 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
May 24, 2025Standing in 2025, at a critical juncture in the pursuit of Artificial General Intelligence (AGI), reinforcement fine-tuning (RFT) has demonstrated significant potential in enhancing the reasoning capability of large language models (LLMs) and has led to the development of cutting-edge AI models such as OpenAI-o1 and DeepSeek-R1. Moreover, the efficient application of RFT to enhance the reasoning capability of multimodal large language models (MLLMs) has attracted widespread attention from the community. In this position paper, we argue that reinforcement fine-tuning powers the reasoning capability of multimodal large language models. To begin with, we provide a detailed introduction to the fundamental background knowledge that researchers interested in this field should be familiar with. Furthermore, we meticulously summarize the improvements of RFT in powering reasoning capability of MLLMs into five key points: diverse modalities, diverse tasks and domains, better training algorithms, abundant benchmarks and thriving engineering frameworks. Finally, we propose five promising directions for future research that the community might consider. We hope that this position paper will provide valuable insights to the community at this pivotal stage in the advancement toward AGI. Summary of works done on RFT for MLLMs is available at https://github.com/Sun-Haoyuan23/Awesome-RL-based-Reasoning-MLLMs.
MM-Eval: A Hierarchical Benchmark for Modern Mongolian Evaluation in LLMs
Nov 14, 2024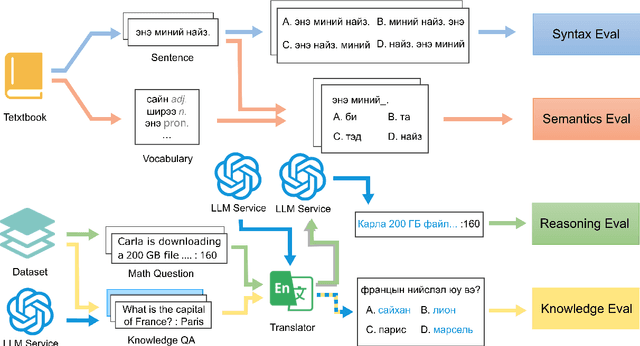
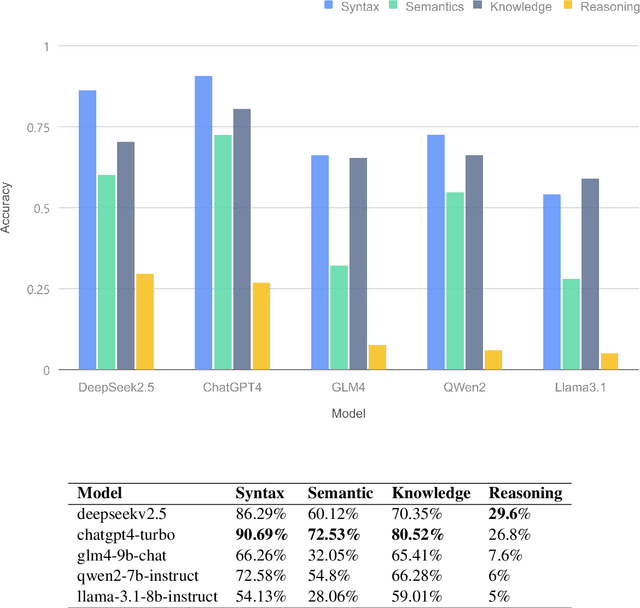
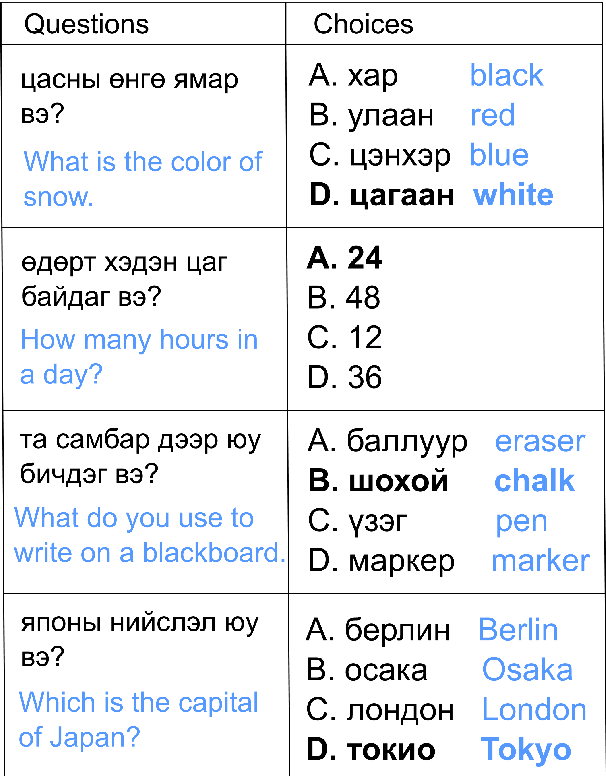
Large language models (LLMs) excel in high-resource languages but face notable challenges in low-resource languages like Mongolian. This paper addresses these challenges by categorizing capabilities into language abilities (syntax and semantics) and cognitive abilities (knowledge and reasoning). To systematically evaluate these areas, we developed MM-Eval, a specialized dataset based on Modern Mongolian Language Textbook I and enriched with WebQSP and MGSM datasets. Preliminary experiments on models including Qwen2-7B-Instruct, GLM4-9b-chat, Llama3.1-8B-Instruct, GPT-4, and DeepseekV2.5 revealed that: 1) all models performed better on syntactic tasks than semantic tasks, highlighting a gap in deeper language understanding; and 2) knowledge tasks showed a moderate decline, suggesting that models can transfer general knowledge from high-resource to low-resource contexts. The release of MM-Eval, comprising 569 syntax, 677 semantics, 344 knowledge, and 250 reasoning tasks, offers valuable insights for advancing NLP and LLMs in low-resource languages like Mongolian. The dataset is available at https://github.com/joenahm/MM-Eval.
Generalizing Alignment Paradigm of Text-to-Image Generation with Preferences through $f$-divergence Minimization
Sep 15, 2024
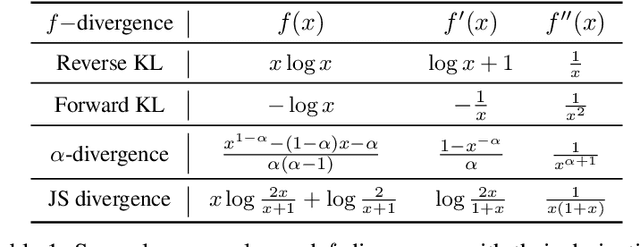
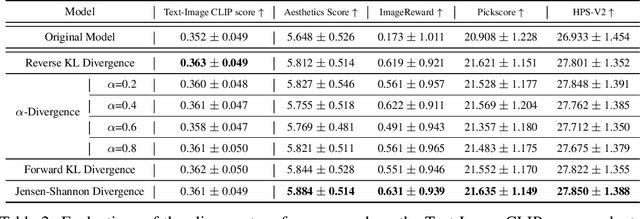
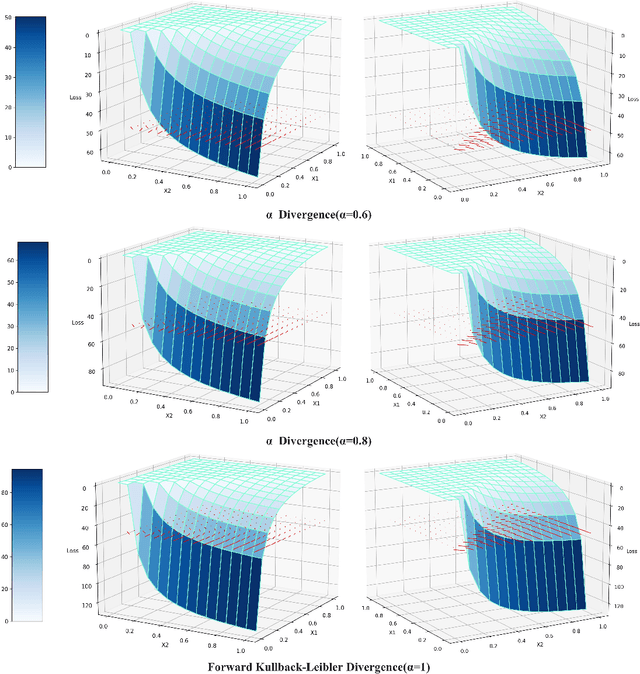
Direct Preference Optimization (DPO) has recently expanded its successful application from aligning large language models (LLMs) to aligning text-to-image models with human preferences, which has generated considerable interest within the community. However, we have observed that these approaches rely solely on minimizing the reverse Kullback-Leibler divergence during alignment process between the fine-tuned model and the reference model, neglecting the incorporation of other divergence constraints. In this study, we focus on extending reverse Kullback-Leibler divergence in the alignment paradigm of text-to-image models to $f$-divergence, which aims to garner better alignment performance as well as good generation diversity. We provide the generalized formula of the alignment paradigm under the $f$-divergence condition and thoroughly analyze the impact of different divergence constraints on alignment process from the perspective of gradient fields. We conduct comprehensive evaluation on image-text alignment performance, human value alignment performance and generation diversity performance under different divergence constraints, and the results indicate that alignment based on Jensen-Shannon divergence achieves the best trade-off among them. The option of divergence employed for aligning text-to-image models significantly impacts the trade-off between alignment performance (especially human value alignment) and generation diversity, which highlights the necessity of selecting an appropriate divergence for practical applications.
Trajectory Planning for Teleoperated Space Manipulators Using Deep Reinforcement Learning
Aug 10, 2024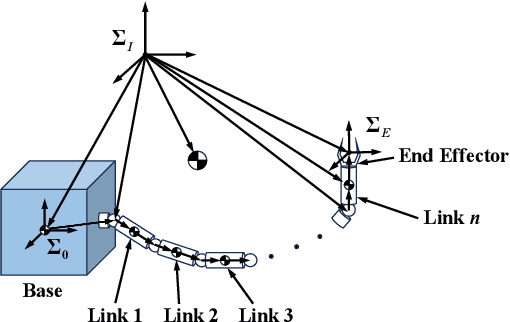
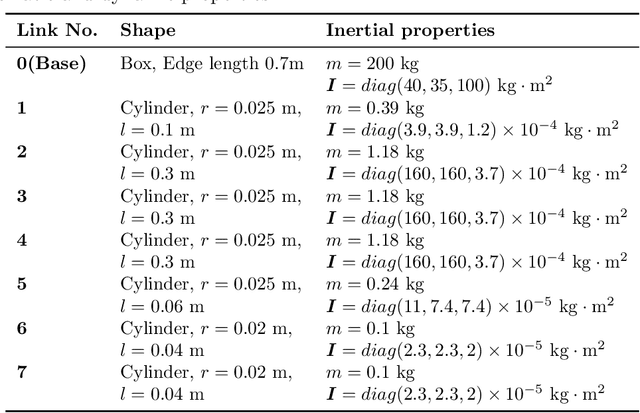
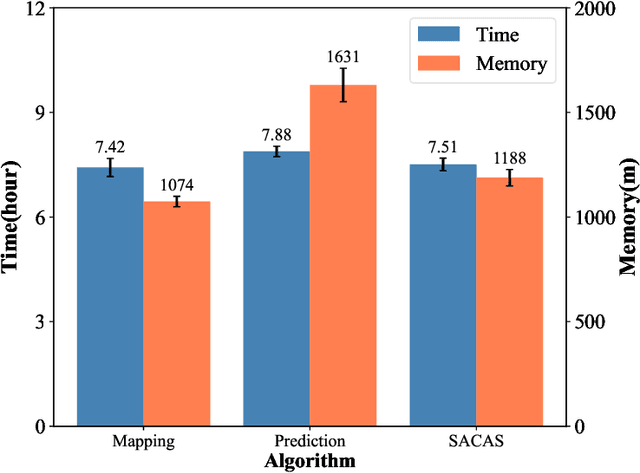
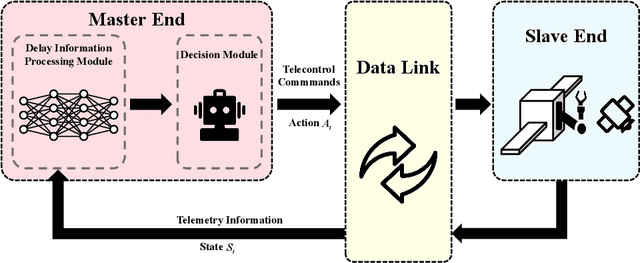
Trajectory planning for teleoperated space manipulators involves challenges such as accurately modeling system dynamics, particularly in free-floating modes with non-holonomic constraints, and managing time delays that increase model uncertainty and affect control precision. Traditional teleoperation methods rely on precise dynamic models requiring complex parameter identification and calibration, while data-driven methods do not require prior knowledge but struggle with time delays. A novel framework utilizing deep reinforcement learning (DRL) is introduced to address these challenges. The framework incorporates three methods: Mapping, Prediction, and State Augmentation, to handle delays when delayed state information is received at the master end. The Soft Actor Critic (SAC) algorithm processes the state information to compute the next action, which is then sent to the remote manipulator for environmental interaction. Four environments are constructed using the MuJoCo simulation platform to account for variations in base and target fixation: fixed base and target, fixed base with rotated target, free-floating base with fixed target, and free-floating base with rotated target. Extensive experiments with both constant and random delays are conducted to evaluate the proposed methods. Results demonstrate that all three methods effectively address trajectory planning challenges, with State Augmentation showing superior efficiency and robustness.
DEER: A Delay-Resilient Framework for Reinforcement Learning with Variable Delays
Jun 05, 2024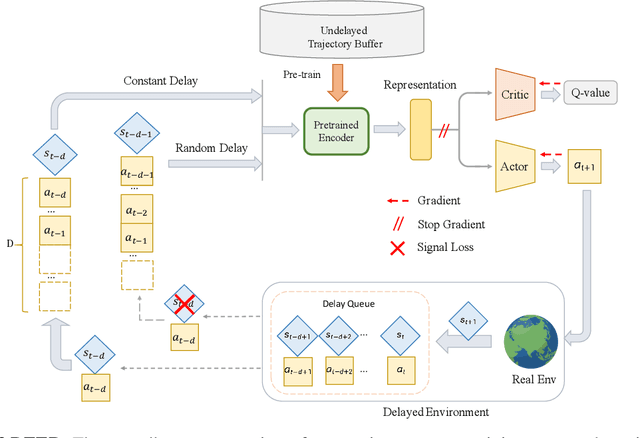
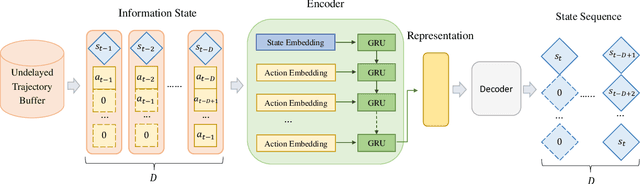
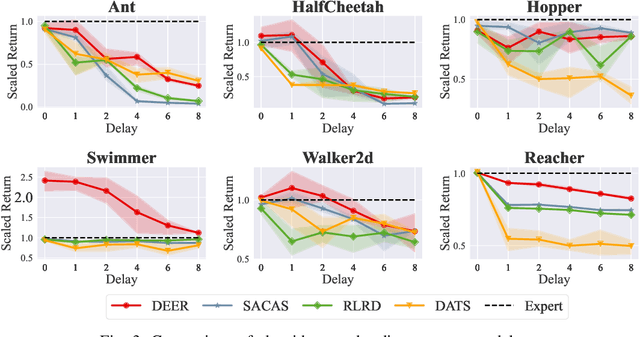
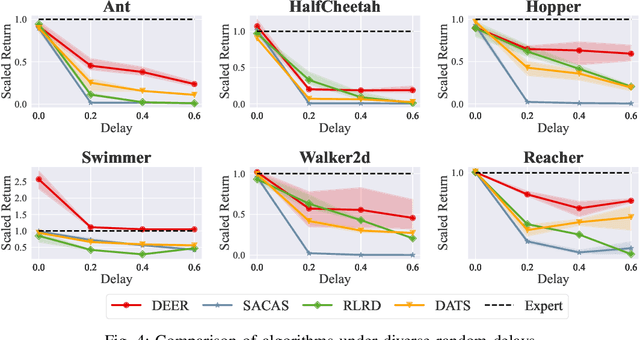
Classic reinforcement learning (RL) frequently confronts challenges in tasks involving delays, which cause a mismatch between received observations and subsequent actions, thereby deviating from the Markov assumption. Existing methods usually tackle this issue with end-to-end solutions using state augmentation. However, these black-box approaches often involve incomprehensible processes and redundant information in the information states, causing instability and potentially undermining the overall performance. To alleviate the delay challenges in RL, we propose $\textbf{DEER (Delay-resilient Encoder-Enhanced RL)}$, a framework designed to effectively enhance the interpretability and address the random delay issues. DEER employs a pretrained encoder to map delayed states, along with their variable-length past action sequences resulting from different delays, into hidden states, which is trained on delay-free environment datasets. In a variety of delayed scenarios, the trained encoder can seamlessly integrate with standard RL algorithms without requiring additional modifications and enhance the delay-solving capability by simply adapting the input dimension of the original algorithms. We evaluate DEER through extensive experiments on Gym and Mujoco environments. The results confirm that DEER is superior to state-of-the-art RL algorithms in both constant and random delay settings.
A Method on Searching Better Activation Functions
May 22, 2024



The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
Don't Touch What Matters: Task-Aware Lipschitz Data Augmentation for Visual Reinforcement Learning
Feb 22, 2022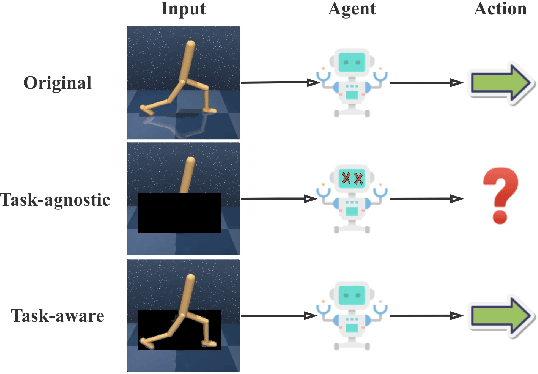
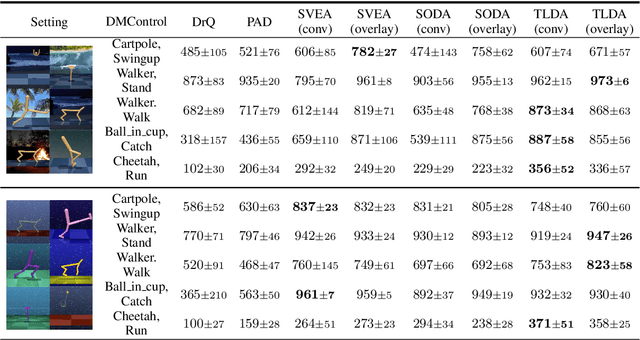
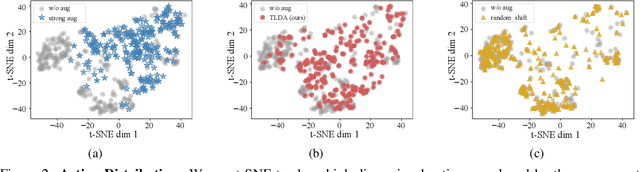
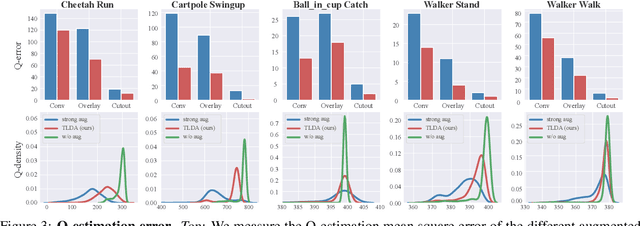
One of the key challenges in visual Reinforcement Learning (RL) is to learn policies that can generalize to unseen environments. Recently, data augmentation techniques aiming at enhancing data diversity have demonstrated proven performance in improving the generalization ability of learned policies. However, due to the sensitivity of RL training, naively applying data augmentation, which transforms each pixel in a task-agnostic manner, may suffer from instability and damage the sample efficiency, thus further exacerbating the generalization performance. At the heart of this phenomenon is the diverged action distribution and high-variance value estimation in the face of augmented images. To alleviate this issue, we propose Task-aware Lipschitz Data Augmentation (TLDA) for visual RL, which explicitly identifies the task-correlated pixels with large Lipschitz constants, and only augments the task-irrelevant pixels. To verify the effectiveness of TLDA, we conduct extensive experiments on DeepMind Control suite, CARLA and DeepMind Manipulation tasks, showing that TLDA improves both sample efficiency in training time and generalization in test time. It outperforms previous state-of-the-art methods across the 3 different visual control benchmarks.