 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraPO: A Semi-Supervised Reinforcement Learning Framework for Boosting LLM Reasoning
Dec 15, 2025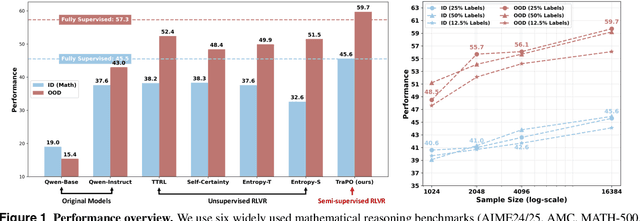
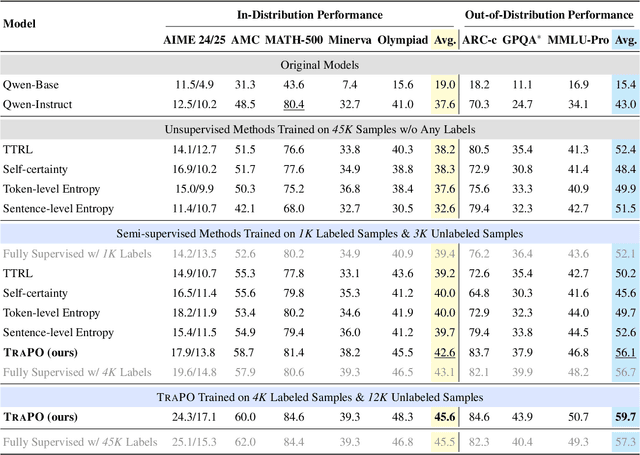
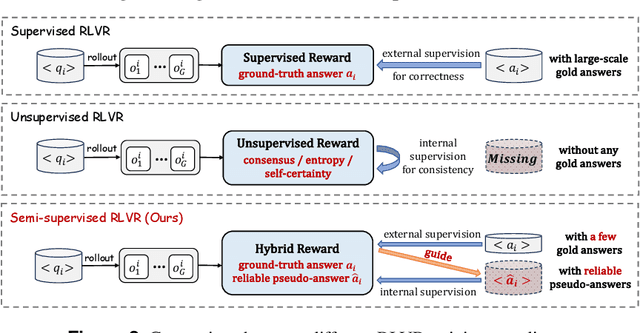
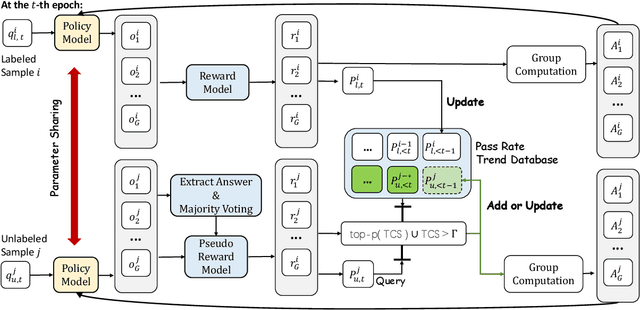
Reinforcement learning with verifiable rewards (RLVR) has proven effective in training large reasoning models (LRMs) by leveraging answer-verifiable signals to guide policy optimization, which, however, suffers from high annotation costs. To alleviate this problem, recent work has explored unsupervised RLVR methods that derive rewards solely from the model's internal consistency, such as through entropy and majority voting. While seemingly promising, these methods often suffer from model collapse in the later stages of training, which may arise from the reinforcement of incorrect reasoning patterns in the absence of external supervision. In this work, we investigate a novel semi-supervised RLVR paradigm that utilizes a small labeled set to guide RLVR training on unlabeled samples. Our key insight is that supervised rewards are essential for stabilizing consistency-based training on unlabeled samples, ensuring that only reasoning patterns verified on labeled instances are incorporated into RL training. Technically, we propose an effective policy optimization algorithm, TraPO, that identifies reliable unlabeled samples by matching their learning trajectory similarity to labeled ones. Building on this, TraPO achieves remarkable data efficiency and strong generalization on six widely used mathematical reasoning benchmarks (AIME24/25, AMC, MATH-500, Minerva, and Olympiad) and three out-of-distribution tasks (ARC-c, GPQA-diamond, and MMLU-pro). With only 1K labeled and 3K unlabeled samples, TraPO reaches 42.6% average accuracy, surpassing the best unsupervised method trained on 45K unlabeled samples (38.3%). Notably, when using 4K labeled and 12K unlabeled samples, TraPO even outperforms the fully supervised model trained on the full 45K labeled samples on all benchmarks, while using only 10% of the labeled data. The code is available via https://github.com/ShenzhiYang2000/TRAPO.
Bounded and Uniform Energy-based Out-of-distribution Detection for Graphs
Apr 18, 2025Given the critical role of graphs in real-world applications and their high-security requirements, improving the ability of graph neural networks (GNNs) to detect out-of-distribution (OOD) data is an urgent research problem. The recent work GNNSAFE proposes a framework based on the aggregation of negative energy scores that significantly improves the performance of GNNs to detect node-level OOD data. However, our study finds that score aggregation among nodes is susceptible to extreme values due to the unboundedness of the negative energy scores and logit shifts, which severely limits the accuracy of GNNs in detecting node-level OOD data. In this paper, we propose NODESAFE: reducing the generation of extreme scores of nodes by adding two optimization terms that make the negative energy scores bounded and mitigate the logit shift. Experimental results show that our approach dramatically improves the ability of GNNs to detect OOD data at the node level, e.g., in detecting OOD data induced by Structure Manipulation, the metric of FPR95 (lower is better) in scenarios without (with) OOD data exposure are reduced from the current SOTA by 28.4% (22.7%).
NodeReg: Mitigating the Imbalance and Distribution Shift Effects in Semi-Supervised Node Classification via Norm Consistency
Mar 05, 2025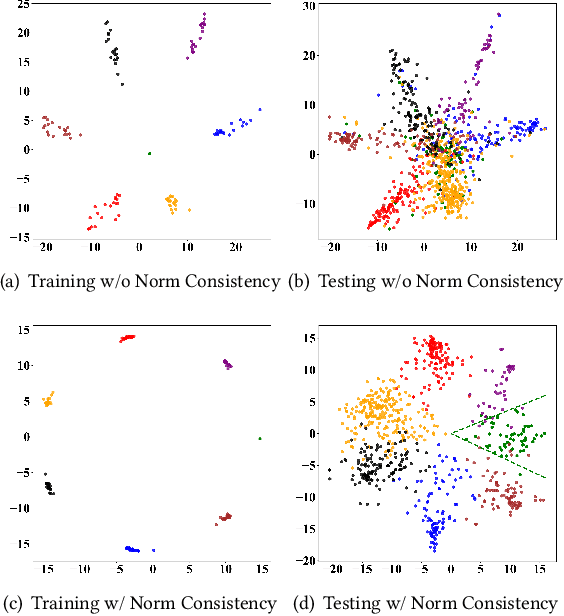



Aggregating information from neighboring nodes benefits graph neural networks (GNNs) in semi-supervised node classification tasks. Nevertheless, this mechanism also renders nodes susceptible to the influence of their neighbors. For instance, this will occur when the neighboring nodes are imbalanced or the neighboring nodes contain noise, which can even affect the GNN's ability to generalize out of distribution. We find that ensuring the consistency of the norm for node representations can significantly reduce the impact of these two issues on GNNs. To this end, we propose a regularized optimization method called NodeReg that enforces the consistency of node representation norms. This method is simple but effective and satisfies Lipschitz continuity, thus facilitating stable optimization and significantly improving semi-supervised node classification performance under the above two scenarios. To illustrate, in the imbalance scenario, when training a GCN with an imbalance ratio of 0.1, NodeReg outperforms the most competitive baselines by 1.4%-25.9% in F1 score across five public datasets. Similarly, in the distribution shift scenario, NodeReg outperforms the most competitive baseline by 1.4%-3.1% in accuracy.
Category-free Out-of-Distribution Node Detection with Feature Resonance
Feb 22, 2025Detecting out-of-distribution (OOD) nodes in the graph-based machine-learning field is challenging, particularly when in-distribution (ID) node multi-category labels are unavailable. Thus, we focus on feature space rather than label space and find that, ideally, during the optimization of known ID samples, unknown ID samples undergo more significant representation changes than OOD samples, even if the model is trained to fit random targets, which we called the Feature Resonance phenomenon. The rationale behind it is that even without gold labels, the local manifold may still exhibit smooth resonance. Based on this, we further develop a novel graph OOD framework, dubbed Resonance-based Separation and Learning (RSL), which comprises two core modules: (i) a more practical micro-level proxy of feature resonance that measures the movement of feature vectors in one training step. (ii) integrate with synthetic OOD nodes strategy to train an effective OOD classifier. Theoretically, we derive an error bound showing the superior separability of OOD nodes during the resonance period. Empirically, RSL achieves state-of-the-art performance, reducing the FPR95 metric by an average of 18.51% across five real-world datasets.
Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance
Oct 16, 2024



Agents powered by large language models have shown remarkable abilities in solving complex tasks. However, most agent systems remain reactive, limiting their effectiveness in scenarios requiring foresight and autonomous decision-making. In this paper, we tackle the challenge of developing proactive agents capable of anticipating and initiating tasks without explicit human instructions. We propose a novel data-driven approach for this problem. Firstly, we collect real-world human activities to generate proactive task predictions. These predictions are then labeled by human annotators as either accepted or rejected. The labeled data is used to train a reward model that simulates human judgment and serves as an automatic evaluator of the proactiveness of LLM agents. Building on this, we develop a comprehensive data generation pipeline to create a diverse dataset, ProactiveBench, containing 6,790 events. Finally, we demonstrate that fine-tuning models with the proposed ProactiveBench can significantly elicit the proactiveness of LLM agents. Experimental results show that our fine-tuned model achieves an F1-Score of 66.47% in proactively offering assistance, outperforming all open-source and close-source models. These results highlight the potential of our method in creating more proactive and effective agent systems, paving the way for future advancements in human-agent collaboration.
Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
Jun 06, 2024Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectiveness\footnote{The code is available at \url{https://github.com/chen123CtrlS/EnhancingICL_SVDPruning}}.