 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cooperate and Communicate Over Imperfect Channels
Nov 24, 2023Information exchange in multi-agent systems improves the cooperation among agents, especially in partially observable settings. In the real world, communication is often carried out over imperfect channels. This requires agents to handle uncertainty due to potential information loss. In this paper, we consider a cooperative multi-agent system where the agents act and exchange information in a decentralized manner using a limited and unreliable channel. To cope with such channel constraints, we propose a novel communication approach based on independent Q-learning. Our method allows agents to dynamically adapt how much information to share by sending messages of different sizes, depending on their local observations and the channel's properties. In addition to this message size selection, agents learn to encode and decode messages to improve their jointly trained policies. We show that our approach outperforms approaches without adaptive capabilities in a novel cooperative digit-prediction environment and discuss its limitations in the traffic junction environment.
A Survey on Large-Population Systems and Scalable Multi-Agent Reinforcement Learning
Sep 08, 2022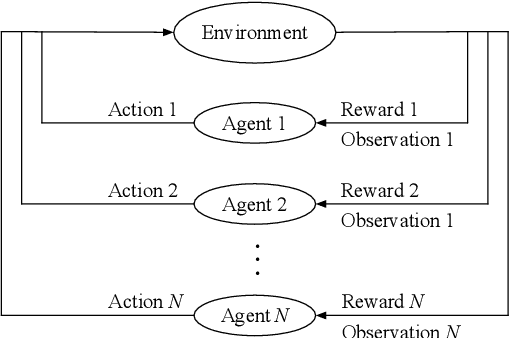
The analysis and control of large-population systems is of great interest to diverse areas of research and engineering, ranging from epidemiology over robotic swarms to economics and finance. An increasingly popular and effective approach to realizing sequential decision-making in multi-agent systems is through multi-agent reinforcement learning, as it allows for an automatic and model-free analysis of highly complex systems. However, the key issue of scalability complicates the design of control and reinforcement learning algorithms particularly in systems with large populations of agents. While reinforcement learning has found resounding empirical success in many scenarios with few agents, problems with many agents quickly become intractable and necessitate special consideration. In this survey, we will shed light on current approaches to tractably understanding and analyzing large-population systems, both through multi-agent reinforcement learning and through adjacent areas of research such as mean-field games, collective intelligence, or complex network theory. These classically independent subject areas offer a variety of approaches to understanding or modeling large-population systems, which may be of great use for the formulation of tractable MARL algorithms in the future. Finally, we survey potential areas of application for large-scale control and identify fruitful future applications of learning algorithms in practical systems. We hope that our survey could provide insight and future directions to junior and senior researchers in theoretical and applied sciences alike.