 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Alignment: Ensuring Value Consistency in Large Language Models for Sensitive Domains
Jan 19, 2026With the wide application of large language models (LLMs), the problems of bias and value inconsistency in sensitive domains have gradually emerged, especially in terms of race, society and politics. In this paper, we propose an adversarial alignment framework, which enhances the value consistency of the model in sensitive domains through continued pre-training, instruction fine-tuning and adversarial training. In adversarial training, we use the Attacker to generate controversial queries, the Actor to generate responses with value consistency, and the Critic to filter and ensure response quality. Furthermore, we train a Value-Consistent Large Language Model, VC-LLM, for sensitive domains, and construct a bilingual evaluation dataset in Chinese and English. The experimental results show that VC-LLM performs better than the existing mainstream models in both Chinese and English tests, verifying the effectiveness of the method. Warning: This paper contains examples of LLMs that are offensive or harmful in nature.
DOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
WenyanGPT: A Large Language Model for Classical Chinese Tasks
Apr 29, 2025Classical Chinese, as the core carrier of Chinese culture, plays a crucial role in the inheritance and study of ancient literature. However, existing natural language processing models primarily optimize for Modern Chinese, resulting in inadequate performance on Classical Chinese. This paper presents a comprehensive solution for Classical Chinese language processing. By continuing pre-training and instruction fine-tuning on the LLaMA3-8B-Chinese model, we construct a large language model, WenyanGPT, which is specifically designed for Classical Chinese tasks. Additionally, we develop an evaluation benchmark dataset, WenyanBENCH. Experimental results on WenyanBENCH demonstrate that WenyanGPT significantly outperforms current advanced LLMs in various Classical Chinese tasks. We make the model's training data, instruction fine-tuning data\footnote, and evaluation benchmark dataset publicly available to promote further research and development in the field of Classical Chinese processing.
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Apr 08, 2025Recent advancements in large language models (LLMs) have revolutionized their ability to handle single-turn tasks, yet real-world applications demand sophisticated multi-turn interactions. This survey provides a comprehensive review of recent advancements in evaluating and enhancing multi-turn interactions in LLMs. Focusing on task-specific scenarios, from instruction following in diverse domains such as math and coding to complex conversational engagements in roleplay, healthcare, education, and even adversarial jailbreak settings, we systematically examine the challenges of maintaining context, coherence, fairness, and responsiveness over prolonged dialogues. The paper organizes current benchmarks and datasets into coherent categories that reflect the evolving landscape of multi-turn dialogue evaluation. In addition, we review a range of enhancement methodologies under multi-turn settings, including model-centric strategies (contextual learning, supervised fine-tuning, reinforcement learning, and new architectures), external integration approaches (memory-augmented, retrieval-based methods, and knowledge graph), and agent-based techniques for collaborative interactions. Finally, we discuss open challenges and propose future directions for research to further advance the robustness and effectiveness of multi-turn interactions in LLMs. Related resources and papers are available at https://github.com/yubol-cmu/Awesome-Multi-Turn-LLMs.
Can LLMs Support Medical Knowledge Imputation? An Evaluation-Based Perspective
Mar 29, 2025


Medical knowledge graphs (KGs) are essential for clinical decision support and biomedical research, yet they often exhibit incompleteness due to knowledge gaps and structural limitations in medical coding systems. This issue is particularly evident in treatment mapping, where coding systems such as ICD, Mondo, and ATC lack comprehensive coverage, resulting in missing or inconsistent associations between diseases and their potential treatments. To address this issue, we have explored the use of Large Language Models (LLMs) for imputing missing treatment relationships. Although LLMs offer promising capabilities in knowledge augmentation, their application in medical knowledge imputation presents significant risks, including factual inaccuracies, hallucinated associations, and instability between and within LLMs. In this study, we systematically evaluate LLM-driven treatment mapping, assessing its reliability through benchmark comparisons. Our findings highlight critical limitations, including inconsistencies with established clinical guidelines and potential risks to patient safety. This study serves as a cautionary guide for researchers and practitioners, underscoring the importance of critical evaluation and hybrid approaches when leveraging LLMs to enhance treatment mappings on medical knowledge graphs.
No Black Box Anymore: Demystifying Clinical Predictive Modeling with Temporal-Feature Cross Attention Mechanism
Mar 26, 2025
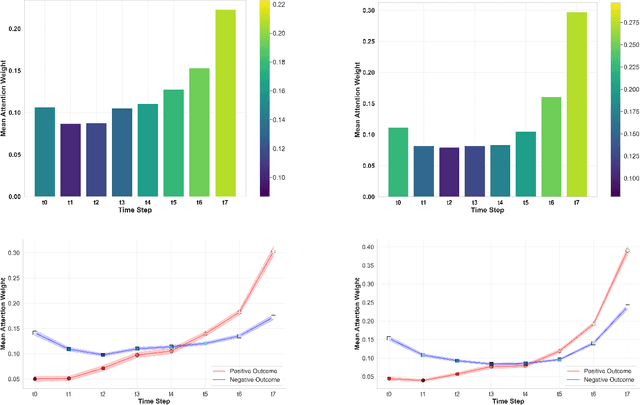


Despite the outstanding performance of deep learning models in clinical prediction tasks, explainability remains a significant challenge. Inspired by transformer architectures, we introduce the Temporal-Feature Cross Attention Mechanism (TFCAM), a novel deep learning framework designed to capture dynamic interactions among clinical features across time, enhancing both predictive accuracy and interpretability. In an experiment with 1,422 patients with Chronic Kidney Disease, predicting progression to End-Stage Renal Disease, TFCAM outperformed LSTM and RETAIN baselines, achieving an AUROC of 0.95 and an F1-score of 0.69. Beyond performance gains, TFCAM provides multi-level explainability by identifying critical temporal periods, ranking feature importance, and quantifying how features influence each other across time before affecting predictions. Our approach addresses the "black box" limitations of deep learning in healthcare, offering clinicians transparent insights into disease progression mechanisms while maintaining state-of-the-art predictive performance.