 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflectRM: Boosting Generative Reward Models via Self-Reflection within a Unified Judgment Framework
Apr 08, 2026Reward Models (RMs) are critical components in the Reinforcement Learning from Human Feedback (RLHF) pipeline, directly determining the alignment quality of Large Language Models (LLMs). Recently, Generative Reward Models (GRMs) have emerged as a superior paradigm, offering higher interpretability and stronger generalization than traditional scalar RMs. However, existing methods for GRMs focus primarily on outcome-level supervision, neglecting analytical process quality, which constrains their potential. To address this, we propose ReflectRM, a novel GRM that leverages self-reflection to assess analytical quality and enhance preference modeling. ReflectRM is trained under a unified generative framework for joint modeling of response preference and analysis preference. During inference, we use its self-reflection capability to identify the most reliable analysis, from which the final preference prediction is derived. Experiments across four benchmarks show that ReflectRM consistently improves performance, achieving an average accuracy gain of +3.7 on Qwen3-4B. Further experiments confirm that response preference and analysis preference are mutually reinforcing. Notably, ReflectRM substantially mitigates positional bias, yielding +10.2 improvement compared with leading GRMs and establishing itself as a more stable evaluator.
Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
Oct 06, 2025As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.
Reinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
May 24, 2025Standing in 2025, at a critical juncture in the pursuit of Artificial General Intelligence (AGI), reinforcement fine-tuning (RFT) has demonstrated significant potential in enhancing the reasoning capability of large language models (LLMs) and has led to the development of cutting-edge AI models such as OpenAI-o1 and DeepSeek-R1. Moreover, the efficient application of RFT to enhance the reasoning capability of multimodal large language models (MLLMs) has attracted widespread attention from the community. In this position paper, we argue that reinforcement fine-tuning powers the reasoning capability of multimodal large language models. To begin with, we provide a detailed introduction to the fundamental background knowledge that researchers interested in this field should be familiar with. Furthermore, we meticulously summarize the improvements of RFT in powering reasoning capability of MLLMs into five key points: diverse modalities, diverse tasks and domains, better training algorithms, abundant benchmarks and thriving engineering frameworks. Finally, we propose five promising directions for future research that the community might consider. We hope that this position paper will provide valuable insights to the community at this pivotal stage in the advancement toward AGI. Summary of works done on RFT for MLLMs is available at https://github.com/Sun-Haoyuan23/Awesome-RL-based-Reasoning-MLLMs.
Deep Adaptive Network: An Efficient Deep Neural Network with Sparse Binary Connections
Apr 21, 2016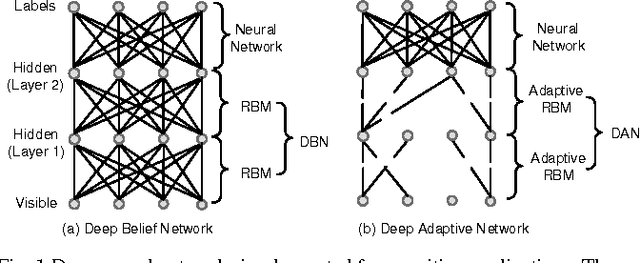
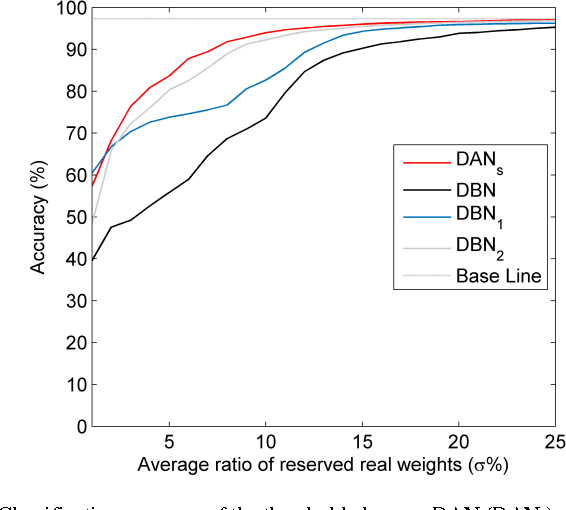
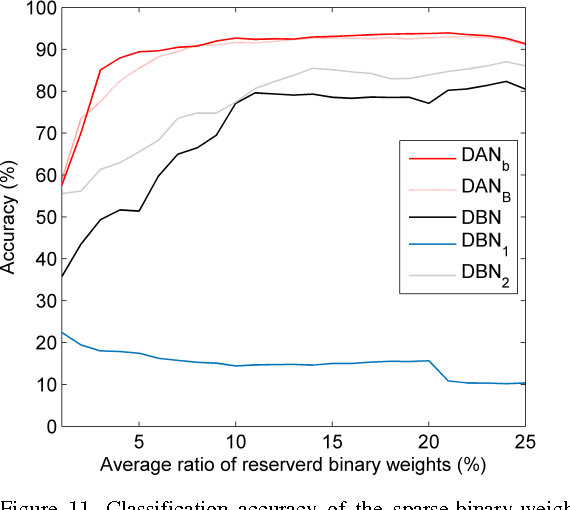
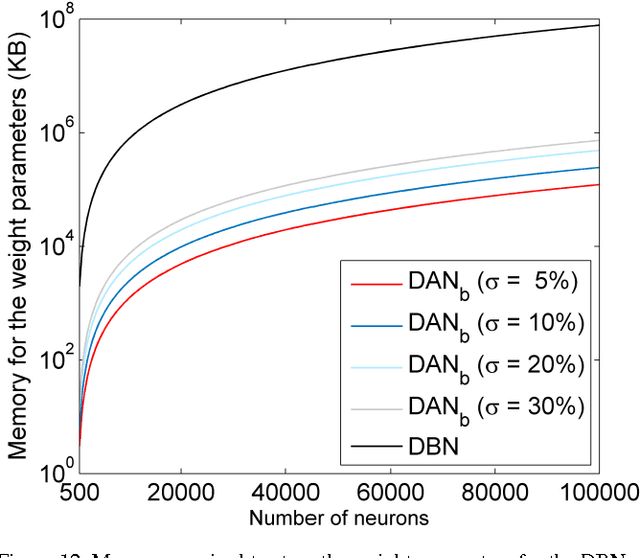
Deep neural networks are state-of-the-art models for understanding the content of images, video and raw input data. However, implementing a deep neural network in embedded systems is a challenging task, because a typical deep neural network, such as a Deep Belief Network using 128x128 images as input, could exhaust Giga bytes of memory and result in bandwidth and computing bottleneck. To address this challenge, this paper presents a hardware-oriented deep learning algorithm, named as the Deep Adaptive Network, which attempts to exploit the sparsity in the neural connections. The proposed method adaptively reduces the weights associated with negligible features to zero, leading to sparse feedforward network architecture. Furthermore, since the small proportion of important weights are significantly larger than zero, they can be robustly thresholded and represented using single-bit integers (-1 and +1), leading to implementations of deep neural networks with sparse and binary connections. Our experiments showed that, for the application of recognizing MNIST handwritten digits, the features extracted by a two-layer Deep Adaptive Network with about 25% reserved important connections achieved 97.2% classification accuracy, which was almost the same with the standard Deep Belief Network (97.3%). Furthermore, for efficient hardware implementations, the sparse-and-binary-weighted deep neural network could save about 99.3% memory and 99.9% computation units without significant loss of classification accuracy for pattern recognition applications.