 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded and Uniform Energy-based Out-of-distribution Detection for Graphs
Apr 18, 2025Given the critical role of graphs in real-world applications and their high-security requirements, improving the ability of graph neural networks (GNNs) to detect out-of-distribution (OOD) data is an urgent research problem. The recent work GNNSAFE proposes a framework based on the aggregation of negative energy scores that significantly improves the performance of GNNs to detect node-level OOD data. However, our study finds that score aggregation among nodes is susceptible to extreme values due to the unboundedness of the negative energy scores and logit shifts, which severely limits the accuracy of GNNs in detecting node-level OOD data. In this paper, we propose NODESAFE: reducing the generation of extreme scores of nodes by adding two optimization terms that make the negative energy scores bounded and mitigate the logit shift. Experimental results show that our approach dramatically improves the ability of GNNs to detect OOD data at the node level, e.g., in detecting OOD data induced by Structure Manipulation, the metric of FPR95 (lower is better) in scenarios without (with) OOD data exposure are reduced from the current SOTA by 28.4% (22.7%).
NodeReg: Mitigating the Imbalance and Distribution Shift Effects in Semi-Supervised Node Classification via Norm Consistency
Mar 05, 2025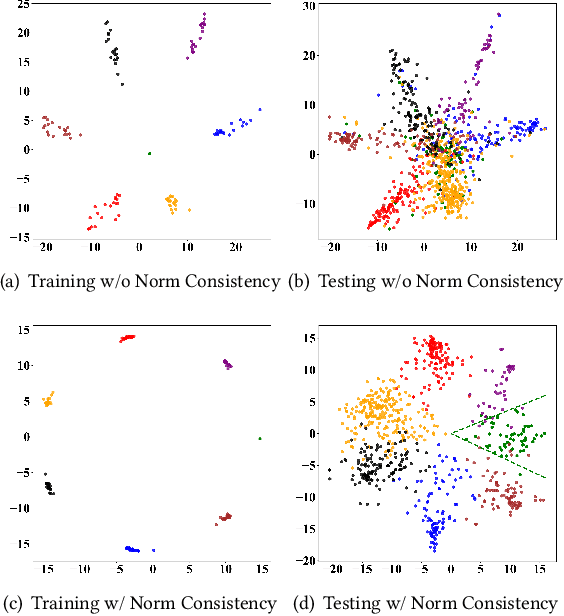



Aggregating information from neighboring nodes benefits graph neural networks (GNNs) in semi-supervised node classification tasks. Nevertheless, this mechanism also renders nodes susceptible to the influence of their neighbors. For instance, this will occur when the neighboring nodes are imbalanced or the neighboring nodes contain noise, which can even affect the GNN's ability to generalize out of distribution. We find that ensuring the consistency of the norm for node representations can significantly reduce the impact of these two issues on GNNs. To this end, we propose a regularized optimization method called NodeReg that enforces the consistency of node representation norms. This method is simple but effective and satisfies Lipschitz continuity, thus facilitating stable optimization and significantly improving semi-supervised node classification performance under the above two scenarios. To illustrate, in the imbalance scenario, when training a GCN with an imbalance ratio of 0.1, NodeReg outperforms the most competitive baselines by 1.4%-25.9% in F1 score across five public datasets. Similarly, in the distribution shift scenario, NodeReg outperforms the most competitive baseline by 1.4%-3.1% in accuracy.