 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Stance Detection in the Wild: Dynamic Target Generation and Multi-Target Adaptation
Jan 28, 2026Current stance detection research typically relies on predicting stance based on given targets and text. However, in real-world social media scenarios, targets are neither predefined nor static but rather complex and dynamic. To address this challenge, we propose a novel task: zero-shot stance detection in the wild with Dynamic Target Generation and Multi-Target Adaptation (DGTA), which aims to automatically identify multiple target-stance pairs from text without prior target knowledge. We construct a Chinese social media stance detection dataset and design multi-dimensional evaluation metrics. We explore both integrated and two-stage fine-tuning strategies for large language models (LLMs) and evaluate various baseline models. Experimental results demonstrate that fine-tuned LLMs achieve superior performance on this task: the two-stage fine-tuned Qwen2.5-7B attains the highest comprehensive target recognition score of 66.99%, while the integrated fine-tuned DeepSeek-R1-Distill-Qwen-7B achieves a stance detection F1 score of 79.26%.
Adversarial Alignment: Ensuring Value Consistency in Large Language Models for Sensitive Domains
Jan 19, 2026With the wide application of large language models (LLMs), the problems of bias and value inconsistency in sensitive domains have gradually emerged, especially in terms of race, society and politics. In this paper, we propose an adversarial alignment framework, which enhances the value consistency of the model in sensitive domains through continued pre-training, instruction fine-tuning and adversarial training. In adversarial training, we use the Attacker to generate controversial queries, the Actor to generate responses with value consistency, and the Critic to filter and ensure response quality. Furthermore, we train a Value-Consistent Large Language Model, VC-LLM, for sensitive domains, and construct a bilingual evaluation dataset in Chinese and English. The experimental results show that VC-LLM performs better than the existing mainstream models in both Chinese and English tests, verifying the effectiveness of the method. Warning: This paper contains examples of LLMs that are offensive or harmful in nature.
WenyanGPT: A Large Language Model for Classical Chinese Tasks
Apr 29, 2025Classical Chinese, as the core carrier of Chinese culture, plays a crucial role in the inheritance and study of ancient literature. However, existing natural language processing models primarily optimize for Modern Chinese, resulting in inadequate performance on Classical Chinese. This paper presents a comprehensive solution for Classical Chinese language processing. By continuing pre-training and instruction fine-tuning on the LLaMA3-8B-Chinese model, we construct a large language model, WenyanGPT, which is specifically designed for Classical Chinese tasks. Additionally, we develop an evaluation benchmark dataset, WenyanBENCH. Experimental results on WenyanBENCH demonstrate that WenyanGPT significantly outperforms current advanced LLMs in various Classical Chinese tasks. We make the model's training data, instruction fine-tuning data\footnote, and evaluation benchmark dataset publicly available to promote further research and development in the field of Classical Chinese processing.
MM-Eval: A Hierarchical Benchmark for Modern Mongolian Evaluation in LLMs
Nov 14, 2024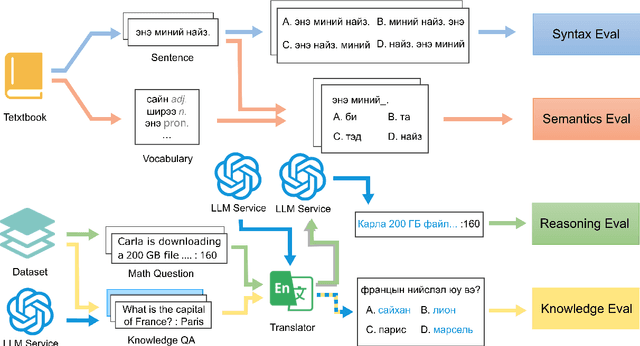
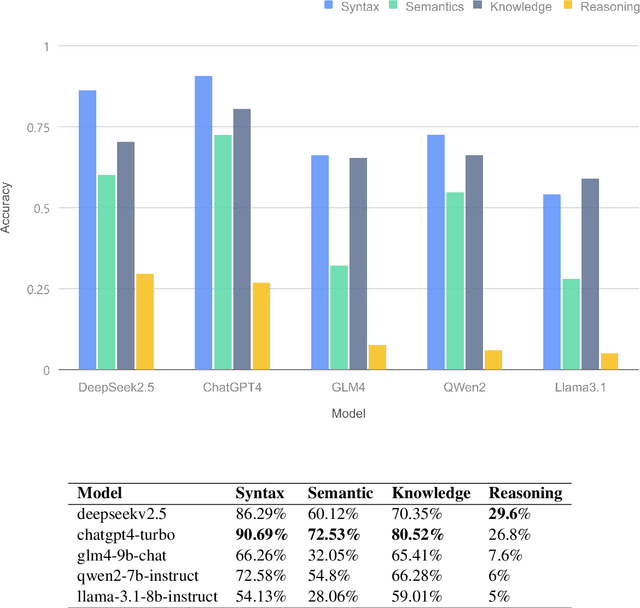
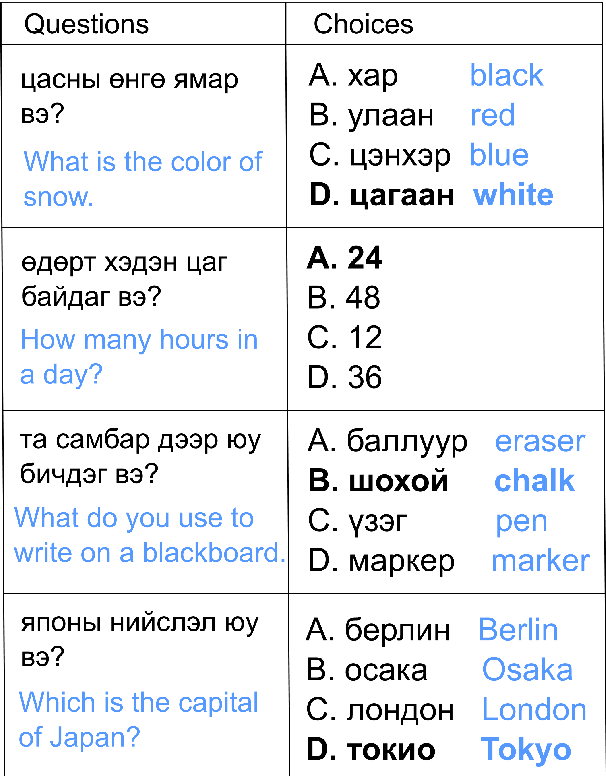
Large language models (LLMs) excel in high-resource languages but face notable challenges in low-resource languages like Mongolian. This paper addresses these challenges by categorizing capabilities into language abilities (syntax and semantics) and cognitive abilities (knowledge and reasoning). To systematically evaluate these areas, we developed MM-Eval, a specialized dataset based on Modern Mongolian Language Textbook I and enriched with WebQSP and MGSM datasets. Preliminary experiments on models including Qwen2-7B-Instruct, GLM4-9b-chat, Llama3.1-8B-Instruct, GPT-4, and DeepseekV2.5 revealed that: 1) all models performed better on syntactic tasks than semantic tasks, highlighting a gap in deeper language understanding; and 2) knowledge tasks showed a moderate decline, suggesting that models can transfer general knowledge from high-resource to low-resource contexts. The release of MM-Eval, comprising 569 syntax, 677 semantics, 344 knowledge, and 250 reasoning tasks, offers valuable insights for advancing NLP and LLMs in low-resource languages like Mongolian. The dataset is available at https://github.com/joenahm/MM-Eval.
MiLMo:Minority Multilingual Pre-trained Language Model
Dec 04, 2022



Pre-trained language models are trained on large-scale unsupervised data, and they can be fine-tuned on small-scale labeled datasets and achieve good results. Multilingual pre-trained language models can be trained on multiple languages and understand multiple languages at the same time. At present, the research on pre-trained models mainly focuses on rich-resource language, while there is relatively little research on low-resource languages such as minority languages, and the public multilingual pre-trained language model can not work well for minority languages. Therefore, this paper constructs a multilingual pre-trained language model named MiLMo that performs better on minority language tasks, including Mongolian, Tibetan, Uyghur, Kazakh and Korean. To solve the problem of scarcity of datasets on minority languages and verify the effectiveness of the MiLMo model, this paper constructs a minority multilingual text classification dataset named MiTC, and trains a word2vec model for each language. By comparing the word2vec model and the pre-trained model in the text classification task, this paper provides an optimal scheme for the downstream task research of minority languages. The final experimental results show that the performance of the pre-trained model is better than that of the word2vec model, and it has achieved the best results in minority multilingual text classification. The multilingual pre-trained language model MiLMo, multilingual word2vec model and multilingual text classification dataset MiTC are published on https://milmo.cmli-nlp.com.
TiBERT: Tibetan Pre-trained Language Model
May 15, 2022
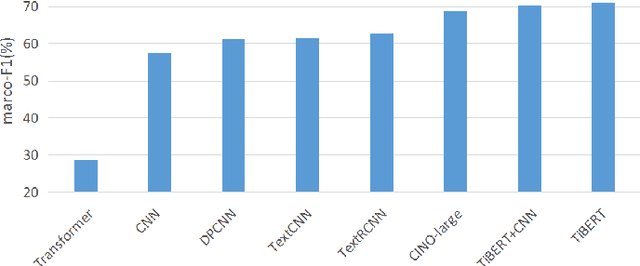


The pre-trained language model is trained on large-scale unlabeled text and can achieve state-of-the-art results in many different downstream tasks. However, the current pre-trained language model is mainly concentrated in the Chinese and English fields. For low resource language such as Tibetan, there is lack of a monolingual pre-trained model. To promote the development of Tibetan natural language processing tasks, this paper collects the large-scale training data from Tibetan websites and constructs a vocabulary that can cover 99.95$\%$ of the words in the corpus by using Sentencepiece. Then, we train the Tibetan monolingual pre-trained language model named TiBERT on the data and vocabulary. Finally, we apply TiBERT to the downstream tasks of text classification and question generation, and compare it with classic models and multilingual pre-trained models, the experimental results show that TiBERT can achieve the best performance. Our model is published in http://tibert.cmli-nlp.com/
Vision-based Unscented FastSLAM for Mobile Robot
May 03, 2019

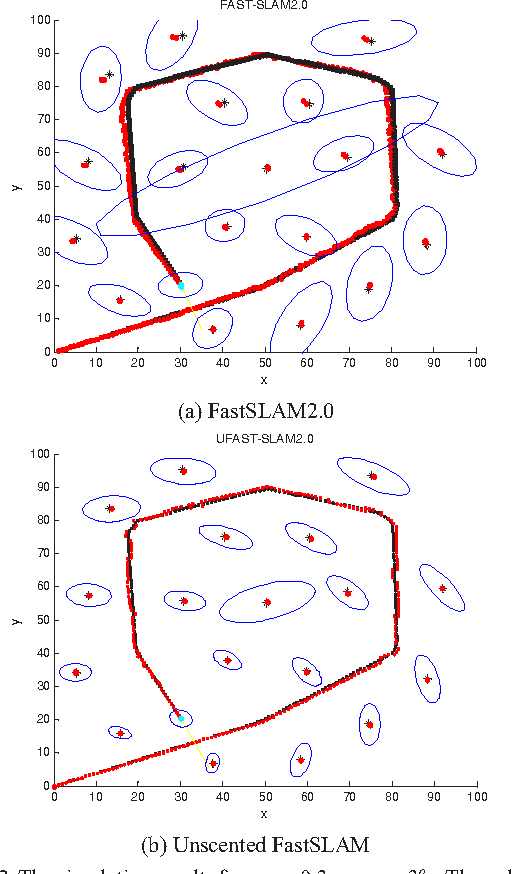
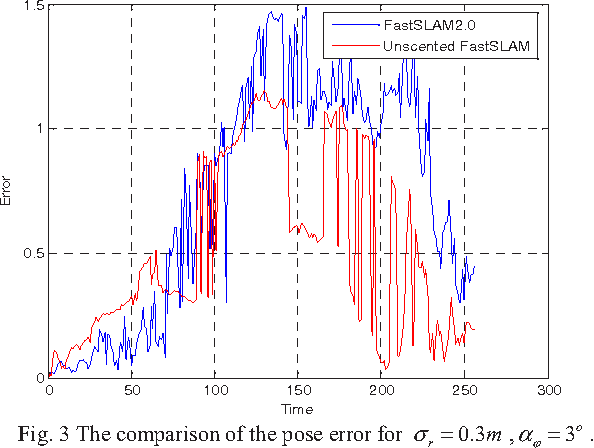
This paper presents a vision-based Unscented FastSLAM (UFastSLAM) algorithm combing the Rao-Blackwellized particle filter and Unscented Kalman filte(UKF). The landmarks are detected by a binocular vision to integrate localization and mapping. Since such binocular vision system generally inherits larger measurement errors, it is suitable to adopt Unscented FastSLAM to improve the performance of localization and mapping. Unscented FastSLAM takes advantage of UKF instead of the linear approximations of the nonlinear function where the effective number of particles is used as the criteria to reduce the particle degeneration. Simulations and experiments are carried out to demonstrate that the Unscented FastSLAM algorithm can achieve much better performance in the vision-based system than FastSLAM2.0 algorithm on the accuracy and robustness.