 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatQNet: Satellite-assisted Quantum Network Entanglement Routing Using Directed Line Graph Neural Networks
Apr 10, 2026Quantum networks are expected to become a key enabler for interconnecting quantum devices. In contrast to classical communication networks, however, information transfer in quantum networks is usually restricted to short distances due to physical constraints of entanglement distribution. Satellites can extend entanglement distribution over long distances, but routing in such networks is challenging because satellite motion and stochastic link generation create a highly dynamic quantum topology. Existing routing methods often rely on global topology information that quickly becomes outdated due to delays in the classical control plane, while decentralized methods typically act on incomplete local information. We propose SatQNet, a reinforcement learning approach for entanglement routing in satellite-assisted quantum networks that can be decentralized at runtime. Its key innovation is an edge-centric directed line graph neural network that performs local message passing on directed edge embeddings, enabling it to better capture link properties in high-degree and time-varying topologies. By exchanging messages with neighboring repeaters, SatQNet learns a local graph representation at runtime that supports agents in establishing high-fidelity end-to-end entanglements. Trained on random graphs, SatQNet outperforms heuristic and learning-based approaches across diverse settings, including a real-world European backbone topology, and generalizes to unseen topologies without retraining.
Analyzing Symbolic Properties for DRL Agents in Systems and Networking
Apr 06, 2026Deep reinforcement learning (DRL) has shown remarkable performance on complex control problems in systems and networking, including adaptive video streaming, wireless resource management, and congestion control. For safe deployment, however, it is critical to reason about how agents behave across the range of system states they encounter in practice. Existing verification-based methods in this domain primarily focus on point properties, defined around fixed input states, which offer limited coverage and require substantial manual effort to identify relevant input-output pairs for analysis. In this paper, we study symbolic properties, that specify expected behavior over ranges of input states, for DRL agents in systems and networking. We present a generic formulation for symbolic properties, with monotonicity and robustness as concrete examples, and show how they can be analyzed using existing DNN verification engines. Our approach encodes symbolic properties as comparisons between related executions of the same policy and decomposes them into practically tractable sub-properties. These techniques serve as practical enablers for applying existing verification tools to symbolic analysis. Using our framework, diffRL, we conduct an extensive empirical study across three DRL-based control systems, adaptive video streaming, wireless resource management, and congestion control. Through these case studies, we analyze symbolic properties over broad input ranges, examine how property satisfaction evolves during training, study the impact of model size on verifiability, and compare multiple verification backends. Our results show that symbolic properties provide substantially broader coverage than point properties and can uncover non-obvious, operationally meaningful counterexamples, while also revealing practical solver trade-offs and limitations.
FairStream: Fair Multimedia Streaming Benchmark for Reinforcement Learning Agents
Oct 28, 2024


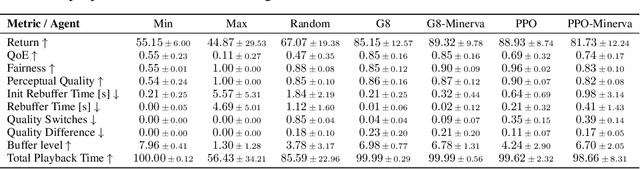
Multimedia streaming accounts for the majority of traffic in today's internet. Mechanisms like adaptive bitrate streaming control the bitrate of a stream based on the estimated bandwidth, ideally resulting in smooth playback and a good Quality of Experience (QoE). However, selecting the optimal bitrate is challenging under volatile network conditions. This motivated researchers to train Reinforcement Learning (RL) agents for multimedia streaming. The considered training environments are often simplified, leading to promising results with limited applicability. Additionally, the QoE fairness across multiple streams is seldom considered by recent RL approaches. With this work, we propose a novel multi-agent environment that comprises multiple challenges of fair multimedia streaming: partial observability, multiple objectives, agent heterogeneity and asynchronicity. We provide and analyze baseline approaches across five different traffic classes to gain detailed insights into the behavior of the considered agents, and show that the commonly used Proximal Policy Optimization (PPO) algorithm is outperformed by a simple greedy heuristic. Future work includes the adaptation of multi-agent RL algorithms and further expansions of the environment.
Towards Generalizability of Multi-Agent Reinforcement Learning in Graphs with Recurrent Message Passing
Feb 09, 2024



Graph-based environments pose unique challenges to multi-agent reinforcement learning. In decentralized approaches, agents operate within a given graph and make decisions based on partial or outdated observations. The size of the observed neighborhood limits the generalizability to different graphs and affects the reactivity of agents, the quality of the selected actions, and the communication overhead. This work focuses on generalizability and resolves the trade-off in observed neighborhood size with a continuous information flow in the whole graph. We propose a recurrent message-passing model that iterates with the environment's steps and allows nodes to create a global representation of the graph by exchanging messages with their neighbors. Agents receive the resulting learned graph observations based on their location in the graph. Our approach can be used in a decentralized manner at runtime and in combination with a reinforcement learning algorithm of choice. We evaluate our method across 1000 diverse graphs in the context of routing in communication networks and find that it enables agents to generalize and adapt to changes in the graph.
Learning to Cooperate and Communicate Over Imperfect Channels
Nov 24, 2023


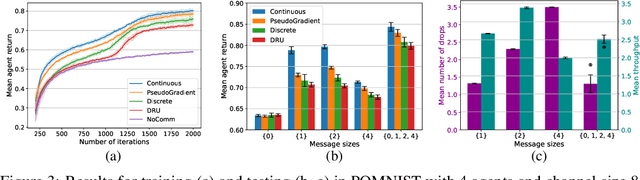
Information exchange in multi-agent systems improves the cooperation among agents, especially in partially observable settings. In the real world, communication is often carried out over imperfect channels. This requires agents to handle uncertainty due to potential information loss. In this paper, we consider a cooperative multi-agent system where the agents act and exchange information in a decentralized manner using a limited and unreliable channel. To cope with such channel constraints, we propose a novel communication approach based on independent Q-learning. Our method allows agents to dynamically adapt how much information to share by sending messages of different sizes, depending on their local observations and the channel's properties. In addition to this message size selection, agents learn to encode and decode messages to improve their jointly trained policies. We show that our approach outperforms approaches without adaptive capabilities in a novel cooperative digit-prediction environment and discuss its limitations in the traffic junction environment.
Know your Enemy: Investigating Monte-Carlo Tree Search with Opponent Models in Pommerman
May 22, 2023


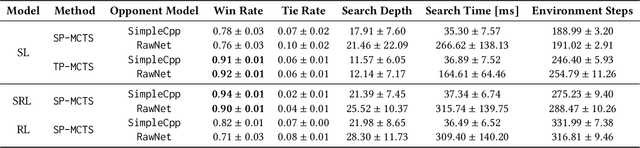
In combination with Reinforcement Learning, Monte-Carlo Tree Search has shown to outperform human grandmasters in games such as Chess, Shogi and Go with little to no prior domain knowledge. However, most classical use cases only feature up to two players. Scaling the search to an arbitrary number of players presents a computational challenge, especially if decisions have to be planned over a longer time horizon. In this work, we investigate techniques that transform general-sum multiplayer games into single-player and two-player games that consider other agents to act according to given opponent models. For our evaluation, we focus on the challenging Pommerman environment which involves partial observability, a long time horizon and sparse rewards. In combination with our search methods, we investigate the phenomena of opponent modeling using heuristics and self-play. Overall, we demonstrate the effectiveness of our multiplayer search variants both in a supervised learning and reinforcement learning setting.