 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoRC: A Benchmark for Geolocation Reasoning Chains
Jan 29, 2026Vision Language Models (VLMs) are good at recognizing the global location of a photograph -- their geolocation prediction accuracy rivals the best human experts. But many VLMs are startlingly bad at explaining which image evidence led to their prediction, even when their location prediction is correct. The reasoning chains produced by VLMs frequently hallucinate scene attributes to support their location prediction (e.g. phantom writing, imagined infrastructure, misidentified flora). In this paper, we introduce the first benchmark for geolocation reasoning chains. We focus on the global location prediction task in the popular GeoGuessr game which draws from Google Street View spanning more than 100 countries. We collaborate with expert GeoGuessr players, including the reigning world champion, to produce 800 ground truth reasoning chains for 500 query scenes. These expert reasoning chains address hundreds of different discriminative visual attributes such as license plate shape, architecture, and soil properties to name just a few. We evaluate LLM-as-a-judge and VLM-as-a-judge strategies for scoring VLM-generated reasoning chains against our expert reasoning chains and find that Qwen 3 LLM-as-a-judge correlates best with human scoring. Our benchmark reveals that while large, closed-source VLMs such as Gemini and GPT 5 rival human experts at prediction locations, they still lag behind human experts when it comes to producing auditable reasoning chains. Open weights VLMs such as Llama and Qwen catastrophically fail on our benchmark -- they perform only slightly better than a baseline in which an LLM hallucinates a reasoning chain with oracle knowledge of the photo location but no visual information at all. We believe the gap between human experts and VLMs on this task points to VLM limitations at extracting fine-grained visual attributes from high resolution images.
Modern Constraint Programming Education: Lessons for the Future
Jun 20, 2023This paper details an outlook on modern constraint programming (CP) education through the lens of a CP instructor. A general overview of current CP courses and instructional methods is presented, with a focus on online and virtually-delivered courses. This is followed by a discussion of the novel approach taken to introductory CP education for engineering students at large scale at the Georgia Institute of Technology (Georgia Tech) in Atlanta, GA, USA. The paper summarizes important takeaways from the Georgia Tech CP course and ends with a discussion on the future of CP education. Some ideas for instructional methods, promotional methods, and organizational changes are proposed to aid in the long-term growth of CP education.
Changes in Commuter Behavior from COVID-19 Lockdowns in the Atlanta Metropolitan Area
Feb 27, 2023



This paper analyzes the impact of COVID-19 related lockdowns in the Atlanta, Georgia metropolitan area by examining commuter patterns in three periods: prior to, during, and after the pandemic lockdown. A cellular phone location dataset is utilized in a novel pipeline to infer the home and work locations of thousands of users from the Density-based Spatial Clustering of Applications with Noise (DBSCAN) algorithm. The coordinates derived from the clustering are put through a reverse geocoding process from which word embeddings are extracted in order to categorize the industry of each work place based on the workplace name and Point of Interest (POI) mapping. Frequencies of commute from home locations to work locations are analyzed in and across all three time periods. Public health and economic factors are discussed to explain potential reasons for the observed changes in commuter patterns.
Deep Image Style Transfer from Freeform Text
Dec 13, 2022
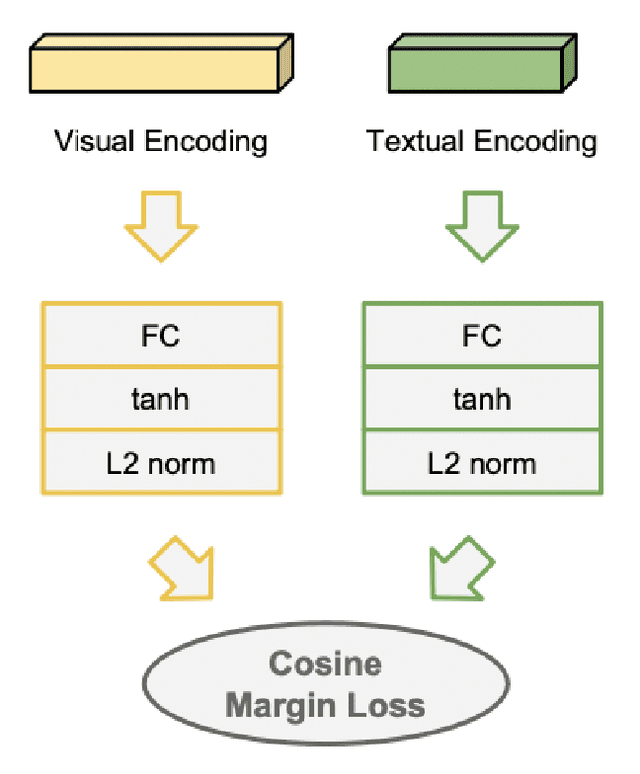
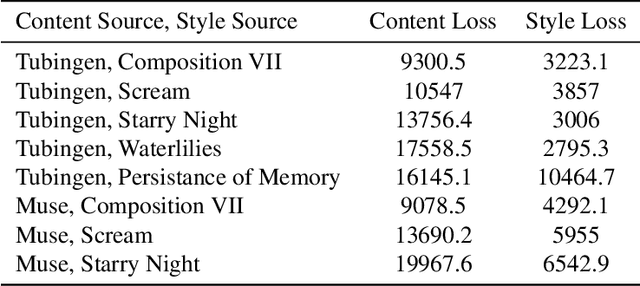

This paper creates a novel method of deep neural style transfer by generating style images from freeform user text input. The language model and style transfer model form a seamless pipeline that can create output images with similar losses and improved quality when compared to baseline style transfer methods. The language model returns a closely matching image given a style text and description input, which is then passed to the style transfer model with an input content image to create a final output. A proof-of-concept tool is also developed to integrate the models and demonstrate the effectiveness of deep image style transfer from freeform text.
Public Transit for Special Events: Ridership Prediction and Train Optimization
Jun 09, 2021
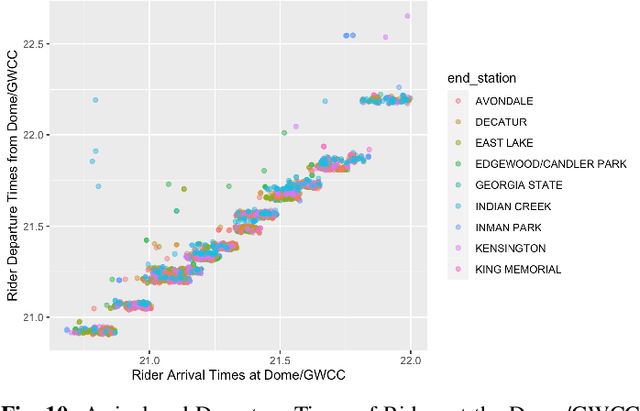

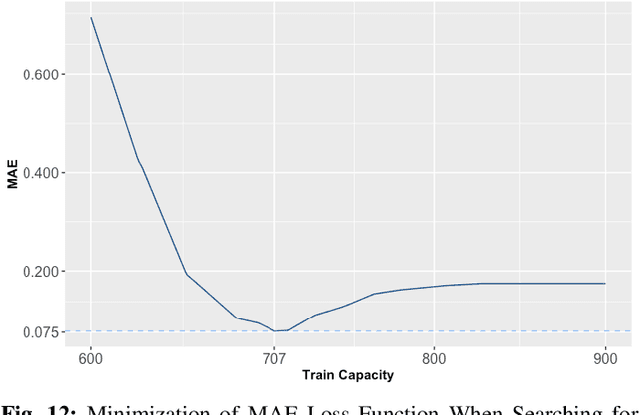
Many special events, including sport games and concerts, often cause surges in demand and congestion for transit systems. Therefore, it is important for transit providers to understand their impact on disruptions, delays, and fare revenues. This paper proposes a suite of data-driven techniques that exploit Automated Fare Collection (AFC) data for evaluating, anticipating, and managing the performance of transit systems during recurring congestion peaks due to special events. This includes an extensive analysis of ridership of the two major stadiums in downtown Atlanta using rail data from the Metropolitan Atlanta Rapid Transit Authority (MARTA). The paper first highlights the ridership predictability at the aggregate level for each station on both event and non-event days. It then presents an unsupervised machine-learning model to cluster passengers and identify which train they are boarding. The model makes it possible to evaluate system performance in terms of fundamental metrics such as the passenger load per train and the wait times of riders. The paper also presents linear regression and random forest models for predicting ridership that are used in combination with historical throughput analysis to forecast demand. Finally, simulations are performed that showcase the potential improvements to wait times and demand matching by leveraging proposed techniques to optimize train frequencies based on forecasted demand.