 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Compression of Point Cloud Geometry and Attributes in a Single Model through Multimodal Rate-Control
Aug 01, 2024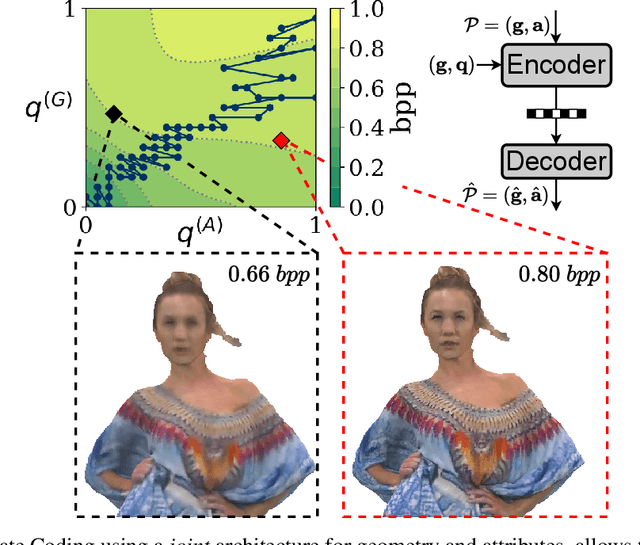


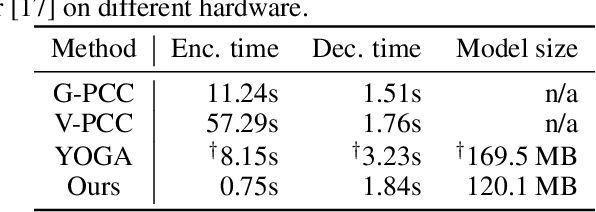
Point cloud compression is essential to experience volumetric multimedia as it drastically reduces the required streaming data rates. Point attributes, specifically colors, extend the challenge of lossy compression beyond geometric representation to achieving joint reconstruction of texture and geometry. State-of-the-art methods separate geometry and attributes to compress them individually. This comes at a computational cost, requiring an encoder and a decoder for each modality. Additionally, as attribute compression methods require the same geometry for encoding and decoding, the encoder emulates the decoder-side geometry reconstruction as an input step to project and compress the attributes. In this work, we propose to learn joint compression of geometry and attributes using a single, adaptive autoencoder model, embedding both modalities into a unified latent space which is then entropy encoded. Key to the technique is to replace the search for trade-offs between rate, attribute quality and geometry quality, through conditioning the model on the desired qualities of both modalities, bypassing the need for training model ensembles. To differentiate important point cloud regions during encoding or to allow view-dependent compression for user-centered streaming, conditioning is pointwise, which allows for local quality and rate variation. Our evaluation shows comparable performance to state-of-the-art compression methods for geometry and attributes, while reducing complexity compared to related compression methods.
Collaborative Optimization of the Age of Information under Partial Observability
Dec 20, 2023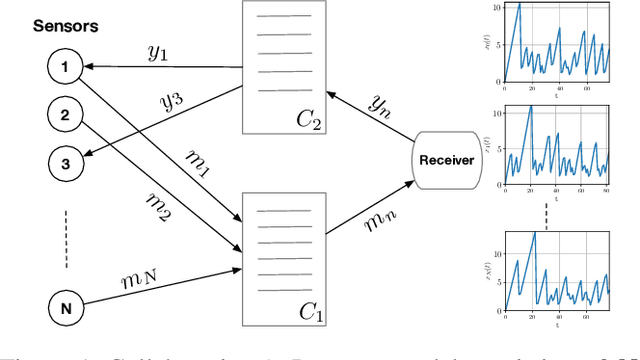
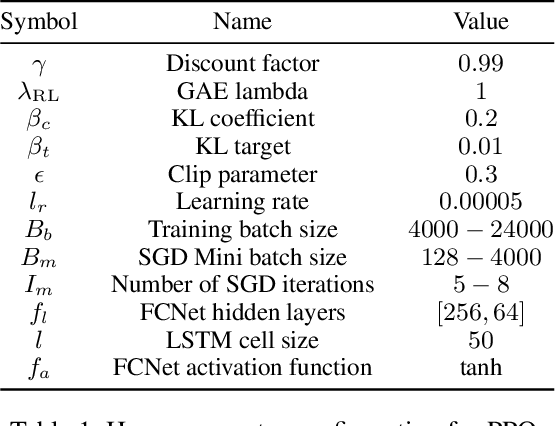
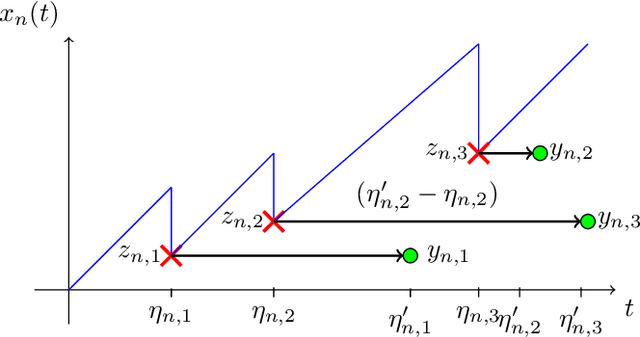
The significance of the freshness of sensor and control data at the receiver side, often referred to as Age of Information (AoI), is fundamentally constrained by contention for limited network resources. Evidently, network congestion is detrimental for AoI, where this congestion is partly self-induced by the sensor transmission process in addition to the contention from other transmitting sensors. In this work, we devise a decentralized AoI-minimizing transmission policy for a number of sensor agents sharing capacity-limited, non-FIFO duplex channels that introduce random delays in communication with a common receiver. By implementing the same policy, however with no explicit inter-agent communication, the agents minimize the expected AoI in this partially observable system. We cater to the partial observability due to random channel delays by designing a bootstrap particle filter that independently maintains a belief over the AoI of each agent. We also leverage mean-field control approximations and reinforcement learning to derive scalable and optimal solutions for minimizing the expected AoI collaboratively.
Scheduling in Parallel Finite Buffer Systems: Optimal Decisions under Delayed Feedback
Sep 17, 2021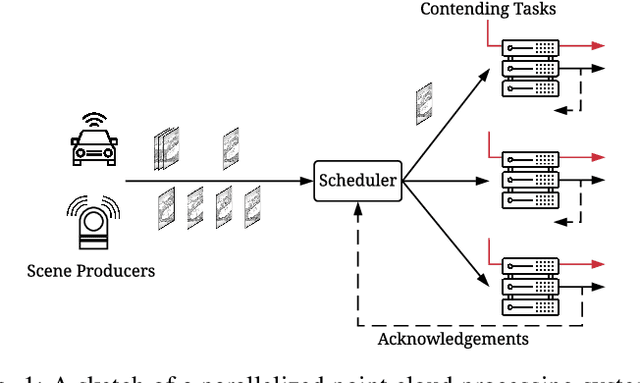
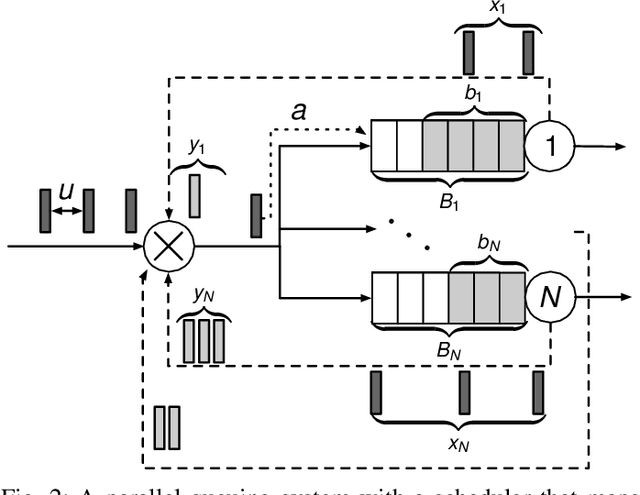
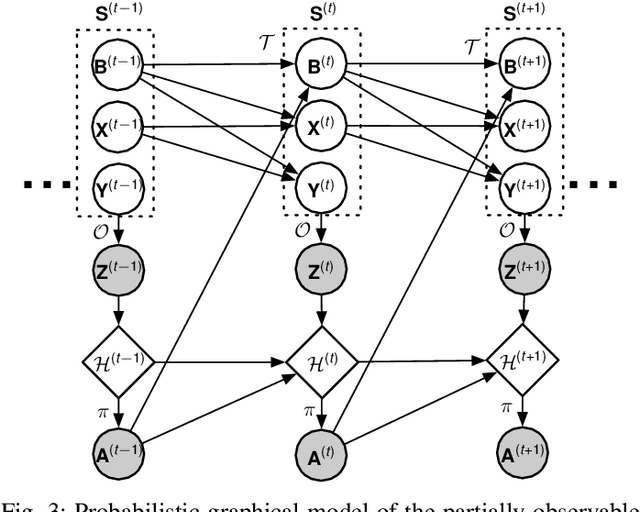

Scheduling decisions in parallel queuing systems arise as a fundamental problem, underlying the dimensioning and operation of many computing and communication systems, such as job routing in data center clusters, multipath communication, and Big Data systems. In essence, the scheduler maps each arriving job to one of the possibly heterogeneous servers while aiming at an optimization goal such as load balancing, low average delay or low loss rate. One main difficulty in finding optimal scheduling decisions here is that the scheduler only partially observes the impact of its decisions, e.g., through the delayed acknowledgements of the served jobs. In this paper, we provide a partially observable (PO) model that captures the scheduling decisions in parallel queuing systems under limited information of delayed acknowledgements. We present a simulation model for this PO system to find a near-optimal scheduling policy in real-time using a scalable Monte Carlo tree search algorithm. We numerically show that the resulting policy outperforms other limited information scheduling strategies such as variants of Join-the-Most-Observations and has comparable performance to full information strategies like: Join-the-Shortest-Queue, Join-the- Shortest-Queue(d) and Shortest-Expected-Delay. Finally, we show how our approach can optimise the real-time parallel processing by using network data provided by Kaggle.
Detection and Analysis of Content Creator Collaborations in YouTube Videos using Face- and Speaker-Recognition
Jul 05, 2018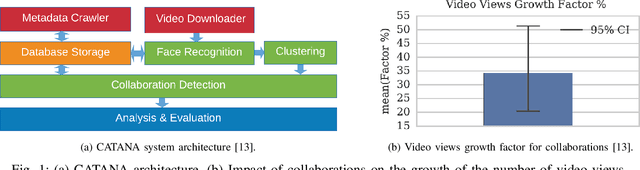
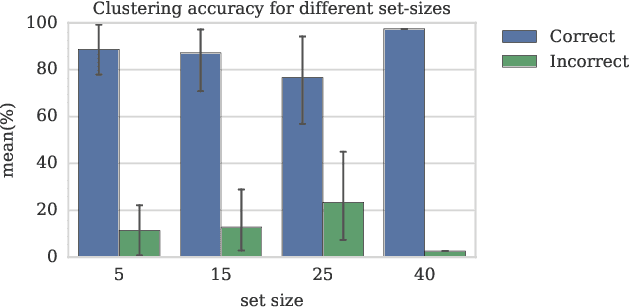

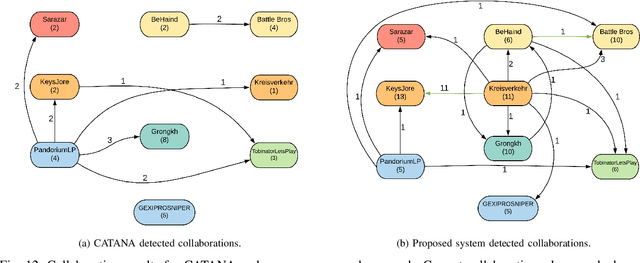
This work discusses and implements the application of speaker recognition for the detection of collaborations in YouTube videos. CATANA, an existing framework for detection and analysis of YouTube collaborations, is utilizing face recognition for the detection of collaborators, which naturally performs poor on video-content without appearing faces. This work proposes an extension of CATANA using active speaker detection and speaker recognition to improve the detection accuracy.
Collaborations on YouTube: From Unsupervised Detection to the Impact on Video and Channel Popularity
May 01, 2018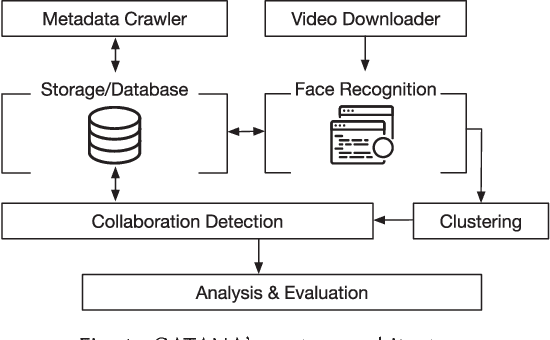
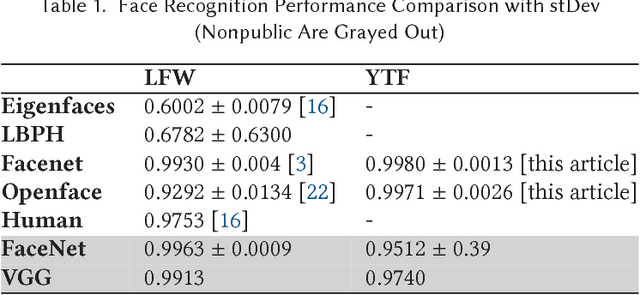
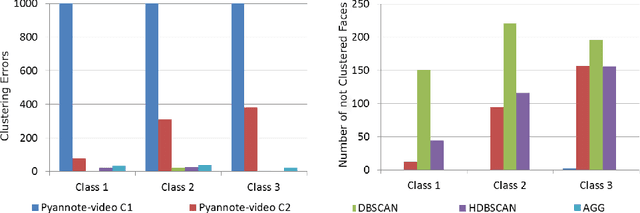

YouTube is one of the most popular platforms for streaming of user-generated video. Nowadays, professional YouTubers are organized in so called multi-channel networks (MCNs). These networks offer services such as brand deals, equipment, and strategic advice in exchange for a share of the YouTubers' revenue. A major strategy to gain more subscribers and, hence, revenue is collaborating with other YouTubers. Yet, collaborations on YouTube have not been studied in a detailed quantitative manner. This paper aims to close this gap with the following contributions. First, we collect a YouTube dataset covering video statistics over three months for 7,942 channels. Second, we design a framework for collaboration detection given a previously unknown number of persons featuring in YouTube videos. We denote this framework for the analysis of collaborations in YouTube videos using a Deep Neural Network (DNN) based approach as CATANA. Third, we analyze about 2.4 years of video content and use CATANA to answer research questions providing guidance for YouTubers and MCNs for efficient collaboration strategies. Thereby, we focus on (i) collaboration frequency and partner selectivity, (ii) the influence of MCNs on channel collaborations, (iii) collaborating channel types, and (iv) the impact of collaborations on video and channel popularity. Our results show that collaborations are in many cases significantly beneficial in terms of viewers and newly attracted subscribers for both collaborating channels, showing often more than 100% popularity growth compared with non-collaboration videos.