns in the absence of external supervision. In this work, we investigate a novel semi-supervised RLVR paradigm that utilizes a small labeled set to guide RLVR training on unlabeled samples. Our key insight is that supervised rewards are essential for stabilizing consistency-based training on unlabeled samples, ensuring that only reasoning patterns verified on labeled instances are incorporated into RL training. Technically, we propose an effective policy optimization algorithm, TraPO, that identifies reliable unlabeled samples by matching their learning trajectory similarity to labeled ones. Building on this, TraPO achieves remarkable data efficiency and strong generalization on six widely used mathematical reasoning benchmarks (AIME24/25, AMC, MATH-500, Minerva, and Olympiad) and three out-of-distribution tasks (ARC-c, GPQA-diamond, and MMLU-pro). With only 1K labeled and 3K unlabeled samples, TraPO reaches 42.6% average accuracy, surpassing the best unsupervised method trained on 45K unlabeled samples (38.3%). Notably, when using 4K labeled and 12K unlabeled samples, TraPO even outperforms the fully supervised model trained on the full 45K labeled samples on all benchmarks, while using only 10% of the labeled data. The code is available via https://github.com/ShenzhiYang2000/TRAPO.
RealHiTBench: A Comprehensive Realistic Hierarchical Table Benchmark for Evaluating LLM-Based Table Analysis
Jun 16, 2025With the rapid advancement of Large Language Models (LLMs), there is an increasing need for challenging benchmarks to evaluate their capabilities in handling complex tabular data. However, existing benchmarks are either based on outdated data setups or focus solely on simple, flat table structures. In this paper, we introduce RealHiTBench, a comprehensive benchmark designed to evaluate the performance of both LLMs and Multimodal LLMs (MLLMs) across a variety of input formats for complex tabular data, including LaTeX, HTML, and PNG. RealHiTBench also includes a diverse collection of tables with intricate structures, spanning a wide range of task types. Our experimental results, using 25 state-of-the-art LLMs, demonstrate that RealHiTBench is indeed a challenging benchmark. Moreover, we also develop TreeThinker, a tree-based pipeline that organizes hierarchical headers into a tree structure for enhanced tabular reasoning, validating the importance of improving LLMs' perception of table hierarchies. We hope that our work will inspire further research on tabular data reasoning and the development of more robust models. The code and data are available at https://github.com/cspzyy/RealHiTBench.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.