 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Mean Field Load Balancing in Large Localized Queueing Systems
Dec 20, 2023Scalable load balancing algorithms are of great interest in cloud networks and data centers, necessitating the use of tractable techniques to compute optimal load balancing policies for good performance. However, most existing scalable techniques, especially asymptotically scaling methods based on mean field theory, have not been able to model large queueing networks with strong locality. Meanwhile, general multi-agent reinforcement learning techniques can be hard to scale and usually lack a theoretical foundation. In this work, we address this challenge by leveraging recent advances in sparse mean field theory to learn a near-optimal load balancing policy in sparsely connected queueing networks in a tractable manner, which may be preferable to global approaches in terms of communication overhead. Importantly, we obtain a general load balancing framework for a large class of sparse bounded-degree topologies. By formulating a novel mean field control problem in the context of graphs with bounded degree, we reduce the otherwise difficult multi-agent problem to a single-agent problem. Theoretically, the approach is justified by approximation guarantees. Empirically, the proposed methodology performs well on several realistic and scalable network topologies. Moreover, we compare it with a number of well-known load balancing heuristics and with existing scalable multi-agent reinforcement learning methods. Overall, we obtain a tractable approach for load balancing in highly localized networks.
Collaborative Optimization of the Age of Information under Partial Observability
Dec 20, 2023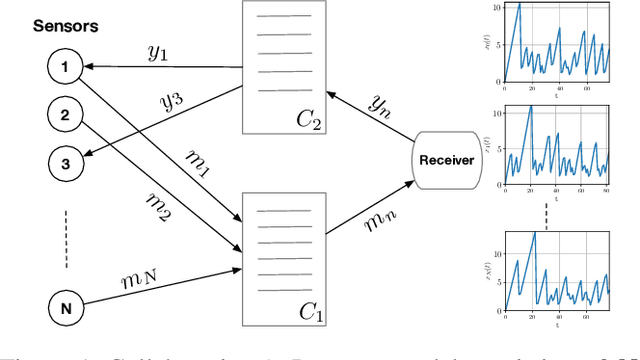
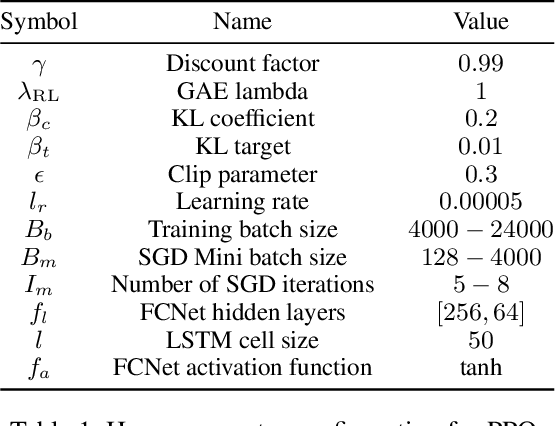
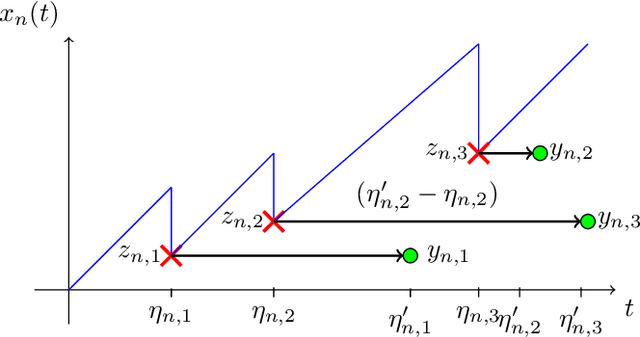
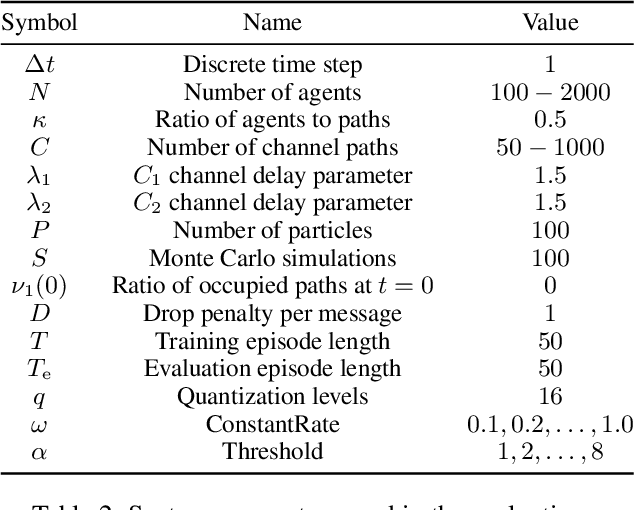
The significance of the freshness of sensor and control data at the receiver side, often referred to as Age of Information (AoI), is fundamentally constrained by contention for limited network resources. Evidently, network congestion is detrimental for AoI, where this congestion is partly self-induced by the sensor transmission process in addition to the contention from other transmitting sensors. In this work, we devise a decentralized AoI-minimizing transmission policy for a number of sensor agents sharing capacity-limited, non-FIFO duplex channels that introduce random delays in communication with a common receiver. By implementing the same policy, however with no explicit inter-agent communication, the agents minimize the expected AoI in this partially observable system. We cater to the partial observability due to random channel delays by designing a bootstrap particle filter that independently maintains a belief over the AoI of each agent. We also leverage mean-field control approximations and reinforcement learning to derive scalable and optimal solutions for minimizing the expected AoI collaboratively.
A Survey on Large-Population Systems and Scalable Multi-Agent Reinforcement Learning
Sep 08, 2022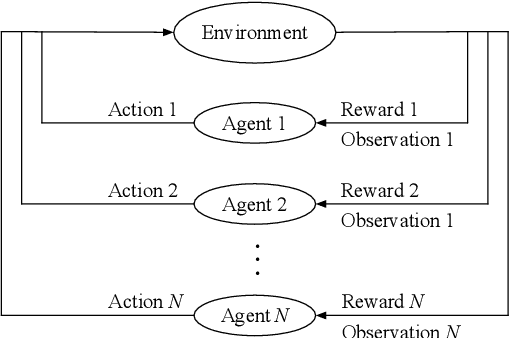
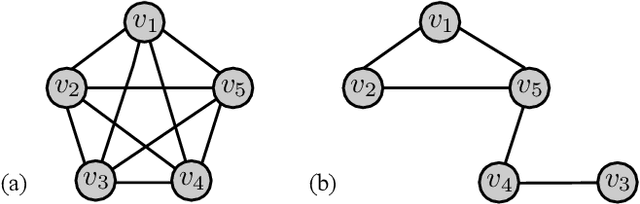
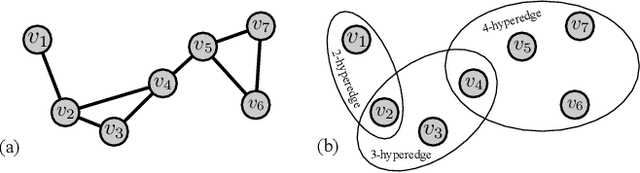
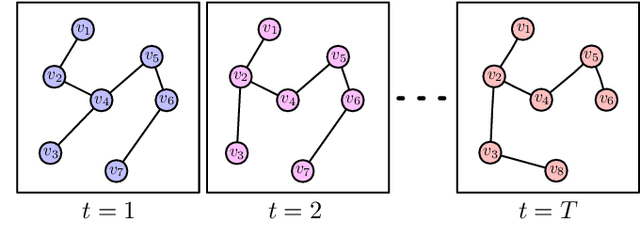
The analysis and control of large-population systems is of great interest to diverse areas of research and engineering, ranging from epidemiology over robotic swarms to economics and finance. An increasingly popular and effective approach to realizing sequential decision-making in multi-agent systems is through multi-agent reinforcement learning, as it allows for an automatic and model-free analysis of highly complex systems. However, the key issue of scalability complicates the design of control and reinforcement learning algorithms particularly in systems with large populations of agents. While reinforcement learning has found resounding empirical success in many scenarios with few agents, problems with many agents quickly become intractable and necessitate special consideration. In this survey, we will shed light on current approaches to tractably understanding and analyzing large-population systems, both through multi-agent reinforcement learning and through adjacent areas of research such as mean-field games, collective intelligence, or complex network theory. These classically independent subject areas offer a variety of approaches to understanding or modeling large-population systems, which may be of great use for the formulation of tractable MARL algorithms in the future. Finally, we survey potential areas of application for large-scale control and identify fruitful future applications of learning algorithms in practical systems. We hope that our survey could provide insight and future directions to junior and senior researchers in theoretical and applied sciences alike.
Decentralized Coordination in Partially Observable Queueing Networks
Aug 29, 2022
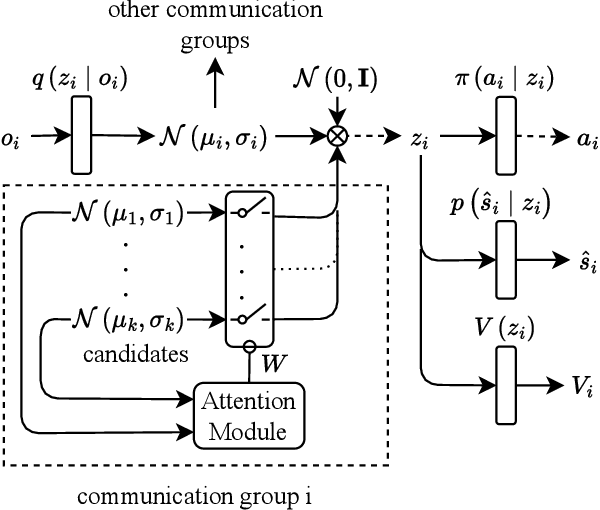
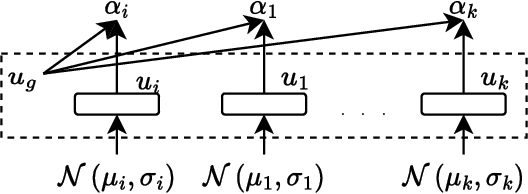
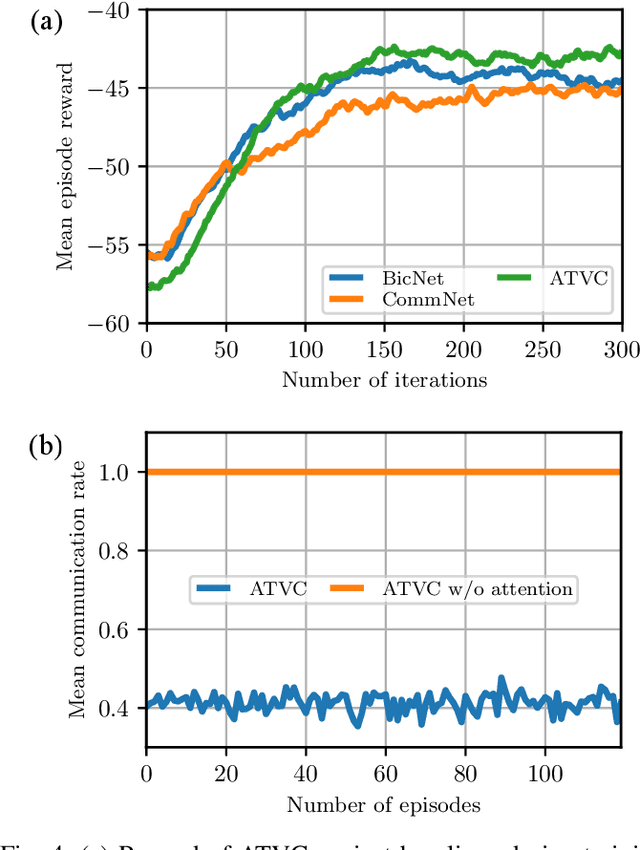
We consider communication in a fully cooperative multi-agent system, where the agents have partial observation of the environment and must act jointly to maximize the overall reward. We have a discrete-time queueing network where agents route packets to queues based only on the partial information of the current queue lengths. The queues have limited buffer capacity, so packet drops happen when they are sent to a full queue. In this work, we implemented a communication channel for the agents to share their information in order to reduce the packet drop rate. For efficient information sharing we use an attention-based communication model, called ATVC, to select informative messages from other agents. The agents then infer the state of queues using a combination of the variational auto-encoder, VAE, and product-of-experts, PoE, model. Ultimately, the agents learn what they need to communicate and with whom, instead of communicating all the time with everyone. We also show empirically that ATVC is able to infer the true state of the queues and leads to a policy which outperforms existing baselines.
Learning Mean-Field Control for Delayed Information Load Balancing in Large Queuing Systems
Aug 09, 2022


Recent years have seen a great increase in the capacity and parallel processing power of data centers and cloud services. To fully utilize the said distributed systems, optimal load balancing for parallel queuing architectures must be realized. Existing state-of-the-art solutions fail to consider the effect of communication delays on the behaviour of very large systems with many clients. In this work, we consider a multi-agent load balancing system, with delayed information, consisting of many clients (load balancers) and many parallel queues. In order to obtain a tractable solution, we model this system as a mean-field control problem with enlarged state-action space in discrete time through exact discretization. Subsequently, we apply policy gradient reinforcement learning algorithms to find an optimal load balancing solution. Here, the discrete-time system model incorporates a synchronization delay under which the queue state information is synchronously broadcasted and updated at all clients. We then provide theoretical performance guarantees for our methodology in large systems. Finally, using experiments, we prove that our approach is not only scalable but also shows good performance when compared to the state-of-the-art power-of-d variant of the Join-the-Shortest-Queue (JSQ) and other policies in the presence of synchronization delays.
Dynamic Time Slot Allocation Algorithm for Quadcopter Swarms
Feb 02, 2022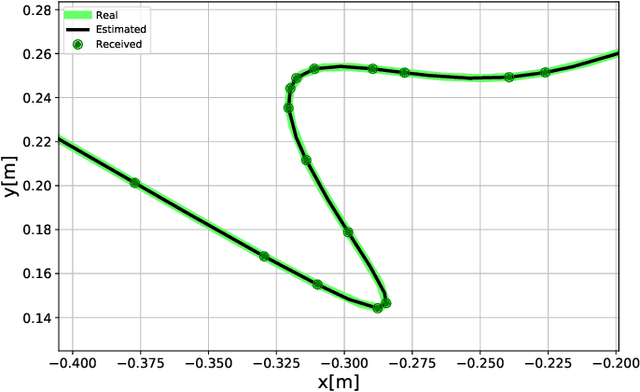
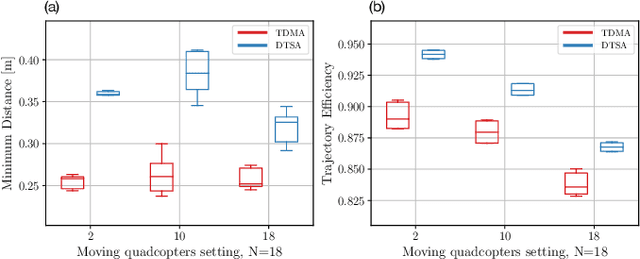
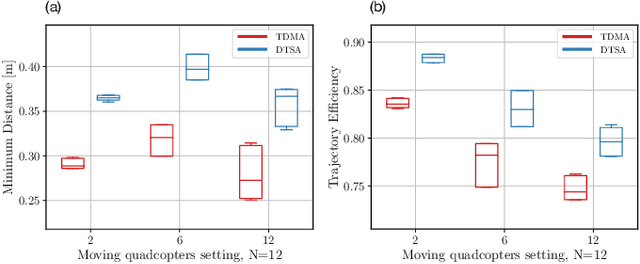
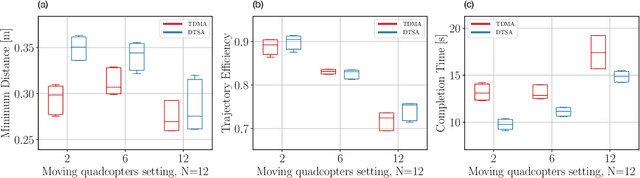
A swarm of quadcopters can perform cooperative tasks, such as monitoring of a large area, more efficiently than a single one. However, to be able to successfully work together, the quadcopters must be aware of the position of the other swarm members, especially to avoid collisions. A quadcopter can share its own position by transmitting it via radio waves and in order to allow multiple quadcopters to communicate effectively, a decentralized channel access protocol is essential. We propose a new dynamic channel access protocol, called Dynamic time slot allocation (DTSA), where the quadcopters share the total channel access time in a non-periodic and decentralized manner. Quadcopters with higher communication demands occupy more time slots than less active ones. Our dynamic approach allows the agents to adapt to changing swarm situations and therefore to act efficiently, as compared to the state-of-the-art periodic channel access protocol, time division multiple access (TDMA). Along with simulations, we also do experiments using real Crazyflie quadcopters to show the improved performance of DTSA as compared to TDMA.
Scheduling in Parallel Finite Buffer Systems: Optimal Decisions under Delayed Feedback
Sep 17, 2021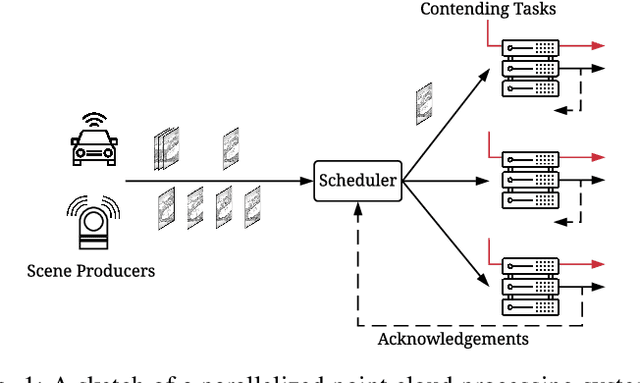
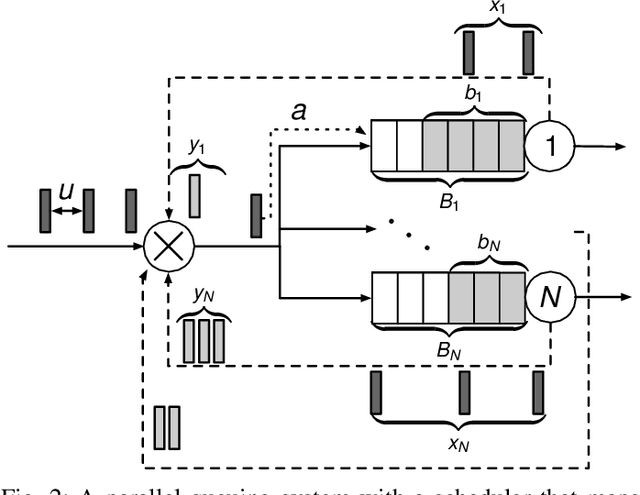

Scheduling decisions in parallel queuing systems arise as a fundamental problem, underlying the dimensioning and operation of many computing and communication systems, such as job routing in data center clusters, multipath communication, and Big Data systems. In essence, the scheduler maps each arriving job to one of the possibly heterogeneous servers while aiming at an optimization goal such as load balancing, low average delay or low loss rate. One main difficulty in finding optimal scheduling decisions here is that the scheduler only partially observes the impact of its decisions, e.g., through the delayed acknowledgements of the served jobs. In this paper, we provide a partially observable (PO) model that captures the scheduling decisions in parallel queuing systems under limited information of delayed acknowledgements. We present a simulation model for this PO system to find a near-optimal scheduling policy in real-time using a scalable Monte Carlo tree search algorithm. We numerically show that the resulting policy outperforms other limited information scheduling strategies such as variants of Join-the-Most-Observations and has comparable performance to full information strategies like: Join-the-Shortest-Queue, Join-the- Shortest-Queue(d) and Shortest-Expected-Delay. Finally, we show how our approach can optimise the real-time parallel processing by using network data provided by Kaggle.
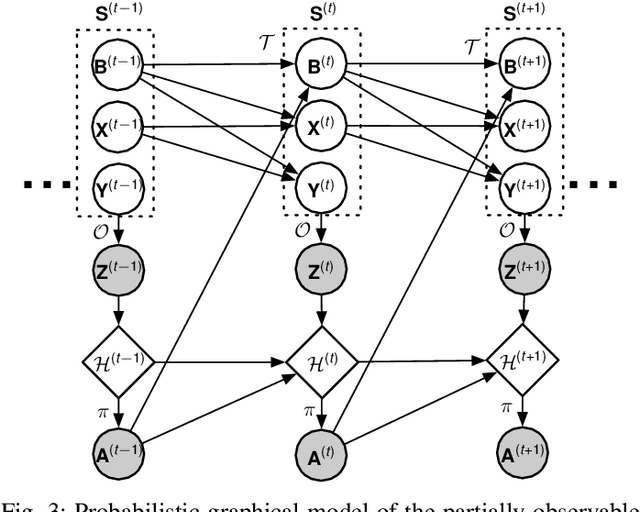
Discrete-Time Mean Field Control with Environment States
Apr 30, 2021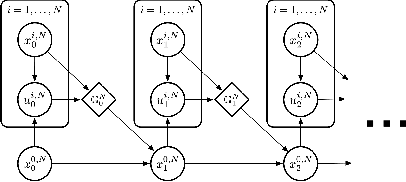

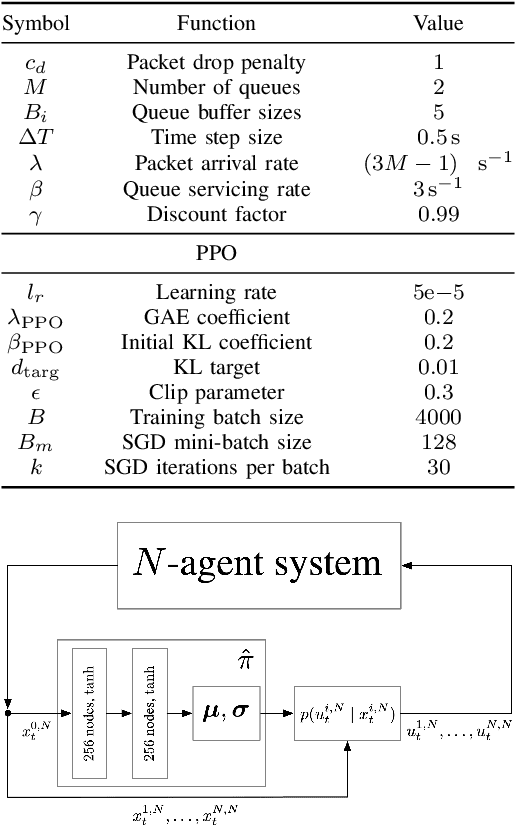
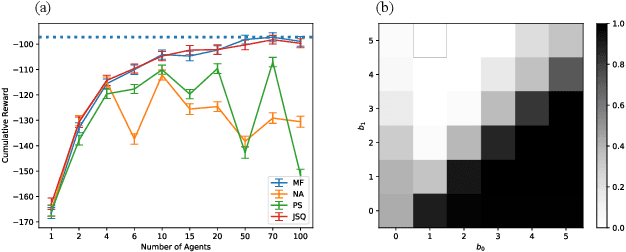
Multi-agent reinforcement learning methods have shown remarkable potential in solving complex multi-agent problems but mostly lack theoretical guarantees. Recently, mean field control and mean field games have been established as a tractable solution for large-scale multi-agent problems with many agents. In this work, driven by a motivating scheduling problem, we consider a discrete-time mean field control model with common environment states. We rigorously establish approximate optimality as the number of agents grows in the finite agent case and find that a dynamic programming principle holds, resulting in the existence of an optimal stationary policy. As exact solutions are difficult in general due to the resulting continuous action space of the limiting mean field Markov decision process, we apply established deep reinforcement learning methods to solve the associated mean field control problem. The performance of the learned mean field control policy is compared to typical multi-agent reinforcement learning approaches and is found to converge to the mean field performance for sufficiently many agents, verifying the obtained theoretical results and reaching competitive solutions.