 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering Catastrophic Forgetting of Large Language Models for Better Instruction Following via Weight-Space Model Merging
Apr 02, 2026Large language models have been adopted in the medical domain for clinical documentation to reduce clinician burden. However, studies have reported that LLMs often "forget" a significant amount of instruction-following ability when fine-tuned using a task-specific medical dataset, a critical challenge in adopting general-purpose LLMs for clinical applications. This study presents a model merging framework to efficiently adapt general-purpose LLMs to the medical domain by countering this forgetting issue. By merging a clinical foundation model (GatorTronLlama) with a general instruct model (Llama-3.1-8B-Instruct) via interpolation-based merge methods, we seek to derive a domain-adapted model with strong performance on clinical tasks while retaining instruction-following ability. Comprehensive evaluation across medical benchmarks and five clinical generation tasks (e.g., radiology and discharge summarization) shows that merged models can effectively mitigate catastrophic forgetting, preserve clinical domain expertise, and retain instruction-following ability. In addition, our model merging strategies demonstrate training efficiency, achieving performance on par with fully fine-tuned baselines under severely constrained supervision (e.g., 64-shot vs. 256-shot). Consequently, weight-space merging constitutes a highly scalable solution for adapting open-source LLMs to clinical applications, facilitating broader deployment in resource-constrained healthcare environments.
NeuroWise: A Multi-Agent LLM "Glass-Box" System for Practicing Double-Empathy Communication with Autistic Partners
Feb 21, 2026The double empathy problem frames communication difficulties between neurodivergent and neurotypical individuals as arising from mutual misunderstanding, yet most interventions focus on autistic individuals. We present NeuroWise, a multi-agent LLM-based coaching system that supports neurotypical users through stress visualization, interpretation of internal experiences, and contextual guidance. In a between-subjects study (N=30), NeuroWise was rated as helpful by all participants and showed a significant condition-time effect on deficit-based attributions (p=0.02): NeuroWise users reduced deficit framing, while baseline users shifted toward blaming autistic "deficits" after difficult interactions. NeuroWise users also completed conversations more efficiently (37% fewer turns, p=0.03). These findings suggest that AI-based interpretation can support attributional change by helping users recognize communication challenges as mutual.
FutureMind: Equipping Small Language Models with Strategic Thinking-Pattern Priors via Adaptive Knowledge Distillation
Feb 01, 2026Small Language Models (SLMs) are attractive for cost-sensitive and resource-limited settings due to their efficient, low-latency inference. However, they often struggle with complex, knowledge-intensive tasks that require structured reasoning and effective retrieval. To address these limitations, we propose FutureMind, a modular reasoning framework that equips SLMs with strategic thinking-pattern priors via adaptive knowledge distillation from large language models (LLMs). FutureMind introduces a dynamic reasoning pipeline composed of four key modules: Problem Analysis, Logical Reasoning, Strategy Planning, and Retrieval Guidance. This pipeline is augmented by three distinct retrieval paradigms that decompose complex queries into tractable subproblems, ensuring efficient and accurate retrieval execution. Extensive experiments on multi-hop QA benchmarks, including 2WikiMultihopQA, MuSiQue, Bamboogle, and Frames, demonstrate the superiority of FutureMind. It consistently outperforms strong baselines such as Search-o1, achieving state-of-the-art results under free training conditions across diverse SLM architectures and scales. Beyond empirical gains, our analysis reveals that the process of thinking-pattern distillation is restricted by the cognitive bias bottleneck between the teacher (LLMs) and student (SLMs) models. This provides new perspectives on the transferability of reasoning skills, paving the way for the development of SLMs that combine efficiency with genuine cognitive capability.
MM-Eval: A Hierarchical Benchmark for Modern Mongolian Evaluation in LLMs
Nov 14, 2024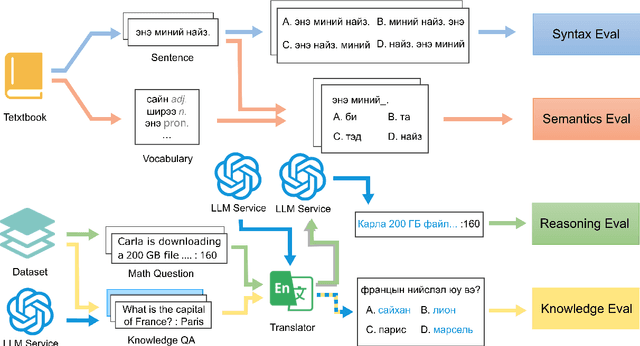
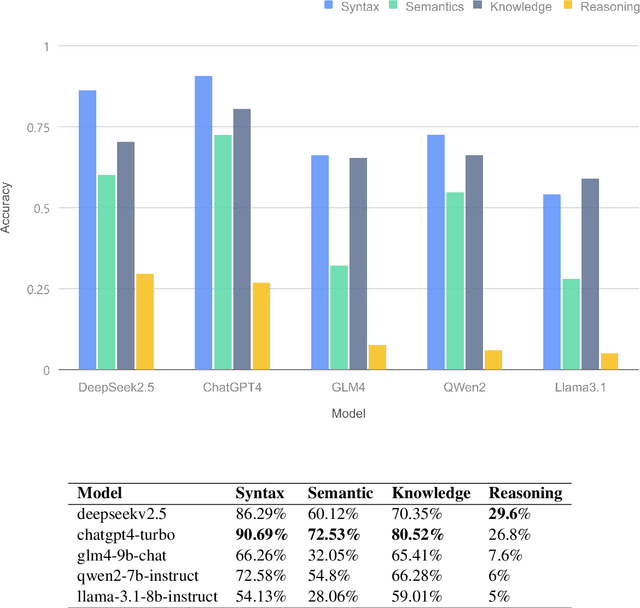
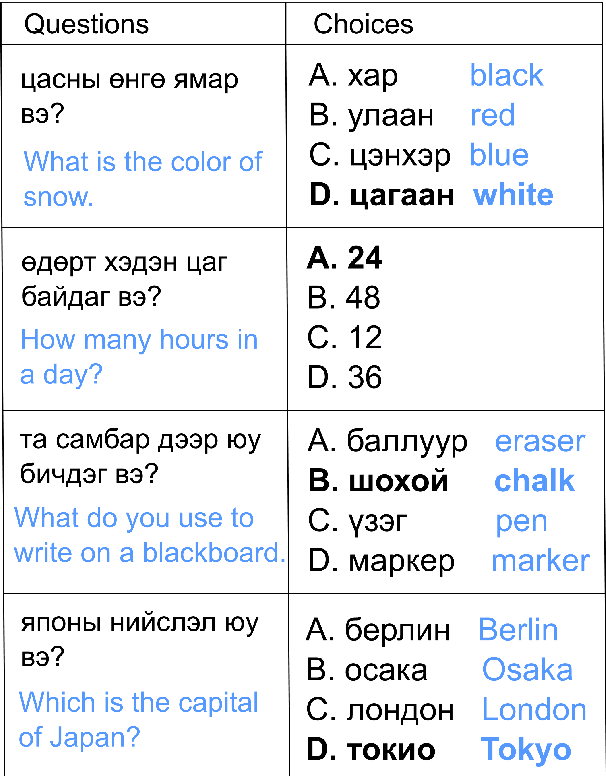
Large language models (LLMs) excel in high-resource languages but face notable challenges in low-resource languages like Mongolian. This paper addresses these challenges by categorizing capabilities into language abilities (syntax and semantics) and cognitive abilities (knowledge and reasoning). To systematically evaluate these areas, we developed MM-Eval, a specialized dataset based on Modern Mongolian Language Textbook I and enriched with WebQSP and MGSM datasets. Preliminary experiments on models including Qwen2-7B-Instruct, GLM4-9b-chat, Llama3.1-8B-Instruct, GPT-4, and DeepseekV2.5 revealed that: 1) all models performed better on syntactic tasks than semantic tasks, highlighting a gap in deeper language understanding; and 2) knowledge tasks showed a moderate decline, suggesting that models can transfer general knowledge from high-resource to low-resource contexts. The release of MM-Eval, comprising 569 syntax, 677 semantics, 344 knowledge, and 250 reasoning tasks, offers valuable insights for advancing NLP and LLMs in low-resource languages like Mongolian. The dataset is available at https://github.com/joenahm/MM-Eval.
Hybrid Classification-Regression Adaptive Loss for Dense Object Detection
Aug 30, 2024



For object detection detectors, enhancing model performance hinges on the ability to simultaneously consider inconsistencies across tasks and focus on difficult-to-train samples. Achieving this necessitates incorporating information from both the classification and regression tasks. However, prior work tends to either emphasize difficult-to-train samples within their respective tasks or simply compute classification scores with IoU, often leading to suboptimal model performance. In this paper, we propose a Hybrid Classification-Regression Adaptive Loss, termed as HCRAL. Specifically, we introduce the Residual of Classification and IoU (RCI) module for cross-task supervision, addressing task inconsistencies, and the Conditioning Factor (CF) to focus on difficult-to-train samples within each task. Furthermore, we introduce a new strategy named Expanded Adaptive Training Sample Selection (EATSS) to provide additional samples that exhibit classification and regression inconsistencies. To validate the effectiveness of the proposed method, we conduct extensive experiments on COCO test-dev. Experimental evaluations demonstrate the superiority of our approachs. Additionally, we designed experiments by separately combining the classification and regression loss with regular loss functions in popular one-stage models, demonstrating improved performance.
Narrative Feature or Structured Feature? A Study of Large Language Models to Identify Cancer Patients at Risk of Heart Failure
Mar 18, 2024


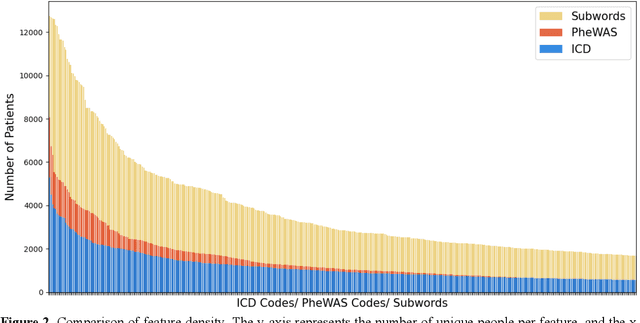
Cancer treatments are known to introduce cardiotoxicity, negatively impacting outcomes and survivorship. Identifying cancer patients at risk of heart failure (HF) is critical to improving cancer treatment outcomes and safety. This study examined machine learning (ML) models to identify cancer patients at risk of HF using electronic health records (EHRs), including traditional ML, Time-Aware long short-term memory (T-LSTM), and large language models (LLMs) using novel narrative features derived from the structured medical codes. We identified a cancer cohort of 12,806 patients from the University of Florida Health, diagnosed with lung, breast, and colorectal cancers, among which 1,602 individuals developed HF after cancer. The LLM, GatorTron-3.9B, achieved the best F1 scores, outperforming the traditional support vector machines by 39%, the T-LSTM deep learning model by 7%, and a widely used transformer model, BERT, by 5.6%. The analysis shows that the proposed narrative features remarkably increased feature density and improved performance.
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Jan 28, 2024The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. The code and more results are available at our project website:https://freestylefreelunch.github.io/.
On Regularized Sparse Logistic Regression
Sep 12, 2023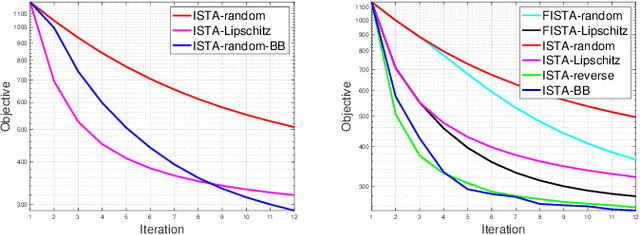
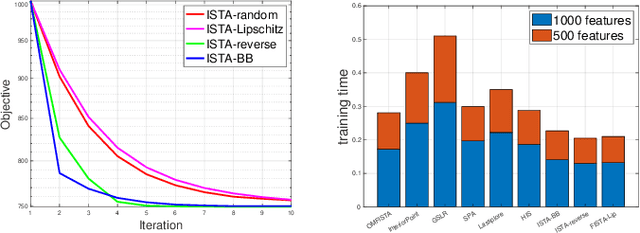
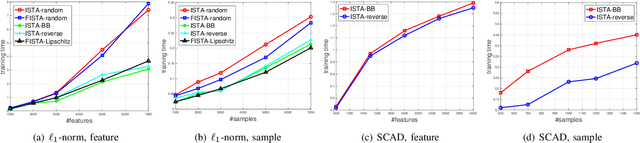
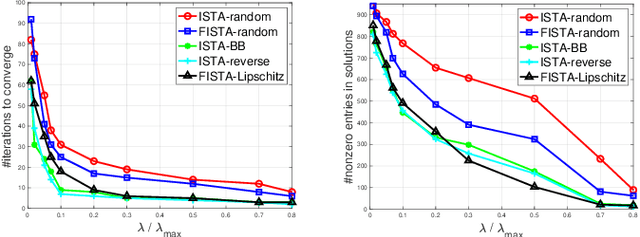
Sparse logistic regression aims to perform classification and feature selection simultaneously for high-dimensional data. Although many studies have been done to solve $\ell_1$-regularized logistic regression, there is no equivalently abundant literature about solving sparse logistic regression associated with nonconvex penalties. In this paper, we propose to solve $\ell_1$-regularized sparse logistic regression and some nonconvex penalties-regularized sparse logistic regression, when the nonconvex penalties satisfy some prerequisites, with similar optimization frameworks. In the proposed optimization frameworks, we utilize different line search criteria to guarantee good convergence performance for different regularization terms. Empirical experiments on binary classification tasks with real-world datasets demonstrate our proposed algorithms are capable of performing classification and feature selection effectively with a lower computational cost.
Multi-Task Learning with Prior Information
Jan 04, 2023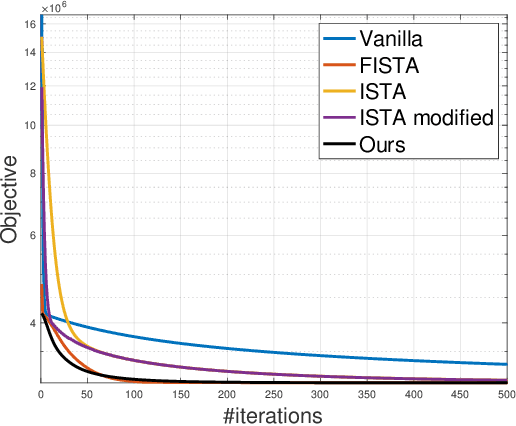
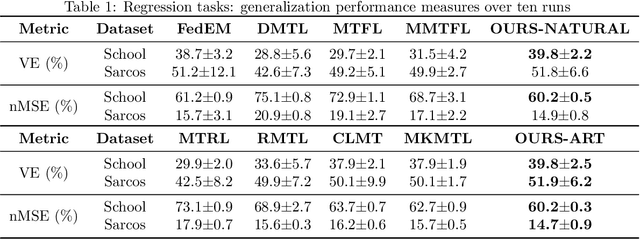
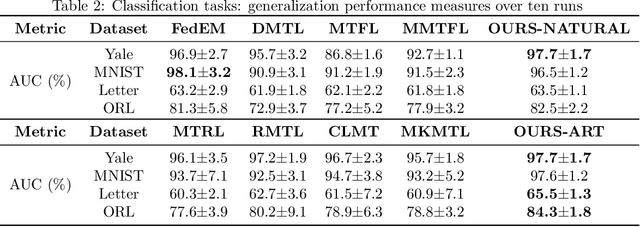
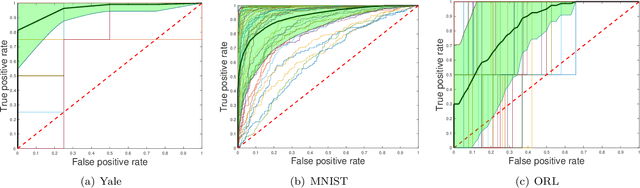
Multi-task learning aims to boost the generalization performance of multiple related tasks simultaneously by leveraging information contained in those tasks. In this paper, we propose a multi-task learning framework, where we utilize prior knowledge about the relations between features. We also impose a penalty on the coefficients changing for each specific feature to ensure related tasks have similar coefficients on common features shared among them. In addition, we capture a common set of features via group sparsity. The objective is formulated as a non-smooth convex optimization problem, which can be solved with various methods, including gradient descent method with fixed stepsize, iterative shrinkage-thresholding algorithm (ISTA) with back-tracking, and its variation -- fast iterative shrinkage-thresholding algorithm (FISTA). In light of the sub-linear convergence rate of the methods aforementioned, we propose an asymptotically linear convergent algorithm with theoretical guarantee. Empirical experiments on both regression and classification tasks with real-world datasets demonstrate that our proposed algorithms are capable of improving the generalization performance of multiple related tasks.
Rethinking Symmetric Matrix Factorization: A More General and Better Clustering Perspective
Sep 06, 2022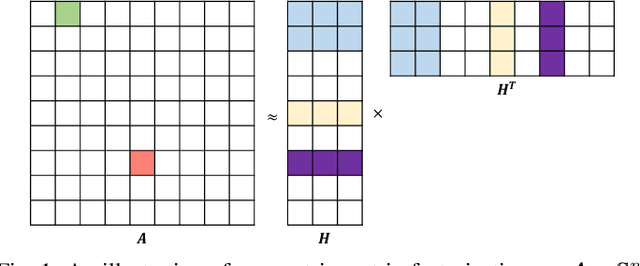
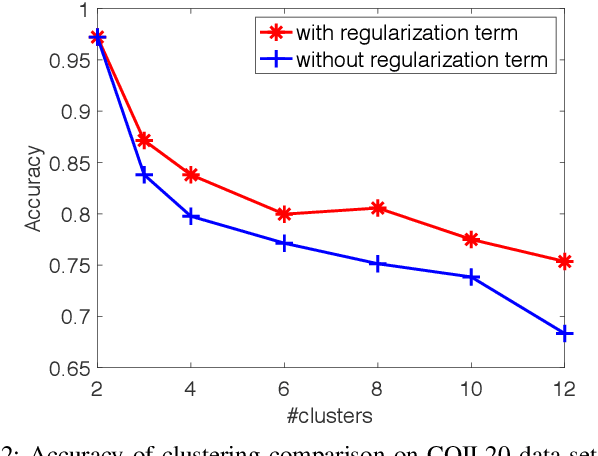
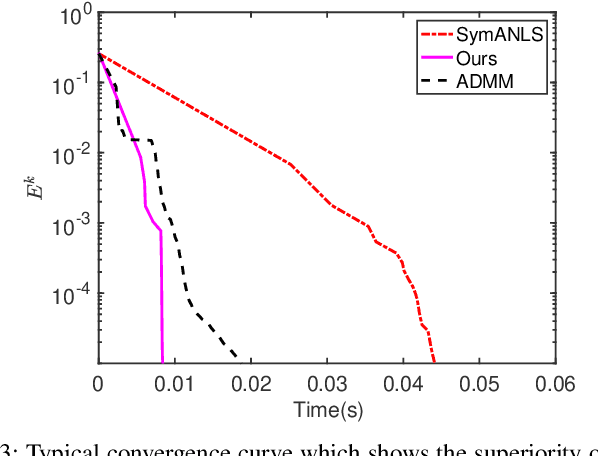
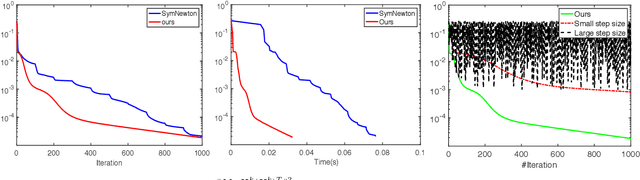
Nonnegative matrix factorization (NMF) is widely used for clustering with strong interpretability. Among general NMF problems, symmetric NMF is a special one which plays an important role for graph clustering where each element measures the similarity between data points. Most existing symmetric NMF algorithms require factor matrices to be nonnegative, and only focus on minimizing the gap between the original matrix and its approximation for clustering, without giving a consideration to other potential regularization terms which can yield better clustering. In this paper, we explore to factorize a symmetric matrix that does not have to be nonnegative, presenting an efficient factorization algorithm with a regularization term to boost the clustering performance. Moreover, a more generalized framework is proposed to solve symmetric matrix factorization problems with different constraints on the factor matrices.