 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Kernel Density Estimation with Pre-training
May 13, 2026Density estimation in high-dimensional settings is an important and challenging statistical problem.Traditional methods based on kernel smoothing are inefficient in high dimensions due to the difficulties in specifying appropriate location-adaptive kernels. In this work, we introduce pre-training, a key idea behind many cutting-edge AI technologies, to the context of non-parametric density estimation. By establishing a pre-trained neural network that can recommend an appropriate location-adaptive kernel for each sample point, efficient density estimation with adaptive kernels is achieved in high dimensions. A wide range of numerical experiments show that this strategy is highly effective for improving density-estimation accuracy, when the target distribution is close to the distribution family for pre-training. When the target distribution is substantially different from the pre-training distribution family, the benefit from the proposed pre-training strategy may be diluted, but can be reactivated by an additional fine-tuning procedure.
Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning
May 07, 2025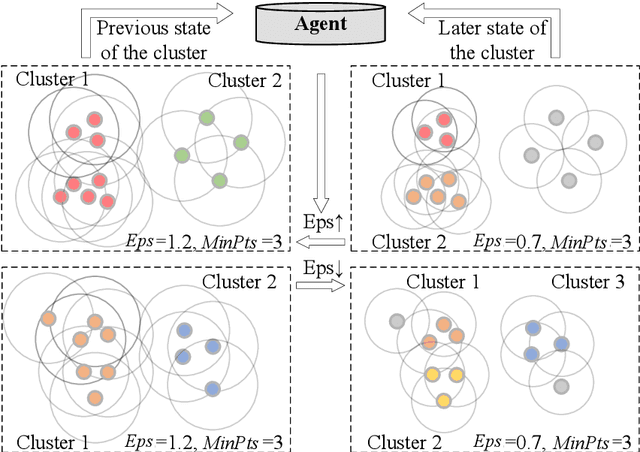

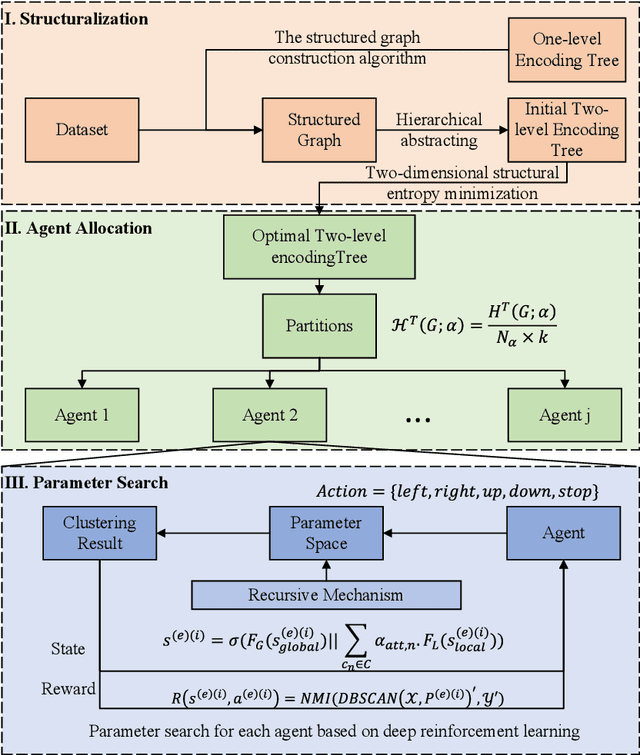

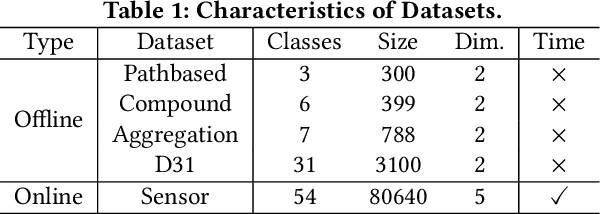
DBSCAN, a well-known density-based clustering algorithm, has gained widespread popularity and usage due to its effectiveness in identifying clusters of arbitrary shapes and handling noisy data. However, it encounters challenges in producing satisfactory cluster results when confronted with datasets of varying density scales, a common scenario in real-world applications. In this paper, we propose a novel Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning cluster framework, namely AR-DBSCAN. First, we model the initial dataset as a two-level encoding tree and categorize the data vertices into distinct density partitions according to the information uncertainty determined in the encoding tree. Each partition is then assigned to an agent to find the best clustering parameters without manual assistance. The allocation is density-adaptive, enabling AR-DBSCAN to effectively handle diverse density distributions within the dataset by utilizing distinct agents for different partitions. Second, a multi-agent deep reinforcement learning guided automatic parameter searching process is designed. The process of adjusting the parameter search direction by perceiving the clustering environment is modeled as a Markov decision process. Using a weakly-supervised reward training policy network, each agent adaptively learns the optimal clustering parameters by interacting with the clusters. Third, a recursive search mechanism adaptable to the data's scale is presented, enabling efficient and controlled exploration of large parameter spaces. Extensive experiments are conducted on nine artificial datasets and a real-world dataset. The results of offline and online tasks show that AR-DBSCAN not only improves clustering accuracy by up to 144.1% and 175.3% in the NMI and ARI metrics, respectively, but also is capable of robustly finding dominant parameters.
Automating DBSCAN via Deep Reinforcement Learning
Aug 09, 2022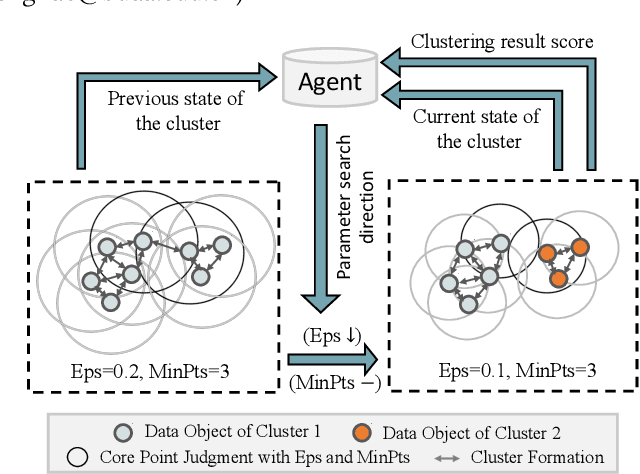
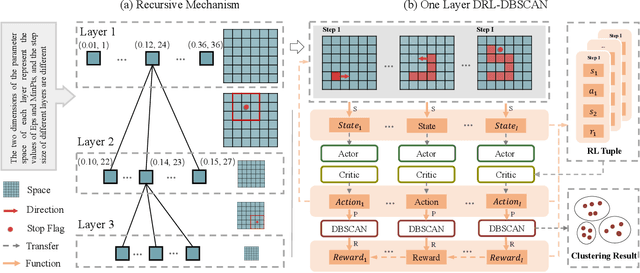

DBSCAN is widely used in many scientific and engineering fields because of its simplicity and practicality. However, due to its high sensitivity parameters, the accuracy of the clustering result depends heavily on practical experience. In this paper, we first propose a novel Deep Reinforcement Learning guided automatic DBSCAN parameters search framework, namely DRL-DBSCAN. The framework models the process of adjusting the parameter search direction by perceiving the clustering environment as a Markov decision process, which aims to find the best clustering parameters without manual assistance. DRL-DBSCAN learns the optimal clustering parameter search policy for different feature distributions via interacting with the clusters, using a weakly-supervised reward training policy network. In addition, we also present a recursive search mechanism driven by the scale of the data to efficiently and controllably process large parameter spaces. Extensive experiments are conducted on five artificial and real-world datasets based on the proposed four working modes. The results of offline and online tasks show that the DRL-DBSCAN not only consistently improves DBSCAN clustering accuracy by up to 26% and 25% respectively, but also can stably find the dominant parameters with high computational efficiency. The code is available at https://github.com/RingBDStack/DRL-DBSCAN.
Benchmarking Node Outlier Detection on Graphs
Jun 21, 2022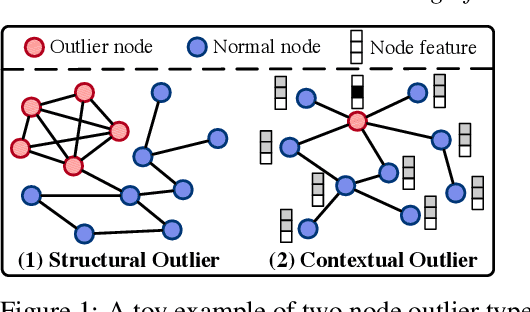
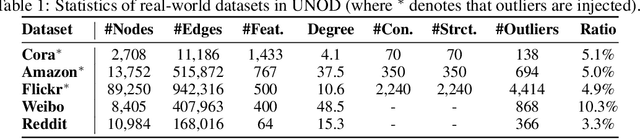

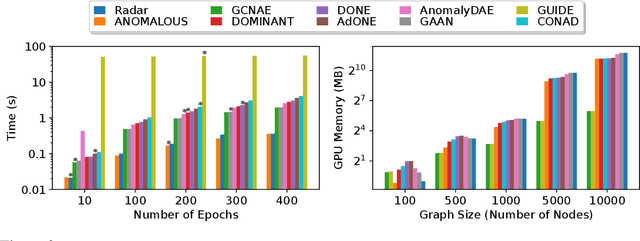
Graph outlier detection is an emerging but crucial machine learning task with numerous applications. Despite the proliferation of algorithms developed in recent years, the lack of a standard and unified setting for performance evaluation limits their advancement and usage in real-world applications. To tap the gap, we present, (to our best knowledge) the first comprehensive unsupervised node outlier detection benchmark for graphs called UNOD, with the following highlights: (1) evaluating fourteen methods with backbone spanning from classical matrix factorization to the latest graph neural networks; (2) benchmarking the method performance with different types of injected outliers and organic outliers on real-world datasets; (3) comparing the efficiency and scalability of the algorithms by runtime and GPU memory usage on synthetic graphs at different scales. Based on the analyses of extensive experimental results, we discuss the pros and cons of current UNOD methods, and point out multiple crucial and promising future research directions.
PyGOD: A Python Library for Graph Outlier Detection
Apr 26, 2022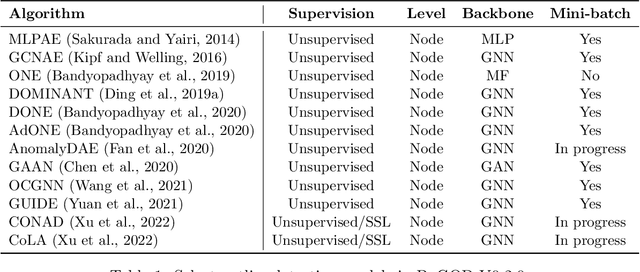
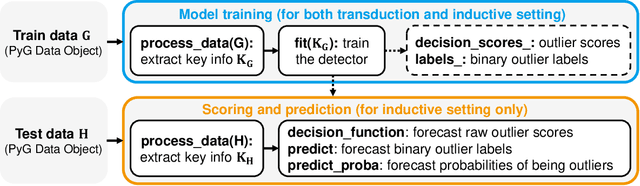
PyGOD is an open-source Python library for detecting outliers on graph data. As the first comprehensive library of its kind, PyGOD supports a wide array of leading graph-based methods for node-, edge-, subgraph-, and graph-level outlier detection, under a unified, well-documented API designed for use by both researchers and practitioners. To overcome the scalability issue in large graphs, we provide advanced functionalities for selected models, including mini-batch and sampling. PyGOD is equipped with best practices to foster code reliability and maintainability, including unit testing, continuous integration, and code coverage. To foster accessibility, PyGOD is released under a permissive BSD-license at https://github.com/pygod-team/pygod/ and the Python Package Index (PyPI).
Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks
Apr 16, 2021
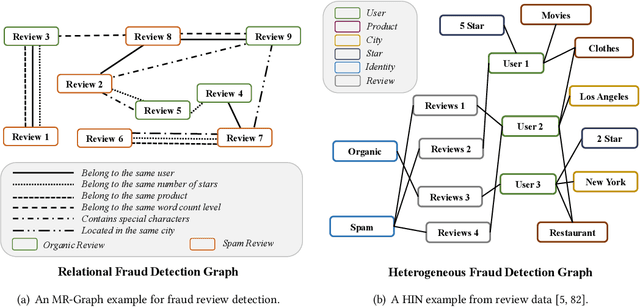
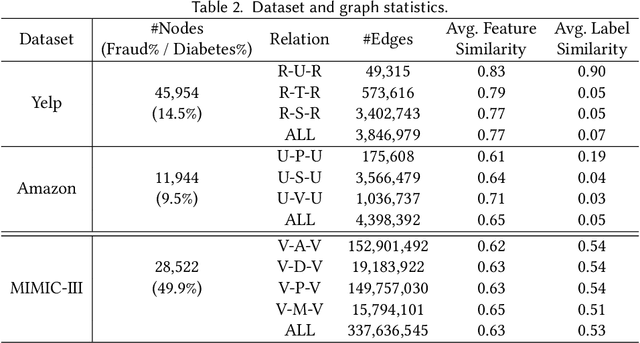
Graph Neural Networks (GNNs) have been widely used for the representation learning of various structured graph data, typically through message passing among nodes by aggregating their neighborhood information via different operations. While promising, most existing GNNs oversimplified the complexity and diversity of the edges in the graph, and thus inefficient to cope with ubiquitous heterogeneous graphs, which are typically in the form of multi-relational graph representations. In this paper, we propose RioGNN, a novel Reinforced, recursive and flexible neighborhood selection guided multi-relational Graph Neural Network architecture, to navigate complexity of neural network structures whilst maintaining relation-dependent representations. We first construct a multi-relational graph, according to the practical task, to reflect the heterogeneity of nodes, edges, attributes and labels. To avoid the embedding over-assimilation among different types of nodes, we employ a label-aware neural similarity measure to ascertain the most similar neighbors based on node attributes. A reinforced relation-aware neighbor selection mechanism is developed to choose the most similar neighbors of a targeting node within a relation before aggregating all neighborhood information from different relations to obtain the eventual node embedding. Particularly, to improve the efficiency of neighbor selecting, we propose a new recursive and scalable reinforcement learning framework with estimable depth and width for different scales of multi-relational graphs. RioGNN can learn more discriminative node embedding with enhanced explainability due to the recognition of individual importance of each relation via the filtering threshold mechanism.