 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Field Control on Sparse Graphs: From Local Limits to GNNs via Neighborhood Distributions
Jan 29, 2026Mean-field control (MFC) offers a scalable solution to the curse of dimensionality in multi-agent systems but traditionally hinges on the restrictive assumption of exchangeability via dense, all-to-all interactions. In this work, we bridge the gap to real-world network structures by proposing a rigorous framework for MFC on large sparse graphs. We redefine the system state as a probability measure over decorated rooted neighborhoods, effectively capturing local heterogeneity. Our central contribution is a theoretical foundation for scalable reinforcement learning in this setting. We prove horizon-dependent locality: for finite-horizon problems, an agent's optimal policy at time t depends strictly on its (T-t)-hop neighborhood. This result renders the infinite-dimensional control problem tractable and underpins a novel Dynamic Programming Principle (DPP) on the lifted space of neighborhood distributions. Furthermore, we formally and experimentally justify the use of Graph Neural Networks (GNNs) for actor-critic algorithms in this context. Our framework naturally recovers classical MFC as a degenerate case while enabling efficient, theoretically grounded control on complex sparse topologies.
PhysioSync: Temporal and Cross-Modal Contrastive Learning Inspired by Physiological Synchronization for EEG-Based Emotion Recognition
Apr 24, 2025Electroencephalography (EEG) signals provide a promising and involuntary reflection of brain activity related to emotional states, offering significant advantages over behavioral cues like facial expressions. However, EEG signals are often noisy, affected by artifacts, and vary across individuals, complicating emotion recognition. While multimodal approaches have used Peripheral Physiological Signals (PPS) like GSR to complement EEG, they often overlook the dynamic synchronization and consistent semantics between the modalities. Additionally, the temporal dynamics of emotional fluctuations across different time resolutions in PPS remain underexplored. To address these challenges, we propose PhysioSync, a novel pre-training framework leveraging temporal and cross-modal contrastive learning, inspired by physiological synchronization phenomena. PhysioSync incorporates Cross-Modal Consistency Alignment (CM-CA) to model dynamic relationships between EEG and complementary PPS, enabling emotion-related synchronizations across modalities. Besides, it introduces Long- and Short-Term Temporal Contrastive Learning (LS-TCL) to capture emotional synchronization at different temporal resolutions within modalities. After pre-training, cross-resolution and cross-modal features are hierarchically fused and fine-tuned to enhance emotion recognition. Experiments on DEAP and DREAMER datasets demonstrate PhysioSync's advanced performance under uni-modal and cross-modal conditions, highlighting its effectiveness for EEG-centered emotion recognition.
Learning Mean Field Control on Sparse Graphs
Jan 28, 2025



Large agent networks are abundant in applications and nature and pose difficult challenges in the field of multi-agent reinforcement learning (MARL) due to their computational and theoretical complexity. While graphon mean field games and their extensions provide efficient learning algorithms for dense and moderately sparse agent networks, the case of realistic sparser graphs remains largely unsolved. Thus, we propose a novel mean field control model inspired by local weak convergence to include sparse graphs such as power law networks with coefficients above two. Besides a theoretical analysis, we design scalable learning algorithms which apply to the challenging class of graph sequences with finite first moment. We compare our model and algorithms for various examples on synthetic and real world networks with mean field algorithms based on Lp graphons and graphexes. As it turns out, our approach outperforms existing methods in many examples and on various networks due to the special design aiming at an important, but so far hard to solve class of MARL problems.
Bounded Rationality Equilibrium Learning in Mean Field Games
Nov 11, 2024



Mean field games (MFGs) tractably model behavior in large agent populations. The literature on learning MFG equilibria typically focuses on finding Nash equilibria (NE), which assume perfectly rational agents and are hence implausible in many realistic situations. To overcome these limitations, we incorporate bounded rationality into MFGs by leveraging the well-known concept of quantal response equilibria (QRE). Two novel types of MFG QRE enable the modeling of large agent populations where individuals only noisily estimate the true objective. We also introduce a second source of bounded rationality to MFGs by restricting agents' planning horizon. The resulting novel receding horizon (RH) MFGs are combined with QRE and existing approaches to model different aspects of bounded rationality in MFGs. We formally define MFG QRE and RH MFGs and compare them to existing equilibrium concepts such as entropy-regularized NE. Subsequently, we design generalized fixed point iteration and fictitious play algorithms to learn QRE and RH equilibria. After a theoretical analysis, we give different examples to evaluate the capabilities of our learning algorithms and outline practical differences between the equilibrium concepts.
FPGA-Based Neural Thrust Controller for UAVs
Mar 28, 2024The advent of unmanned aerial vehicles (UAVs) has improved a variety of fields by providing a versatile, cost-effective and accessible platform for implementing state-of-the-art algorithms. To accomplish a broader range of tasks, there is a growing need for enhanced on-board computing to cope with increasing complexity and dynamic environmental conditions. Recent advances have seen the application of Deep Neural Networks (DNNs), particularly in combination with Reinforcement Learning (RL), to improve the adaptability and performance of UAVs, especially in unknown environments. However, the computational requirements of DNNs pose a challenge to the limited computing resources available on many UAVs. This work explores the use of Field Programmable Gate Arrays (FPGAs) as a viable solution to this challenge, offering flexibility, high performance, energy and time efficiency. We propose a novel hardware board equipped with an Artix-7 FPGA for a popular open-source micro-UAV platform. We successfully validate its functionality by implementing an RL-based low-level controller using real-world experiments.
A Modular Aerial System Based on Homogeneous Quadrotors with Fault-Tolerant Control
Feb 02, 2024The standard quadrotor is one of the most popular and widely used aerial vehicle of recent decades, offering great maneuverability with mechanical simplicity. However, the under-actuation characteristic limits its applications, especially when it comes to generating desired wrench with six degrees of freedom (DOF). Therefore, existing work often compromises between mechanical complexity and the controllable DOF of the aerial system. To take advantage of the mechanical simplicity of a standard quadrotor, we propose a modular aerial system, IdentiQuad, that combines only homogeneous quadrotor-based modules. Each IdentiQuad can be operated alone like a standard quadrotor, but at the same time allows task-specific assembly, increasing the controllable DOF of the system. Each module is interchangeable within its assembly. We also propose a general controller for different configurations of assemblies, capable of tolerating rotor failures and balancing the energy consumption of each module. The functionality and robustness of the system and its controller are validated using physics-based simulations for different assembly configurations.
Learning Mean Field Games on Sparse Graphs: A Hybrid Graphex Approach
Jan 23, 2024



Learning the behavior of large agent populations is an important task for numerous research areas. Although the field of multi-agent reinforcement learning (MARL) has made significant progress towards solving these systems, solutions for many agents often remain computationally infeasible and lack theoretical guarantees. Mean Field Games (MFGs) address both of these issues and can be extended to Graphon MFGs (GMFGs) to include network structures between agents. Despite their merits, the real world applicability of GMFGs is limited by the fact that graphons only capture dense graphs. Since most empirically observed networks show some degree of sparsity, such as power law graphs, the GMFG framework is insufficient for capturing these network topologies. Thus, we introduce the novel concept of Graphex MFGs (GXMFGs) which builds on the graph theoretical concept of graphexes. Graphexes are the limiting objects to sparse graph sequences that also have other desirable features such as the small world property. Learning equilibria in these games is challenging due to the rich and sparse structure of the underlying graphs. To tackle these challenges, we design a new learning algorithm tailored to the GXMFG setup. This hybrid graphex learning approach leverages that the system mainly consists of a highly connected core and a sparse periphery. After defining the system and providing a theoretical analysis, we state our learning approach and demonstrate its learning capabilities on both synthetic graphs and real-world networks. This comparison shows that our GXMFG learning algorithm successfully extends MFGs to a highly relevant class of hard, realistic learning problems that are not accurately addressed by current MARL and MFG methods.
Collaborative Optimization of the Age of Information under Partial Observability
Dec 20, 2023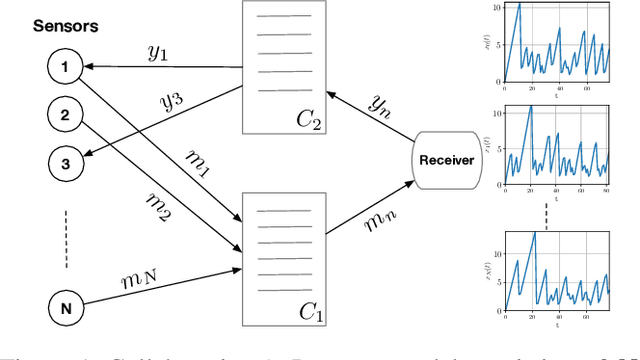
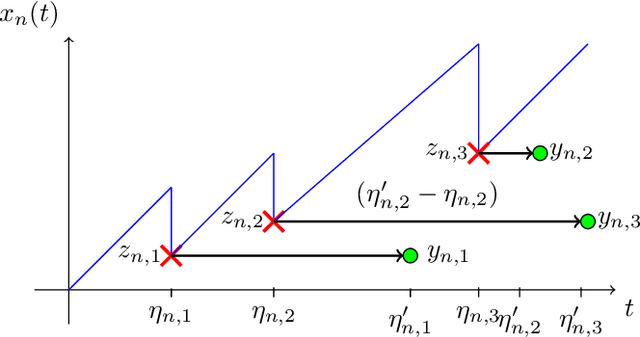
The significance of the freshness of sensor and control data at the receiver side, often referred to as Age of Information (AoI), is fundamentally constrained by contention for limited network resources. Evidently, network congestion is detrimental for AoI, where this congestion is partly self-induced by the sensor transmission process in addition to the contention from other transmitting sensors. In this work, we devise a decentralized AoI-minimizing transmission policy for a number of sensor agents sharing capacity-limited, non-FIFO duplex channels that introduce random delays in communication with a common receiver. By implementing the same policy, however with no explicit inter-agent communication, the agents minimize the expected AoI in this partially observable system. We cater to the partial observability due to random channel delays by designing a bootstrap particle filter that independently maintains a belief over the AoI of each agent. We also leverage mean-field control approximations and reinforcement learning to derive scalable and optimal solutions for minimizing the expected AoI collaboratively.
Sparse Mean Field Load Balancing in Large Localized Queueing Systems
Dec 20, 2023Scalable load balancing algorithms are of great interest in cloud networks and data centers, necessitating the use of tractable techniques to compute optimal load balancing policies for good performance. However, most existing scalable techniques, especially asymptotically scaling methods based on mean field theory, have not been able to model large queueing networks with strong locality. Meanwhile, general multi-agent reinforcement learning techniques can be hard to scale and usually lack a theoretical foundation. In this work, we address this challenge by leveraging recent advances in sparse mean field theory to learn a near-optimal load balancing policy in sparsely connected queueing networks in a tractable manner, which may be preferable to global approaches in terms of communication overhead. Importantly, we obtain a general load balancing framework for a large class of sparse bounded-degree topologies. By formulating a novel mean field control problem in the context of graphs with bounded degree, we reduce the otherwise difficult multi-agent problem to a single-agent problem. Theoretically, the approach is justified by approximation guarantees. Empirically, the proposed methodology performs well on several realistic and scalable network topologies. Moreover, we compare it with a number of well-known load balancing heuristics and with existing scalable multi-agent reinforcement learning methods. Overall, we obtain a tractable approach for load balancing in highly localized networks.
Learning Discrete-Time Major-Minor Mean Field Games
Dec 17, 2023



Recent techniques based on Mean Field Games (MFGs) allow the scalable analysis of multi-player games with many similar, rational agents. However, standard MFGs remain limited to homogeneous players that weakly influence each other, and cannot model major players that strongly influence other players, severely limiting the class of problems that can be handled. We propose a novel discrete time version of major-minor MFGs (M3FGs), along with a learning algorithm based on fictitious play and partitioning the probability simplex. Importantly, M3FGs generalize MFGs with common noise and can handle not only random exogeneous environment states but also major players. A key challenge is that the mean field is stochastic and not deterministic as in standard MFGs. Our theoretical investigation verifies both the M3FG model and its algorithmic solution, showing firstly the well-posedness of the M3FG model starting from a finite game of interest, and secondly convergence and approximation guarantees of the fictitious play algorithm. Then, we empirically verify the obtained theoretical results, ablating some of the theoretical assumptions made, and show successful equilibrium learning in three example problems. Overall, we establish a learning framework for a novel and broad class of tractable games.