 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Zero to Hero: Advancing Zero-Shot Foundation Models for Tabular Outlier Detection
Feb 03, 2026Outlier detection (OD) is widely used in practice; but its effective deployment on new tasks is hindered by lack of labeled outliers, which makes algorithm and hyperparameter selection notoriously hard. Foundation models (FMs) have transformed ML, and OD is no exception: Shen et. al. (2025) introduced FoMo-0D, the first FM for OD, achieving remarkable performance against numerous baselines. This work introduces OUTFORMER, which advances FoMo-0D with (1) a mixture of synthetic priors and (2) self-evolving curriculum training. OUTFORMER is pretrained solely on synthetic labeled datasets and infers test labels of a new task by using its training data as in-context input. Inference is fast and zero-shot, requiring merely forward pass and no labeled outliers. Thanks to in-context learning, it requires zero additional work-no OD model training or bespoke model selection-enabling truly plug-and-play deployment. OUTFORMER achieves state-of-the-art performance on the prominent AdBench, as well as two new large-scale OD benchmarks that we introduce, comprising over 1,500 datasets, while maintaining speedy inference.
Threshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language Modeling
Jan 17, 2026Softmax attention struggles with long contexts due to structural limitations: the strict sum-to-one constraint forces attention sinks on irrelevant tokens, and probability mass disperses as sequence lengths increase. We tackle these problems with Threshold Differential Attention (TDA), a sink-free attention mechanism that achieves ultra-sparsity and improved robustness at longer sequence lengths without the computational overhead of projection methods or the performance degradation caused by noise accumulation of standard rectified attention. TDA applies row-wise extreme-value thresholding with a length-dependent gate, retaining only exceedances. Inspired by the differential transformer, TDA also subtracts an inhibitory view to enhance expressivity. Theoretically, we prove that TDA controls the expected number of spurious survivors per row to $O(1)$ and that consensus spurious matches across independent views vanish as context grows. Empirically, TDA produces $>99\%$ exact zeros and eliminates attention sinks while maintaining competitive performance on standard and long-context benchmarks.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025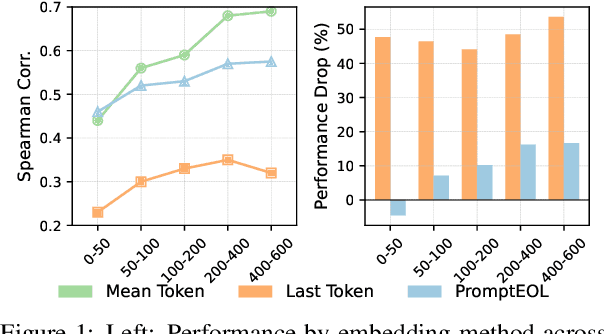
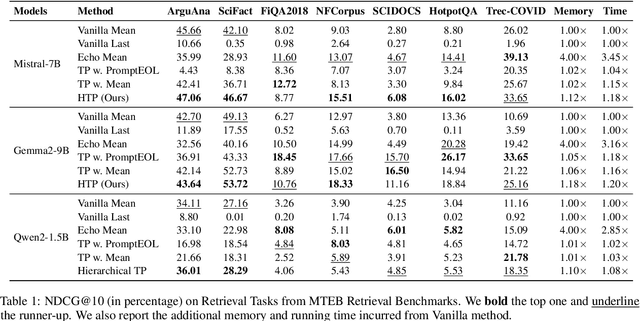
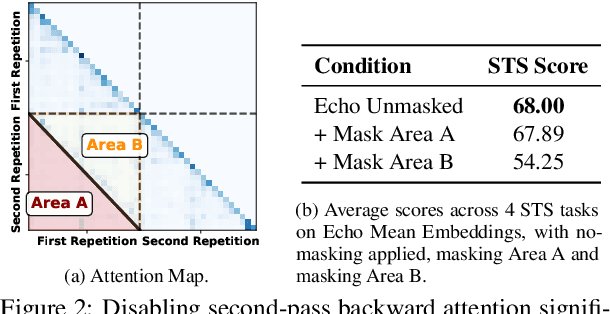
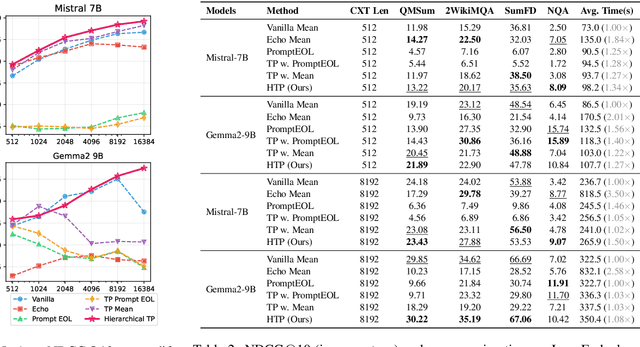
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Apr 08, 2025Recent advancements in large language models (LLMs) have revolutionized their ability to handle single-turn tasks, yet real-world applications demand sophisticated multi-turn interactions. This survey provides a comprehensive review of recent advancements in evaluating and enhancing multi-turn interactions in LLMs. Focusing on task-specific scenarios, from instruction following in diverse domains such as math and coding to complex conversational engagements in roleplay, healthcare, education, and even adversarial jailbreak settings, we systematically examine the challenges of maintaining context, coherence, fairness, and responsiveness over prolonged dialogues. The paper organizes current benchmarks and datasets into coherent categories that reflect the evolving landscape of multi-turn dialogue evaluation. In addition, we review a range of enhancement methodologies under multi-turn settings, including model-centric strategies (contextual learning, supervised fine-tuning, reinforcement learning, and new architectures), external integration approaches (memory-augmented, retrieval-based methods, and knowledge graph), and agent-based techniques for collaborative interactions. Finally, we discuss open challenges and propose future directions for research to further advance the robustness and effectiveness of multi-turn interactions in LLMs. Related resources and papers are available at https://github.com/yubol-cmu/Awesome-Multi-Turn-LLMs.
Firm or Fickle? Evaluating Large Language Models Consistency in Sequential Interactions
Mar 28, 2025


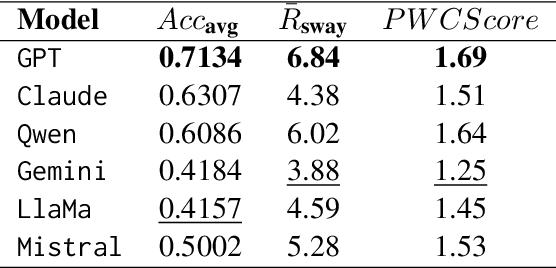
Large Language Models (LLMs) have shown remarkable capabilities across various tasks, but their deployment in high-stake domains requires consistent performance across multiple interaction rounds. This paper introduces a comprehensive framework for evaluating and improving LLM response consistency, making three key contributions. First, we propose a novel Position-Weighted Consistency (PWC) score that captures both the importance of early-stage stability and recovery patterns in multi-turn interactions. Second, we present a carefully curated benchmark dataset spanning diverse domains and difficulty levels, specifically designed to evaluate LLM consistency under various challenging follow-up scenarios. Third, we introduce Confidence-Aware Response Generation (CARG), a framework that significantly improves response stability by incorporating model confidence signals into the generation process. Empirical results demonstrate that CARG significantly improves response stability without sacrificing accuracy, underscoring its potential for reliable LLM deployment in critical applications.
MetaOOD: Automatic Selection of OOD Detection Models
Oct 04, 2024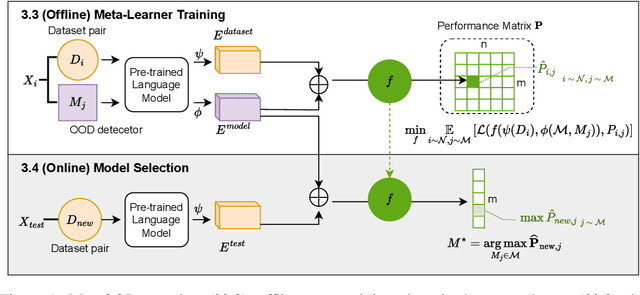
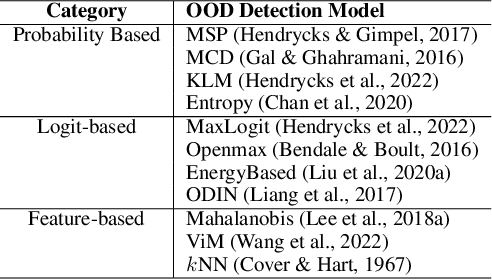
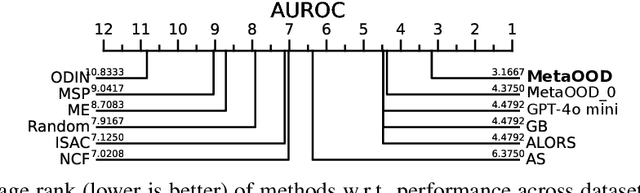
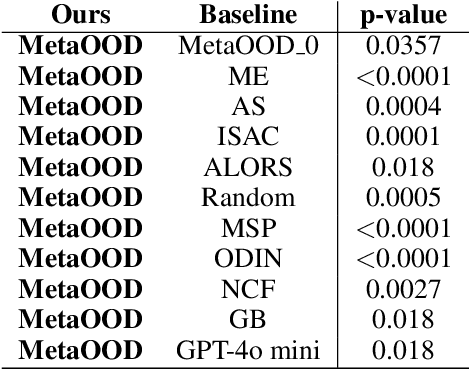
How can we automatically select an out-of-distribution (OOD) detection model for various underlying tasks? This is crucial for maintaining the reliability of open-world applications by identifying data distribution shifts, particularly in critical domains such as online transactions, autonomous driving, and real-time patient diagnosis. Despite the availability of numerous OOD detection methods, the challenge of selecting an optimal model for diverse tasks remains largely underexplored, especially in scenarios lacking ground truth labels. In this work, we introduce MetaOOD, the first zero-shot, unsupervised framework that utilizes meta-learning to automatically select an OOD detection model. As a meta-learning approach, MetaOOD leverages historical performance data of existing methods across various benchmark OOD datasets, enabling the effective selection of a suitable model for new datasets without the need for labeled data at the test time. To quantify task similarities more accurately, we introduce language model-based embeddings that capture the distinctive OOD characteristics of both datasets and detection models. Through extensive experimentation with 24 unique test dataset pairs to choose from among 11 OOD detection models, we demonstrate that MetaOOD significantly outperforms existing methods and only brings marginal time overhead. Our results, validated by Wilcoxon statistical tests, show that MetaOOD surpasses a diverse group of 11 baselines, including established OOD detectors and advanced unsupervised selection methods.
Outlier Detection Bias Busted: Understanding Sources of Algorithmic Bias through Data-centric Factors
Aug 24, 2024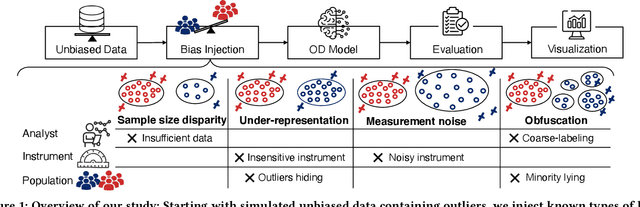
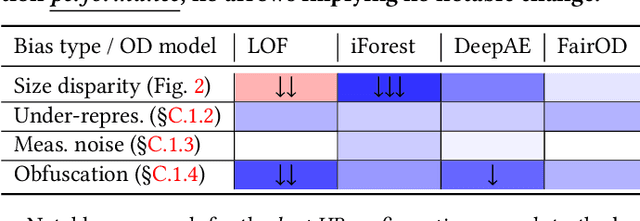
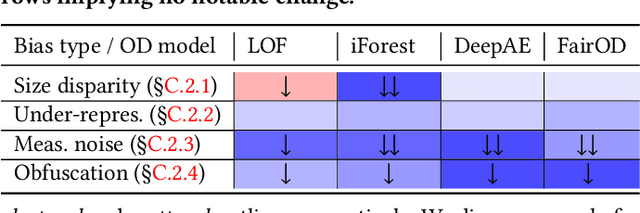
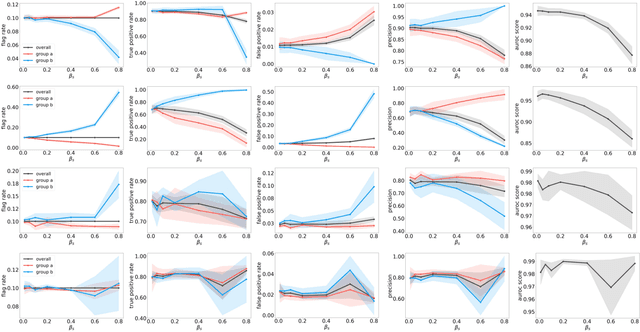
The astonishing successes of ML have raised growing concern for the fairness of modern methods when deployed in real world settings. However, studies on fairness have mostly focused on supervised ML, while unsupervised outlier detection (OD), with numerous applications in finance, security, etc., have attracted little attention. While a few studies proposed fairness-enhanced OD algorithms, they remain agnostic to the underlying driving mechanisms or sources of unfairness. Even within the supervised ML literature, there exists debate on whether unfairness stems solely from algorithmic biases (i.e. design choices) or from the biases encoded in the data on which they are trained. To close this gap, this work aims to shed light on the possible sources of unfairness in OD by auditing detection models under different data-centric factors. By injecting various known biases into the input data -- as pertain to sample size disparity, under-representation, feature measurement noise, and group membership obfuscation -- we find that the OD algorithms under the study all exhibit fairness pitfalls, although differing in which types of data bias they are more susceptible to. Most notable of our study is to demonstrate that OD algorithm bias is not merely a data bias problem. A key realization is that the data properties that emerge from bias injection could as well be organic -- as pertain to natural group differences w.r.t. sparsity, base rate, variance, and multi-modality. Either natural or biased, such data properties can give rise to unfairness as they interact with certain algorithmic design choices.
Improving and Unifying Discrete&Continuous-time Discrete Denoising Diffusion
Feb 06, 2024



Discrete diffusion models have seen a surge of attention with applications on naturally discrete data such as language and graphs. Although discrete-time discrete diffusion has been established for a while, only recently Campbell et al. (2022) introduced the first framework for continuous-time discrete diffusion. However, their training and sampling processes differ significantly from the discrete-time version, necessitating nontrivial approximations for tractability. In this paper, we first present a series of mathematical simplifications of the variational lower bound that enable more accurate and easy-to-optimize training for discrete diffusion. In addition, we derive a simple formulation for backward denoising that enables exact and accelerated sampling, and importantly, an elegant unification of discrete-time and continuous-time discrete diffusion. Thanks to simpler analytical formulations, both forward and now also backward probabilities can flexibly accommodate any noise distribution, including different noise distributions for multi-element objects. Experiments show that our proposed USD3 (for Unified Simplified Discrete Denoising Diffusion) outperform all SOTA baselines on established datasets. We open-source our unified code at https://github.com/LingxiaoShawn/USD3.
Pard: Permutation-Invariant Autoregressive Diffusion for Graph Generation
Feb 06, 2024



Graph generation has been dominated by autoregressive models due to their simplicity and effectiveness, despite their sensitivity to ordering. Yet diffusion models have garnered increasing attention, as they offer comparable performance while being permutation-invariant. Current graph diffusion models generate graphs in a one-shot fashion, but they require extra features and thousands of denoising steps to achieve optimal performance. We introduce PARD, a Permutation-invariant Auto Regressive Diffusion model that integrates diffusion models with autoregressive methods. PARD harnesses the effectiveness and efficiency of the autoregressive model while maintaining permutation invariance without ordering sensitivity. Specifically, we show that contrary to sets, elements in a graph are not entirely unordered and there is a unique partial order for nodes and edges. With this partial order, PARD generates a graph in a block-by-block, autoregressive fashion, where each block's probability is conditionally modeled by a shared diffusion model with an equivariant network. To ensure efficiency while being expressive, we further propose a higher-order graph transformer, which integrates transformer with PPGN. Like GPT, we extend the higher-order graph transformer to support parallel training of all blocks. Without any extra features, PARD achieves state-of-the-art performance on molecular and non-molecular datasets, and scales to large datasets like MOSES containing 1.9M molecules.
PINNsFormer: A Transformer-Based Framework For Physics-Informed Neural Networks
Jul 21, 2023Physics-Informed Neural Networks (PINNs) have emerged as a promising deep learning framework for approximating numerical solutions for partial differential equations (PDEs). While conventional PINNs and most related studies adopt fully-connected multilayer perceptrons (MLP) as the backbone structure, they have neglected the temporal relations in PDEs and failed to approximate the true solution. In this paper, we propose a novel Transformer-based framework, namely PINNsFormer, that accurately approximates PDEs' solutions by capturing the temporal dependencies with multi-head attention mechanisms in Transformer-based models. Instead of approximating point predictions, PINNsFormer adapts input vectors to pseudo sequences and point-wise PINNs loss to a sequential PINNs loss. In addition, PINNsFormer is equipped with a novel activation function, namely Wavelet, which anticipates the Fourier decomposition through deep neural networks. We empirically demonstrate PINNsFormer's ability to capture the PDE solutions for various scenarios, in which conventional PINNs have failed to learn. We also show that PINNsFormer achieves superior approximation accuracy on such problems than conventional PINNs with non-sensitive hyperparameters, in trade of marginal computational and memory costs, with extensive experiments.