 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Compression of Point Cloud Geometry and Attributes in a Single Model through Multimodal Rate-Control
Paper and Code
Aug 01, 2024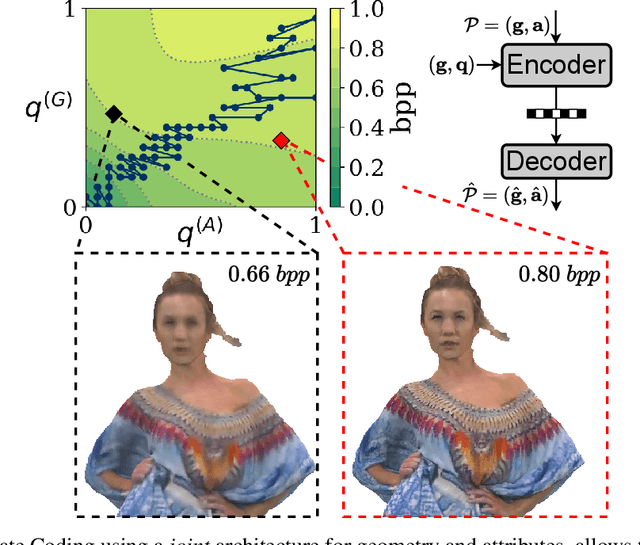


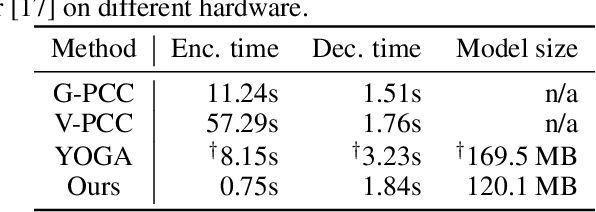
Point cloud compression is essential to experience volumetric multimedia as it drastically reduces the required streaming data rates. Point attributes, specifically colors, extend the challenge of lossy compression beyond geometric representation to achieving joint reconstruction of texture and geometry. State-of-the-art methods separate geometry and attributes to compress them individually. This comes at a computational cost, requiring an encoder and a decoder for each modality. Additionally, as attribute compression methods require the same geometry for encoding and decoding, the encoder emulates the decoder-side geometry reconstruction as an input step to project and compress the attributes. In this work, we propose to learn joint compression of geometry and attributes using a single, adaptive autoencoder model, embedding both modalities into a unified latent space which is then entropy encoded. Key to the technique is to replace the search for trade-offs between rate, attribute quality and geometry quality, through conditioning the model on the desired qualities of both modalities, bypassing the need for training model ensembles. To differentiate important point cloud regions during encoding or to allow view-dependent compression for user-centered streaming, conditioning is pointwise, which allows for local quality and rate variation. Our evaluation shows comparable performance to state-of-the-art compression methods for geometry and attributes, while reducing complexity compared to related compression methods.