 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Jun 11, 2026Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
The Chain Holds, the Answer Folds: Trace-Answer Dissociation in Reasoning Models Under Adversarial Pressure
May 27, 2026Reasoning models are evaluated on single-turn benchmarks but deployed in multi-turn dialogue, where users push back on correct answers. Under sustained adversarial pressure we find a previously undocumented failure mode: the chain-of-thought stays factually correct from first turn to last while the emitted answer flips wrong. We call this unfaithful capitulation (UC) and isolate it with a $2\times 2$ latent-versus-behavioral framework that flip-rate metrics and single-turn faithfulness probes both miss. Across three datasets (MT-Consistency, MMLU-Pro, GSM8K), the latent-correct rate at the behavioral flip clusters near 50% in think mode and collapses to 11-15% under no_think -- paired, within-model causal evidence that reasoning creates the gap. Across models the effect tracks the reasoning channel (high in Qwen3-32B and GPT-OSS-20B, low in inline-CoT Gemma-4-31B-it). An independent GPT-4o judge corroborates $86\%$ of UC labels; a token-level probe shows the answer-slot argmax is correct in $84\%$ of UC cells; and a naive trace-anchored defense backfires. We release all trajectories, traces, and judge labels.
Same Question, Different Source, Different Answer: Auditing Source-Dependence in Medical Multi-Source RAG
May 27, 2026A retrieval-augmented generation (RAG) system deployed over a multi-author institutional corpus can give a different answer to the same question depending on which source it retrieves -- a failure mode the dominant single-gold-answer paradigm cannot diagnose. We argue that source-dependence is a missing axis of NLP evaluation, and that auditing it means shifting the unit of evaluation from answer correctness to the inter-source relationship. We make this concrete in transplant patient education, where institutional sources demonstrably disagree, releasing three artefacts: TransplantQA, a benchmark of real patient questions, each answered by grounding generation in multiple institutional handbooks as candidate sources; HERO-QA, a hierarchical retrieval strategy that grounds and audits each answer; and a structured-output judge that scores inter-source relationships on a validated 5-label taxonomy. At scale, better retrieval reveals far more disagreement than prior estimates suggested -- understating its prevalence, not its intensity. The framework is domain-agnostic and transfers to legal and educational RAG: measuring source-dependence is a responsibility for deployed multi-source NLP generally.
The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning
Mar 30, 2026Large language models systematically fail when a salient surface cue conflicts with an unstated feasibility constraint. We study this through a diagnose-measure-bridge-treat framework. Causal-behavioral analysis of the ``car wash problem'' across six models reveals approximately context-independent sigmoid heuristics: the distance cue exerts 8.7 to 38 times more influence than the goal, and token-level attribution shows patterns more consistent with keyword associations than compositional inference. The Heuristic Override Benchmark (HOB) -- 500 instances spanning 4 heuristic by 5 constraint families with minimal pairs and explicitness gradients -- demonstrates generality across 14 models: under strict evaluation (10/10 correct), no model exceeds 75%, and presence constraints are hardest (44%). A minimal hint (e.g., emphasizing the key object) recovers +15 pp on average, suggesting the failure lies in constraint inference rather than missing knowledge; 12/14 models perform worse when the constraint is removed (up to -39 pp), revealing conservative bias. Parametric probes confirm that the sigmoid pattern generalizes to cost, efficiency, and semantic-similarity heuristics; goal-decomposition prompting recovers +6 to 9 pp by forcing models to enumerate preconditions before answering. Together, these results characterize heuristic override as a systematic reasoning vulnerability and provide a benchmark for measuring progress toward resolving it.
When Documents Disagree: Measuring Institutional Variation in Transplant Guidance with Retrieval-Augmented Language Models
Mar 23, 2026Patient education materials for solid-organ transplantation vary substantially across U.S. centers, yet no systematic method exists to quantify this heterogeneity at scale. We introduce a framework that grounds the same patient questions in different centers' handbooks using retrieval-augmented language models and compares the resulting answers using a five-label consistency taxonomy. Applied to 102 handbooks from 23 centers and 1,115 benchmark questions, the framework quantifies heterogeneity across four dimensions: question, topic, organ, and center. We find that 20.8% of non-absent pairwise comparisons exhibit clinically meaningful divergence, concentrated in condition monitoring and lifestyle topics. Coverage gaps are even more prominent: 96.2% of question-handbook pairs miss relevant content, with reproductive health at 95.1% absence. Center-level divergence profiles are stable and interpretable, where heterogeneity reflects systematic institutional differences, likely due to patient diversity. These findings expose an information gap in transplant patient education materials, with document-grounded medical question answering highlighting opportunities for content improvement.
Consistency of Large Reasoning Models Under Multi-Turn Attacks
Feb 16, 2026Large reasoning models with reasoning capabilities achieve state-of-the-art performance on complex tasks, but their robustness under multi-turn adversarial pressure remains underexplored. We evaluate nine frontier reasoning models under adversarial attacks. Our findings reveal that reasoning confers meaningful but incomplete robustness: most reasoning models studied significantly outperform instruction-tuned baselines, yet all exhibit distinct vulnerability profiles, with misleading suggestions universally effective and social pressure showing model-specific efficacy. Through trajectory analysis, we identify five failure modes (Self-Doubt, Social Conformity, Suggestion Hijacking, Emotional Susceptibility, and Reasoning Fatigue) with the first two accounting for 50% of failures. We further demonstrate that Confidence-Aware Response Generation (CARG), effective for standard LLMs, fails for reasoning models due to overconfidence induced by extended reasoning traces; counterintuitively, random confidence embedding outperforms targeted extraction. Our results highlight that reasoning capabilities do not automatically confer adversarial robustness and that confidence-based defenses require fundamental redesign for reasoning models.
Closing Reasoning Gaps in Clinical Agents with Differential Reasoning Learning
Feb 10, 2026Clinical decision support requires not only correct answers but also clinically valid reasoning. We propose Differential Reasoning Learning (DRL), a framework that improves clinical agents by learning from reasoning discrepancies. From reference reasoning rationales (e.g., physician-authored clinical rationale, clinical guidelines, or outputs from more capable models) and the agent's free-form chain-of-thought (CoT), DRL extracts reasoning graphs as directed acyclic graphs (DAGs) and performs a clinically weighted graph edit distance (GED)-based discrepancy analysis. An LLM-as-a-judge aligns semantically equivalent nodes and diagnoses discrepancies between graphs. These graph-level discrepancy diagnostics are converted into natural-language instructions and stored in a Differential Reasoning Knowledge Base (DR-KB). At inference, we retrieve top-$k$ instructions via Retrieval-Augmented Generation (RAG) to augment the agent prompt and patch likely logic gaps. Evaluation on open medical question answering (QA) benchmarks and a Return Visit Admissions (RVA) prediction task from internal clinical data demonstrates gains over baselines, improving both final-answer accuracy and reasoning fidelity. Ablation studies confirm gains from infusing reference reasoning rationales and the top-$k$ retrieval strategy. Clinicians' review of the output provides further assurance of the approach. Together, results suggest that DRL supports more reliable clinical decision-making in complex reasoning scenarios and offers a practical mechanism for deployment under limited token budgets.
ML Compass: Navigating Capability, Cost, and Compliance Trade-offs in AI Model Deployment
Dec 29, 2025We study how organizations should select among competing AI models when user utility, deployment costs, and compliance requirements jointly matter. Widely used capability leaderboards do not translate directly into deployment decisions, creating a capability -- deployment gap; to bridge it, we take a systems-level view in which model choice is tied to application outcomes, operating constraints, and a capability-cost frontier. We develop ML Compass, a framework that treats model selection as constrained optimization over this frontier. On the theory side, we characterize optimal model configurations under a parametric frontier and show a three-regime structure in optimal internal measures: some dimensions are pinned at compliance minima, some saturate at maximum levels, and the remainder take interior values governed by frontier curvature. We derive comparative statics that quantify how budget changes, regulatory tightening, and technological progress propagate across capability dimensions and costs. On the implementation side, we propose a pipeline that (i) extracts low-dimensional internal measures from heterogeneous model descriptors, (ii) estimates an empirical frontier from capability and cost data, (iii) learns a user- or task-specific utility function from interaction outcome data, and (iv) uses these components to target capability-cost profiles and recommend models. We validate ML Compass with two case studies: a general-purpose conversational setting using the PRISM Alignment dataset and a healthcare setting using a custom dataset we build using HealthBench. In both environments, our framework produces recommendations -- and deployment-aware leaderboards based on predicted deployment value under constraints -- that can differ materially from capability-only rankings, and clarifies how trade-offs between capability, cost, and safety shape optimal model choice.
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Apr 08, 2025Recent advancements in large language models (LLMs) have revolutionized their ability to handle single-turn tasks, yet real-world applications demand sophisticated multi-turn interactions. This survey provides a comprehensive review of recent advancements in evaluating and enhancing multi-turn interactions in LLMs. Focusing on task-specific scenarios, from instruction following in diverse domains such as math and coding to complex conversational engagements in roleplay, healthcare, education, and even adversarial jailbreak settings, we systematically examine the challenges of maintaining context, coherence, fairness, and responsiveness over prolonged dialogues. The paper organizes current benchmarks and datasets into coherent categories that reflect the evolving landscape of multi-turn dialogue evaluation. In addition, we review a range of enhancement methodologies under multi-turn settings, including model-centric strategies (contextual learning, supervised fine-tuning, reinforcement learning, and new architectures), external integration approaches (memory-augmented, retrieval-based methods, and knowledge graph), and agent-based techniques for collaborative interactions. Finally, we discuss open challenges and propose future directions for research to further advance the robustness and effectiveness of multi-turn interactions in LLMs. Related resources and papers are available at https://github.com/yubol-cmu/Awesome-Multi-Turn-LLMs.
Firm or Fickle? Evaluating Large Language Models Consistency in Sequential Interactions
Mar 28, 2025


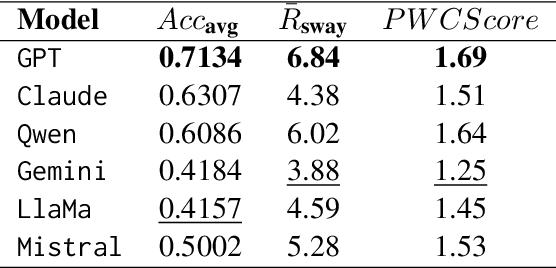
Large Language Models (LLMs) have shown remarkable capabilities across various tasks, but their deployment in high-stake domains requires consistent performance across multiple interaction rounds. This paper introduces a comprehensive framework for evaluating and improving LLM response consistency, making three key contributions. First, we propose a novel Position-Weighted Consistency (PWC) score that captures both the importance of early-stage stability and recovery patterns in multi-turn interactions. Second, we present a carefully curated benchmark dataset spanning diverse domains and difficulty levels, specifically designed to evaluate LLM consistency under various challenging follow-up scenarios. Third, we introduce Confidence-Aware Response Generation (CARG), a framework that significantly improves response stability by incorporating model confidence signals into the generation process. Empirical results demonstrate that CARG significantly improves response stability without sacrificing accuracy, underscoring its potential for reliable LLM deployment in critical applications.