 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Noise Steering for Efficient Human-Guided VLA Adaptation
May 11, 2026Diffusion-based vision-language-action (VLA) models have emerged as strong priors for robotic manipulation, yet adapting them to real-world distributions remains challenging. In particular, on-robot reinforcement learning (RL) is expensive and time-consuming, so effective adaptation depends on efficient policy improvement within a limited budget of real-world interactions. Noise-space RL lowers the cost by keeping the pretrained VLA fixed as a denoising generator while updating only a lightweight actor that predicts the noise. However, its performance is still limited due to inefficient autonomous exploration. Human corrective interventions can reduce this exploration burden, but they are naturally provided in action space, whereas noise-space finetuning requires supervision over noise variables. To address these challenges, we propose UniSteer, a Unified Noise Steering framework that combines human corrective guidance with noise-space RL through approximate action-to-noise inversion. Given a human corrective action, UniSteer inverts the frozen flow-matching decoder to recover a noise target, which provides supervised guidance for the same noise actor that is simultaneously optimized via reinforcement learning. Real-world experiments on diverse manipulation tasks show that UniSteer adapts more efficiently than strong noise-space RL and action-space human-in-the-loop baselines, improving the success rate from 20% to 90% in 66 minutes on average across four real-world adaptation tasks.
Transferring Physical Priors into Remote Sensing Segmentation via Large Language Models
Mar 29, 2026Semantic segmentation of remote sensing imagery is fundamental to Earth observation. Achieving accurate results requires integrating not only optical images but also physical variables such as the Digital Elevation Model (DEM), Synthetic Aperture Radar (SAR) and Normalized Difference Vegetation Index (NDVI). Recent foundation models (FMs) leverage pre-training to exploit these variables but still depend on spatially aligned data and costly retraining when involving new sensors. To overcome these limitations, we introduce a novel paradigm for integrating domain-specific physical priors into segmentation models. We first construct a Physical-Centric Knowledge Graph (PCKG) by prompting large language models to extract physical priors from 1,763 vocabularies, and use it to build a heterogeneous, spatial-aligned dataset, Phy-Sky-SA. Building on this foundation, we develop PriorSeg, a physics-aware residual refinement model trained with a joint visual-physical strategy that incorporates a novel physics-consistency loss. Experiments on heterogeneous settings demonstrate that PriorSeg improves segmentation accuracy and physical plausibility without retraining the FMs. Ablation studies verify the effectiveness of the Phy-Sky-SA dataset, the PCKG, and the physics-consistency loss.
Interference-Aware K-Step Reachable Communication in Multi-Agent Reinforcement Learning
Mar 16, 2026Effective communication is pivotal for addressing complex collaborative tasks in multi-agent reinforcement learning (MARL). Yet, limited communication bandwidth and dynamic, intricate environmental topologies present significant challenges in identifying high-value communication partners. Agents must consequently select collaborators under uncertainty, lacking a priori knowledge of which partners can deliver task-critical information. To this end, we propose Interference-Aware K-Step Reachable Communication (IA-KRC), a novel framework that enhances cooperation via two core components: (1) a K-Step reachability protocol that confines message passing to physically accessible neighbors, and (2) an interference-prediction module that optimizes partner choice by minimizing interference while maximizing utility. Compared to existing methods, IA-KRC enables substantially more persistent and efficient cooperation despite environmental interference. Comprehensive evaluations confirm that IA-KRC achieves superior performance compared to state-of-the-art baselines, while demonstrating enhanced robustness and scalability in complex topological and highly dynamic multi-agent scenarios.
Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
Jan 22, 2026Large language models (LLMs) can call tools effectively, yet they remain brittle in multi-turn execution: following a tool call error, smaller models often degenerate into repetitive invalid re-invocations, failing to interpret error feedback and self-correct. This brittleness hinders reliable real-world deployment, where the execution errors are inherently inevitable during tool interaction procedures. We identify a key limitation of current approaches: standard reinforcement learning (RL) treats errors as sparse negative rewards, providing no guidance on how to recover, while pre-collected synthetic error-correction datasets suffer from distribution mismatch with the model's on-policy error modes. To bridge this gap, we propose Fission-GRPO, a framework that converts execution errors into corrective supervision within the RL training loop. Our core mechanism fissions each failed trajectory into a new training instance by augmenting it with diagnostic feedback from a finetuned Error Simulator, then resampling recovery rollouts on-policy. This enables the model to learn from the precise errors it makes during exploration, rather than from static, pre-collected error cases. On the BFCL v4 Multi-Turn, Fission-GRPO improves the error recovery rate of Qwen3-8B by 5.7% absolute, crucially, yielding a 4% overall accuracy gain (42.75% to 46.75%) over GRPO and outperforming specialized tool-use agents.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Robust and High-Fidelity 3D Gaussian Splatting: Fusing Pose Priors and Geometry Constraints for Texture-Deficient Outdoor Scenes
Nov 10, 20253D Gaussian Splatting (3DGS) has emerged as a key rendering pipeline for digital asset creation due to its balance between efficiency and visual quality. To address the issues of unstable pose estimation and scene representation distortion caused by geometric texture inconsistency in large outdoor scenes with weak or repetitive textures, we approach the problem from two aspects: pose estimation and scene representation. For pose estimation, we leverage LiDAR-IMU Odometry to provide prior poses for cameras in large-scale environments. These prior pose constraints are incorporated into COLMAP's triangulation process, with pose optimization performed via bundle adjustment. Ensuring consistency between pixel data association and prior poses helps maintain both robustness and accuracy. For scene representation, we introduce normal vector constraints and effective rank regularization to enforce consistency in the direction and shape of Gaussian primitives. These constraints are jointly optimized with the existing photometric loss to enhance the map quality. We evaluate our approach using both public and self-collected datasets. In terms of pose optimization, our method requires only one-third of the time while maintaining accuracy and robustness across both datasets. In terms of scene representation, the results show that our method significantly outperforms conventional 3DGS pipelines. Notably, on self-collected datasets characterized by weak or repetitive textures, our approach demonstrates enhanced visualization capabilities and achieves superior overall performance. Codes and data will be publicly available at https://github.com/justinyeah/normal_shape.git.
Semi-distributed Cross-modal Air-Ground Relative Localization
Nov 10, 2025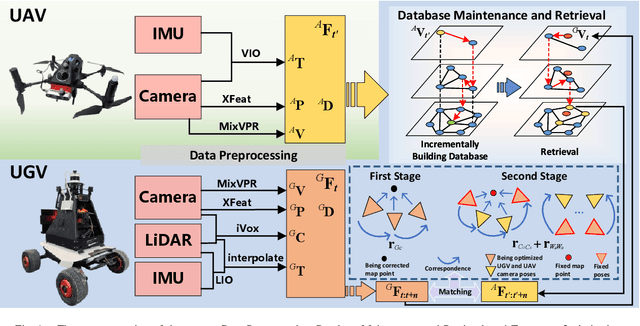
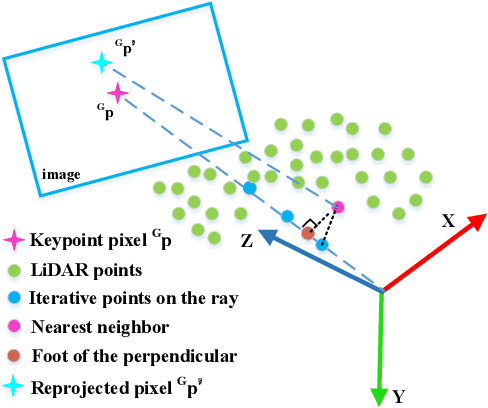

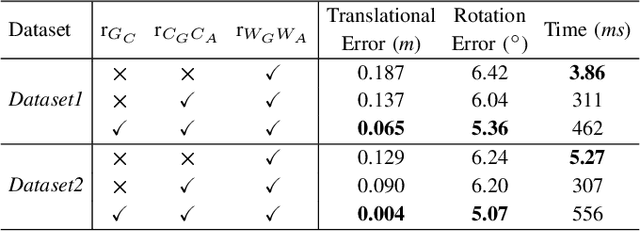
Efficient, accurate, and flexible relative localization is crucial in air-ground collaborative tasks. However, current approaches for robot relative localization are primarily realized in the form of distributed multi-robot SLAM systems with the same sensor configuration, which are tightly coupled with the state estimation of all robots, limiting both flexibility and accuracy. To this end, we fully leverage the high capacity of Unmanned Ground Vehicle (UGV) to integrate multiple sensors, enabling a semi-distributed cross-modal air-ground relative localization framework. In this work, both the UGV and the Unmanned Aerial Vehicle (UAV) independently perform SLAM while extracting deep learning-based keypoints and global descriptors, which decouples the relative localization from the state estimation of all agents. The UGV employs a local Bundle Adjustment (BA) with LiDAR, camera, and an IMU to rapidly obtain accurate relative pose estimates. The BA process adopts sparse keypoint optimization and is divided into two stages: First, optimizing camera poses interpolated from LiDAR-Inertial Odometry (LIO), followed by estimating the relative camera poses between the UGV and UAV. Additionally, we implement an incremental loop closure detection algorithm using deep learning-based descriptors to maintain and retrieve keyframes efficiently. Experimental results demonstrate that our method achieves outstanding performance in both accuracy and efficiency. Unlike traditional multi-robot SLAM approaches that transmit images or point clouds, our method only transmits keypoint pixels and their descriptors, effectively constraining the communication bandwidth under 0.3 Mbps. Codes and data will be publicly available on https://github.com/Ascbpiac/cross-model-relative-localization.git.
ReMoD: Rethinking Modality Contribution in Multimodal Stance Detection via Dual Reasoning
Nov 08, 2025Multimodal Stance Detection (MSD) is a crucial task for understanding public opinion on social media. Existing work simply fuses information from various modalities to learn stance representations, overlooking the varying contributions of stance expression from different modalities. Therefore, stance misunderstanding noises may be drawn into the stance learning process due to the risk of learning errors by rough modality combination. To address this, we get inspiration from the dual-process theory of human cognition and propose **ReMoD**, a framework that **Re**thinks **Mo**dality contribution of stance expression through a **D**ual-reasoning paradigm. ReMoD integrates *experience-driven intuitive reasoning* to capture initial stance cues with *deliberate reflective reasoning* to adjust for modality biases, refine stance judgments, and thereby dynamically weight modality contributions based on their actual expressive power for the target stance. Specifically, the intuitive stage queries the Modality Experience Pool (MEP) and Semantic Experience Pool (SEP) to form an initial stance hypothesis, prioritizing historically impactful modalities. This hypothesis is then refined in the reflective stage via two reasoning chains: Modality-CoT updates MEP with adaptive fusion strategies to amplify relevant modalities, while Semantic-CoT refines SEP with deeper contextual insights of stance semantics. These dual experience structures are continuously refined during training and recalled at inference to guide robust and context-aware stance decisions. Extensive experiments on the public MMSD benchmark demonstrate that our ReMoD significantly outperforms most baseline models and exhibits strong generalization capabilities.
Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
Oct 06, 2025As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.
ReSURE: Regularizing Supervision Unreliability for Multi-turn Dialogue Fine-tuning
Aug 27, 2025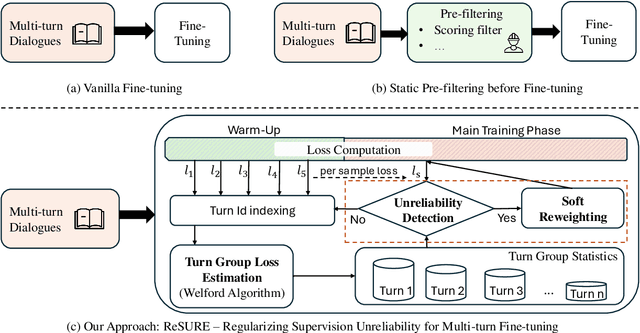
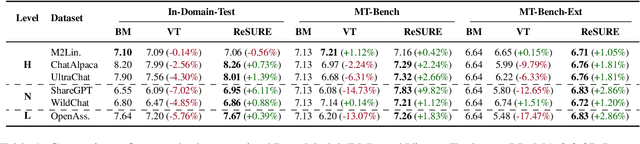
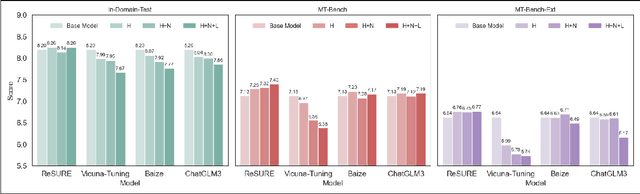
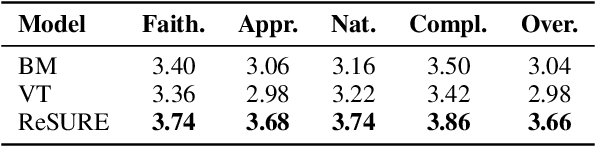
Fine-tuning multi-turn dialogue systems requires high-quality supervision but often suffers from degraded performance when exposed to low-quality data. Supervision errors in early turns can propagate across subsequent turns, undermining coherence and response quality. Existing methods typically address data quality via static prefiltering, which decouples quality control from training and fails to mitigate turn-level error propagation. In this context, we propose ReSURE (Regularizing Supervision UnREliability), an adaptive learning method that dynamically down-weights unreliable supervision without explicit filtering. ReSURE estimates per-turn loss distributions using Welford's online statistics and reweights sample losses on the fly accordingly. Experiments on both single-source and mixed-quality datasets show improved stability and response quality. Notably, ReSURE enjoys positive Spearman correlations (0.21 ~ 1.0 across multiple benchmarks) between response scores and number of samples regardless of data quality, which potentially paves the way for utilizing large-scale data effectively. Code is publicly available at https://github.com/Elvin-Yiming-Du/ReSURE_Multi_Turn_Training.