 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Audio-Visual Quality Assessment Dataset via Crowdsourcing
Feb 26, 2026Audio-visual quality assessment (AVQA) research has been stalled by limitations of existing datasets: they are typically small in scale, with insufficient diversity in content and quality, and annotated only with overall scores. These shortcomings provide limited support for model development and multimodal perception research. We propose a practical approach for AVQA dataset construction. First, we design a crowdsourced subjective experiment framework for AVQA, breaks the constraints of in-lab settings and achieves reliable annotation across varied environments. Second, a systematic data preparation strategy is further employed to ensure broad coverage of both quality levels and semantic scenarios. Third, we extend the dataset with additional annotations, enabling research on multimodal perception mechanisms and their relation to content. Finally, we validate this approach through YT-NTU-AVQ, the largest and most diverse AVQA dataset to date, consisting of 1,620 user-generated audio and video (A/V) sequences. The dataset and platform code are available at https://github.com/renyu12/YT-NTU-AVQ
SeBot: Structural Entropy Guided Multi-View Contrastive Learning for Social Bot Detection
May 18, 2024



Recent advancements in social bot detection have been driven by the adoption of Graph Neural Networks. The social graph, constructed from social network interactions, contains benign and bot accounts that influence each other. However, previous graph-based detection methods that follow the transductive message-passing paradigm may not fully utilize hidden graph information and are vulnerable to adversarial bot behavior. The indiscriminate message passing between nodes from different categories and communities results in excessively homogeneous node representations, ultimately reducing the effectiveness of social bot detectors. In this paper, we propose SEBot, a novel multi-view graph-based contrastive learning-enabled social bot detector. In particular, we use structural entropy as an uncertainty metric to optimize the entire graph's structure and subgraph-level granularity, revealing the implicitly existing hierarchical community structure. And we design an encoder to enable message passing beyond the homophily assumption, enhancing robustness to adversarial behaviors of social bots. Finally, we employ multi-view contrastive learning to maximize mutual information between different views and enhance the detection performance through multi-task learning. Experimental results demonstrate that our approach significantly improves the performance of social bot detection compared with SOTA methods.
BotDGT: Dynamicity-aware Social Bot Detection with Dynamic Graph Transformers
Apr 24, 2024



Detecting social bots has evolved into a pivotal yet intricate task, aimed at combating the dissemination of misinformation and preserving the authenticity of online interactions. While earlier graph-based approaches, which leverage topological structure of social networks, yielded notable outcomes, they overlooked the inherent dynamicity of social networks -- In reality, they largely depicted the social network as a static graph and solely relied on its most recent state. Due to the absence of dynamicity modeling, such approaches are vulnerable to evasion, particularly when advanced social bots interact with other users to camouflage identities and escape detection. To tackle these challenges, we propose BotDGT, a novel framework that not only considers the topological structure, but also effectively incorporates dynamic nature of social network. Specifically, we characterize a social network as a dynamic graph. A structural module is employed to acquire topological information from each historical snapshot. Additionally, a temporal module is proposed to integrate historical context and model the evolving behavior patterns exhibited by social bots and legitimate users. Experimental results demonstrate the superiority of BotDGT against the leading methods that neglected the dynamic nature of social networks in terms of accuracy, recall, and F1-score.
SE-GSL: A General and Effective Graph Structure Learning Framework through Structural Entropy Optimization
Mar 17, 2023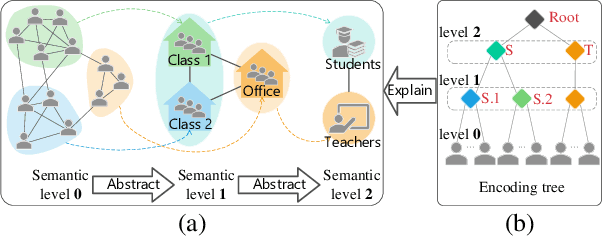
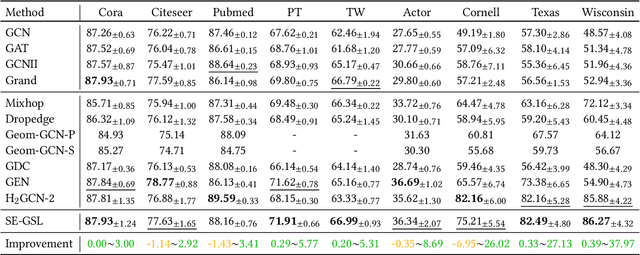
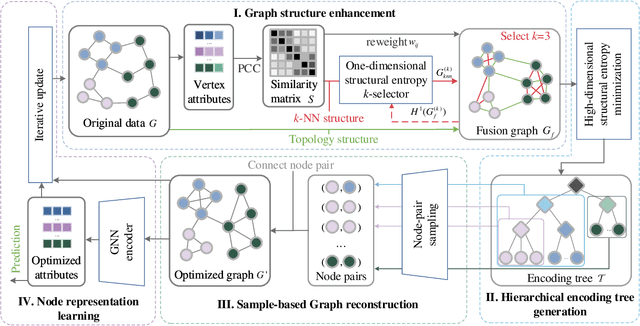
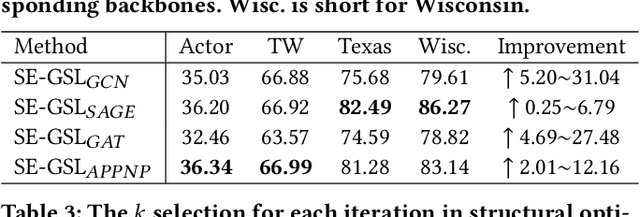
Graph Neural Networks (GNNs) are de facto solutions to structural data learning. However, it is susceptible to low-quality and unreliable structure, which has been a norm rather than an exception in real-world graphs. Existing graph structure learning (GSL) frameworks still lack robustness and interpretability. This paper proposes a general GSL framework, SE-GSL, through structural entropy and the graph hierarchy abstracted in the encoding tree. Particularly, we exploit the one-dimensional structural entropy to maximize embedded information content when auxiliary neighbourhood attributes are fused to enhance the original graph. A new scheme of constructing optimal encoding trees is proposed to minimize the uncertainty and noises in the graph whilst assuring proper community partition in hierarchical abstraction. We present a novel sample-based mechanism for restoring the graph structure via node structural entropy distribution. It increases the connectivity among nodes with larger uncertainty in lower-level communities. SE-GSL is compatible with various GNN models and enhances the robustness towards noisy and heterophily structures. Extensive experiments show significant improvements in the effectiveness and robustness of structure learning and node representation learning.
FedACK: Federated Adversarial Contrastive Knowledge Distillation for Cross-Lingual and Cross-Model Social Bot Detection
Mar 10, 2023



Social bot detection is of paramount importance to the resilience and security of online social platforms. The state-of-the-art detection models are siloed and have largely overlooked a variety of data characteristics from multiple cross-lingual platforms. Meanwhile, the heterogeneity of data distribution and model architecture makes it intricate to devise an efficient cross-platform and cross-model detection framework. In this paper, we propose FedACK, a new federated adversarial contrastive knowledge distillation framework for social bot detection. We devise a GAN-based federated knowledge distillation mechanism for efficiently transferring knowledge of data distribution among clients. In particular, a global generator is used to extract the knowledge of global data distribution and distill it into each client's local model. We leverage local discriminator to enable customized model design and use local generator for data enhancement with hard-to-decide samples. Local training is conducted as multi-stage adversarial and contrastive learning to enable consistent feature spaces among clients and to constrain the optimization direction of local models, reducing the divergences between local and global models. Experiments demonstrate that FedACK outperforms the state-of-the-art approaches in terms of accuracy, communication efficiency, and feature space consistency.
Enhancing High-dimensional Bayesian Optimization by Optimizing the Acquisition Function Maximizer Initialization
Feb 16, 2023



Bayesian optimization (BO) is widely used to optimize black-box functions. It works by first building a surrogate for the objective and quantifying the uncertainty in that surrogate. It then decides where to sample by maximizing an acquisition function defined by the surrogate model. Prior approaches typically use randomly generated raw samples to initialize the acquisition function maximizer. However, this strategy is ill-suited for high-dimensional BO. Given the large regions of high posterior uncertainty in high dimensions, a randomly initialized acquisition function maximizer is likely to focus on areas with high posterior uncertainty, leading to overly exploring areas that offer little gain. This paper provides the first comprehensive empirical study to reveal the importance of the initialization phase of acquisition function maximization. It proposes a better initialization approach by employing multiple heuristic optimizers to leverage the knowledge of already evaluated samples to generate initial points to be explored by an acquisition function maximizer. We evaluate our approach on widely used synthetic test functions and real-world applications. Experimental results show that our techniques, while simple, can significantly enhance the standard BO and outperforms state-of-the-art high-dimensional BO techniques by a large margin in most test cases.
RoSGAS: Adaptive Social Bot Detection with Reinforced Self-Supervised GNN Architecture Search
Jun 14, 2022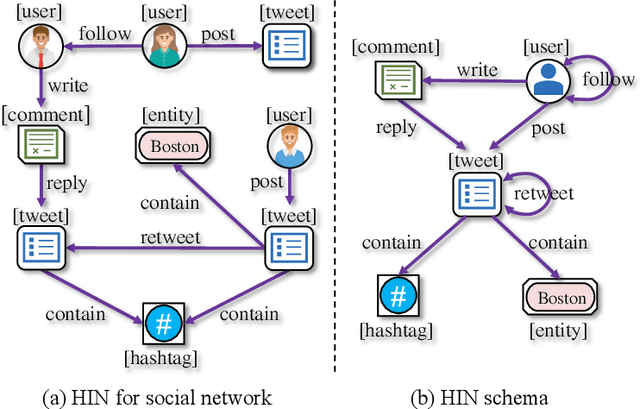
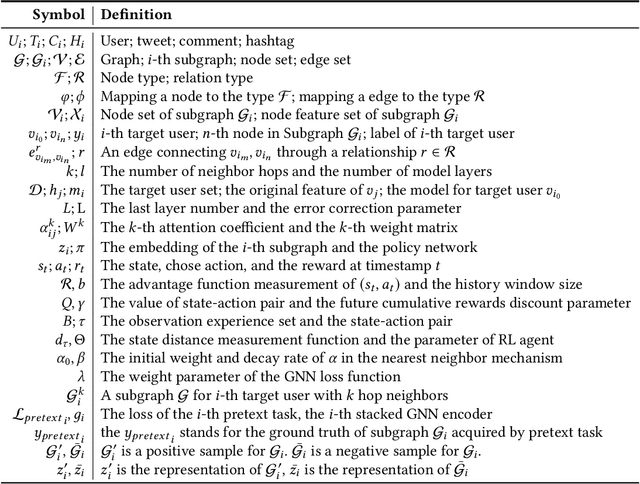
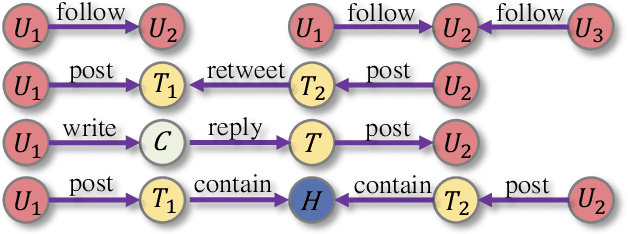
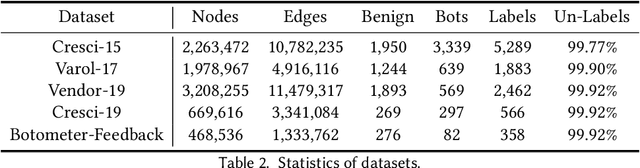
Social bots are referred to as the automated accounts on social networks that make attempts to behave like human. While Graph Neural Networks (GNNs) has been massively applied to the field of social bot detection, a huge amount of domain expertise and prior knowledge is heavily engaged in the state-of-the art approaches to design a dedicated neural network architecture for a specific classification task. Involving oversized nodes and network layers in the model design, however, usually causes the over-smoothing problem and the lack of embedding discrimination. In this paper, we propose RoSGAS, a novel Reinforced and Self-supervised GNN Architecture Search framework to adaptively pinpoint the most suitable multi-hop neighborhood and the number of layers in the GNN architecture. More specifically, we consider the social bot detection problem as a user-centric subgraph embedding and classification task. We exploit heterogeneous information network to present the user connectivity by leveraging account metadata, relationships, behavioral features and content features. RoSGAS uses a multi-agent deep reinforcement learning (RL) mechanism for navigating the search of optimal neighborhood and network layers to learn individually the subgraph embedding for each target user. A nearest neighbor mechanism is developed for accelerating the RL training process, and RoSGAS can learn more discriminative subgraph embedding with the aid of self-supervised learning. Experiments on 5 Twitter datasets show that RoSGAS outperforms the state-of-the-art approaches in terms of accuracy, training efficiency and stability, and has better generalization when handling unseen samples.
Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks
Apr 16, 2021
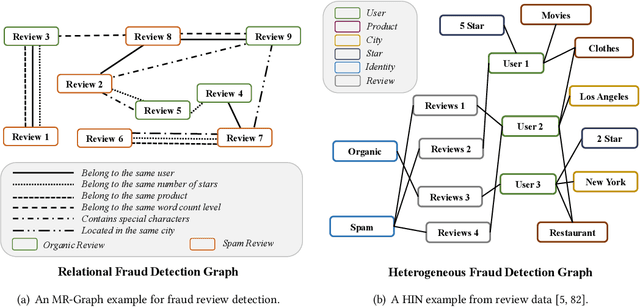
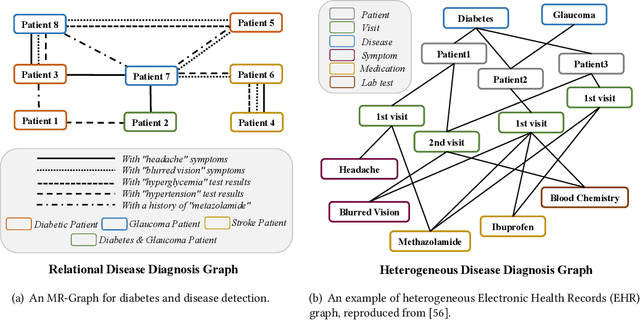
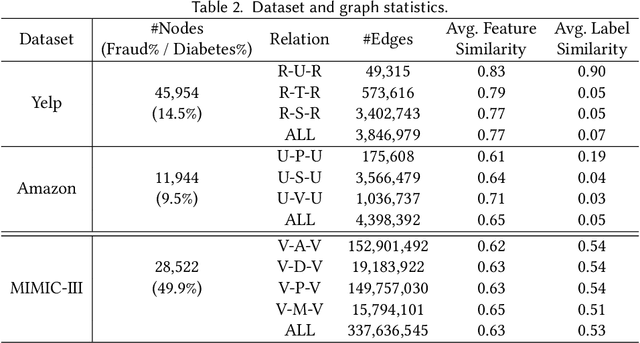
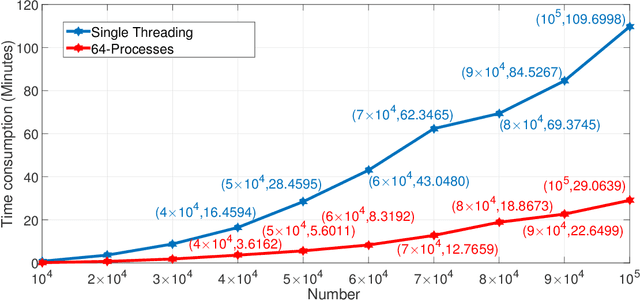
Graph Neural Networks (GNNs) have been widely used for the representation learning of various structured graph data, typically through message passing among nodes by aggregating their neighborhood information via different operations. While promising, most existing GNNs oversimplified the complexity and diversity of the edges in the graph, and thus inefficient to cope with ubiquitous heterogeneous graphs, which are typically in the form of multi-relational graph representations. In this paper, we propose RioGNN, a novel Reinforced, recursive and flexible neighborhood selection guided multi-relational Graph Neural Network architecture, to navigate complexity of neural network structures whilst maintaining relation-dependent representations. We first construct a multi-relational graph, according to the practical task, to reflect the heterogeneity of nodes, edges, attributes and labels. To avoid the embedding over-assimilation among different types of nodes, we employ a label-aware neural similarity measure to ascertain the most similar neighbors based on node attributes. A reinforced relation-aware neighbor selection mechanism is developed to choose the most similar neighbors of a targeting node within a relation before aggregating all neighborhood information from different relations to obtain the eventual node embedding. Particularly, to improve the efficiency of neighbor selecting, we propose a new recursive and scalable reinforcement learning framework with estimable depth and width for different scales of multi-relational graphs. RioGNN can learn more discriminative node embedding with enhanced explainability due to the recognition of individual importance of each relation via the filtering threshold mechanism.
Streaming Social Event Detection and Evolution Discovery in Heterogeneous Information Networks
Apr 02, 2021
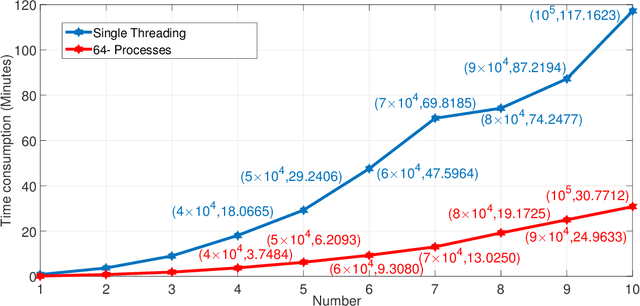
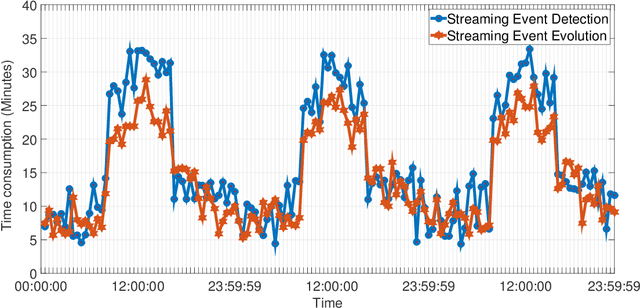
Events are happening in real-world and real-time, which can be planned and organized for occasions, such as social gatherings, festival celebrations, influential meetings or sports activities. Social media platforms generate a lot of real-time text information regarding public events with different topics. However, mining social events is challenging because events typically exhibit heterogeneous texture and metadata are often ambiguous. In this paper, we first design a novel event-based meta-schema to characterize the semantic relatedness of social events and then build an event-based heterogeneous information network (HIN) integrating information from external knowledge base. Second, we propose a novel Pairwise Popularity Graph Convolutional Network, named as PP-GCN, based on weighted meta-path instance similarity and textual semantic representation as inputs, to perform fine-grained social event categorization and learn the optimal weights of meta-paths in different tasks. Third, we propose a streaming social event detection and evolution discovery framework for HINs based on meta-path similarity search, historical information about meta-paths, and heterogeneous DBSCAN clustering method. Comprehensive experiments on real-world streaming social text data are conducted to compare various social event detection and evolution discovery algorithms. Experimental results demonstrate that our proposed framework outperforms other alternative social event detection and evolution discovery techniques.
Lifelong Property Price Prediction: A Case Study for the Toronto Real Estate Market
Aug 12, 2020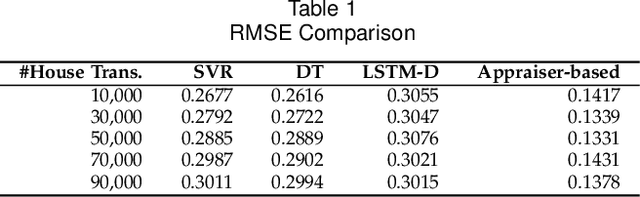
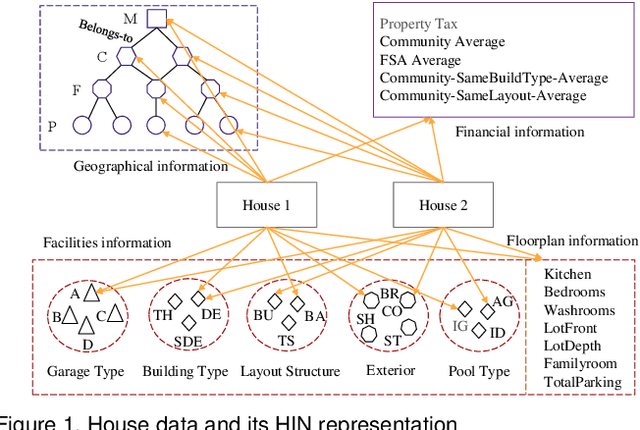

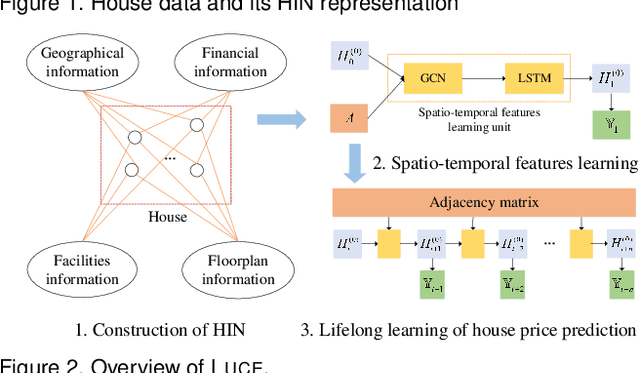
We present Luce, the first life-long predictive model for automated property valuation. Luce addresses two critical issues of property valuation: the lack of recent sold prices and the sparsity of house data. It is designed to operate on a limited volume of recent house transaction data. As a departure from prior work, Luce organizes the house data in a heterogeneous information network (HIN) where graph nodes are house entities and attributes that are important for house price valuation. We employ a Graph Convolutional Network (GCN) to extract the spatial information from the HIN for house-related data like geographical locations, and then use a Long Short Term Memory (LSTM) network to model the temporal dependencies for house transaction data over time. Unlike prior work, Luce can make effective use of the limited house transactions data in the past few months to update valuation information for all house entities within the HIN. By providing a complete and up-to-date house valuation dataset, Luce thus massively simplifies the downstream valuation task for the targeting properties. We demonstrate the benefit of Luce by applying it to large, real-life datasets obtained from the Toronto real estate market. Extensive experimental results show that Luce not only significantly outperforms prior property valuation methods but also often reaches and sometimes exceeds the valuation accuracy given by independent experts when using the actual realization price as the ground truth.