 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP: Winning Solution to SMP Challenge 2025 Video Track
Jul 01, 2025Social media platforms serve as central hubs for content dissemination, opinion expression, and public engagement across diverse modalities. Accurately predicting the popularity of social media videos enables valuable applications in content recommendation, trend detection, and audience engagement. In this paper, we present Multimodal Video Predictor (MVP), our winning solution to the Video Track of the SMP Challenge 2025. MVP constructs expressive post representations by integrating deep video features extracted from pretrained models with user metadata and contextual information. The framework applies systematic preprocessing techniques, including log-transformations and outlier removal, to improve model robustness. A gradient-boosted regression model is trained to capture complex patterns across modalities. Our approach ranked first in the official evaluation of the Video Track, demonstrating its effectiveness and reliability for multimodal video popularity prediction on social platforms. The source code is available at https://anonymous.4open.science/r/SMPDVideo.
HyperFusion: Hierarchical Multimodal Ensemble Learning for Social Media Popularity Prediction
Jul 01, 2025Social media popularity prediction plays a crucial role in content optimization, marketing strategies, and user engagement enhancement across digital platforms. However, predicting post popularity remains challenging due to the complex interplay between visual, textual, temporal, and user behavioral factors. This paper presents HyperFusion, a hierarchical multimodal ensemble learning framework for social media popularity prediction. Our approach employs a three-tier fusion architecture that progressively integrates features across abstraction levels: visual representations from CLIP encoders, textual embeddings from transformer models, and temporal-spatial metadata with user characteristics. The framework implements a hierarchical ensemble strategy combining CatBoost, TabNet, and custom multi-layer perceptrons. To address limited labeled data, we propose a two-stage training methodology with pseudo-labeling and iterative refinement. We introduce novel cross-modal similarity measures and hierarchical clustering features that capture inter-modal dependencies. Experimental results demonstrate that HyperFusion achieves competitive performance on the SMP challenge dataset. Our team achieved third place in the SMP Challenge 2025 (Image Track). The source code is available at https://anonymous.4open.science/r/SMPDImage.
SF2T: Self-supervised Fragment Finetuning of Video-LLMs for Fine-Grained Understanding
Apr 10, 2025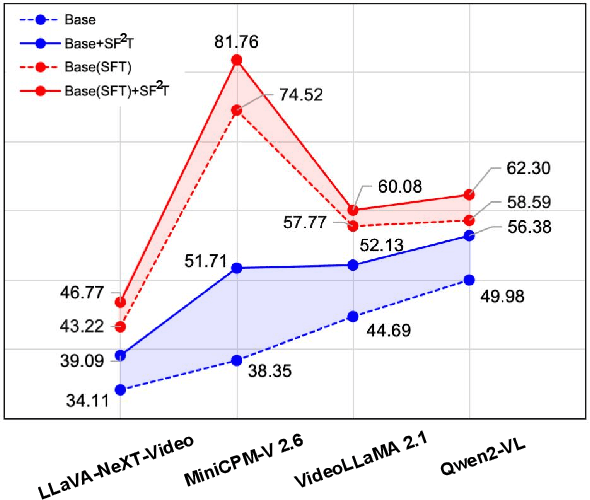



Video-based Large Language Models (Video-LLMs) have witnessed substantial advancements in recent years, propelled by the advancement in multi-modal LLMs. Although these models have demonstrated proficiency in providing the overall description of videos, they struggle with fine-grained understanding, particularly in aspects such as visual dynamics and video details inquiries. To tackle these shortcomings, we find that fine-tuning Video-LLMs on self-supervised fragment tasks, greatly improve their fine-grained video understanding abilities. Hence we propose two key contributions:(1) Self-Supervised Fragment Fine-Tuning (SF$^2$T), a novel effortless fine-tuning method, employs the rich inherent characteristics of videos for training, while unlocking more fine-grained understanding ability of Video-LLMs. Moreover, it relieves researchers from labor-intensive annotations and smartly circumvents the limitations of natural language, which often fails to capture the complex spatiotemporal variations in videos; (2) A novel benchmark dataset, namely FineVidBench, for rigorously assessing Video-LLMs' performance at both the scene and fragment levels, offering a comprehensive evaluation of their capabilities. We assessed multiple models and validated the effectiveness of SF$^2$T on them. Experimental results reveal that our approach improves their ability to capture and interpret spatiotemporal details.
FairStream: Fair Multimedia Streaming Benchmark for Reinforcement Learning Agents
Oct 28, 2024Multimedia streaming accounts for the majority of traffic in today's internet. Mechanisms like adaptive bitrate streaming control the bitrate of a stream based on the estimated bandwidth, ideally resulting in smooth playback and a good Quality of Experience (QoE). However, selecting the optimal bitrate is challenging under volatile network conditions. This motivated researchers to train Reinforcement Learning (RL) agents for multimedia streaming. The considered training environments are often simplified, leading to promising results with limited applicability. Additionally, the QoE fairness across multiple streams is seldom considered by recent RL approaches. With this work, we propose a novel multi-agent environment that comprises multiple challenges of fair multimedia streaming: partial observability, multiple objectives, agent heterogeneity and asynchronicity. We provide and analyze baseline approaches across five different traffic classes to gain detailed insights into the behavior of the considered agents, and show that the commonly used Proximal Policy Optimization (PPO) algorithm is outperformed by a simple greedy heuristic. Future work includes the adaptation of multi-agent RL algorithms and further expansions of the environment.
Autogenic Language Embedding for Coherent Point Tracking
Jul 30, 2024
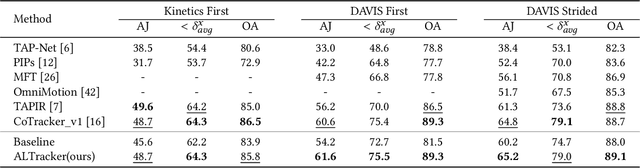


Point tracking is a challenging task in computer vision, aiming to establish point-wise correspondence across long video sequences. Recent advancements have primarily focused on temporal modeling techniques to improve local feature similarity, often overlooking the valuable semantic consistency inherent in tracked points. In this paper, we introduce a novel approach leveraging language embeddings to enhance the coherence of frame-wise visual features related to the same object. Our proposed method, termed autogenic language embedding for visual feature enhancement, strengthens point correspondence in long-term sequences. Unlike existing visual-language schemes, our approach learns text embeddings from visual features through a dedicated mapping network, enabling seamless adaptation to various tracking tasks without explicit text annotations. Additionally, we introduce a consistency decoder that efficiently integrates text tokens into visual features with minimal computational overhead. Through enhanced visual consistency, our approach significantly improves tracking trajectories in lengthy videos with substantial appearance variations. Extensive experiments on widely-used tracking benchmarks demonstrate the superior performance of our method, showcasing notable enhancements compared to trackers relying solely on visual cues.
Graph Spatiotemporal Process for Multivariate Time Series Anomaly Detection with Missing Values
Jan 11, 2024



The detection of anomalies in multivariate time series data is crucial for various practical applications, including smart power grids, traffic flow forecasting, and industrial process control. However, real-world time series data is usually not well-structured, posting significant challenges to existing approaches: (1) The existence of missing values in multivariate time series data along variable and time dimensions hinders the effective modeling of interwoven spatial and temporal dependencies, resulting in important patterns being overlooked during model training; (2) Anomaly scoring with irregularly-sampled observations is less explored, making it difficult to use existing detectors for multivariate series without fully-observed values. In this work, we introduce a novel framework called GST-Pro, which utilizes a graph spatiotemporal process and anomaly scorer to tackle the aforementioned challenges in detecting anomalies on irregularly-sampled multivariate time series. Our approach comprises two main components. First, we propose a graph spatiotemporal process based on neural controlled differential equations. This process enables effective modeling of multivariate time series from both spatial and temporal perspectives, even when the data contains missing values. Second, we present a novel distribution-based anomaly scoring mechanism that alleviates the reliance on complete uniform observations. By analyzing the predictions of the graph spatiotemporal process, our approach allows anomalies to be easily detected. Our experimental results show that the GST-Pro method can effectively detect anomalies in time series data and outperforms state-of-the-art methods, regardless of whether there are missing values present in the data. Our code is available: https://github.com/huankoh/GST-Pro.
Correlation-aware Spatial-Temporal Graph Learning for Multivariate Time-series Anomaly Detection
Jul 17, 2023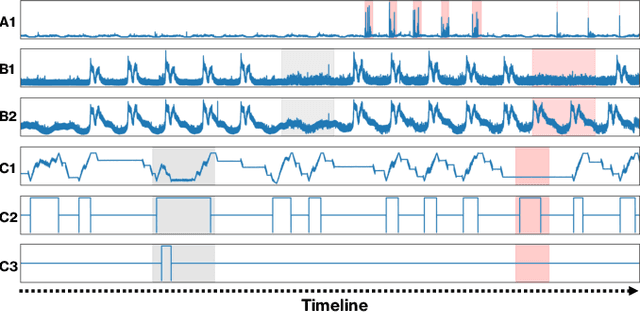
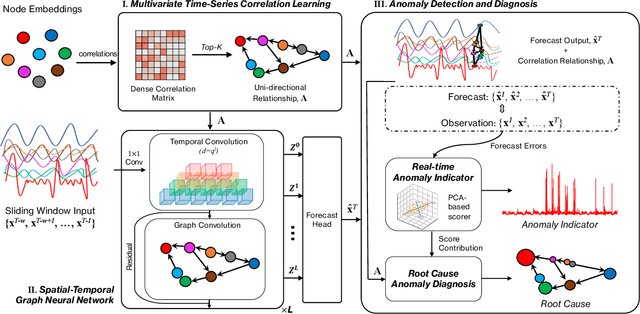


Multivariate time-series anomaly detection is critically important in many applications, including retail, transportation, power grid, and water treatment plants. Existing approaches for this problem mostly employ either statistical models which cannot capture the non-linear relations well or conventional deep learning models (e.g., CNN and LSTM) that do not explicitly learn the pairwise correlations among variables. To overcome these limitations, we propose a novel method, correlation-aware spatial-temporal graph learning (termed CST-GL), for time series anomaly detection. CST-GL explicitly captures the pairwise correlations via a multivariate time series correlation learning module based on which a spatial-temporal graph neural network (STGNN) can be developed. Then, by employing a graph convolution network that exploits one- and multi-hop neighbor information, our STGNN component can encode rich spatial information from complex pairwise dependencies between variables. With a temporal module that consists of dilated convolutional functions, the STGNN can further capture long-range dependence over time. A novel anomaly scoring component is further integrated into CST-GL to estimate the degree of an anomaly in a purely unsupervised manner. Experimental results demonstrate that CST-GL can detect anomalies effectively in general settings as well as enable early detection across different time delays.
Compact Transformer Tracker with Correlative Masked Modeling
Jan 26, 2023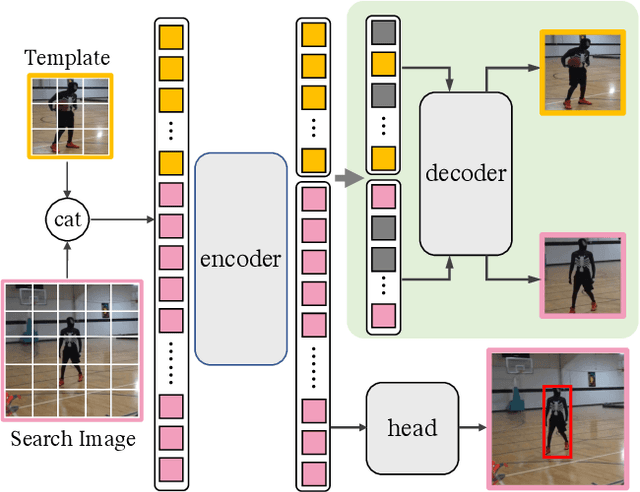



Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.
eX-ViT: A Novel eXplainable Vision Transformer for Weakly Supervised Semantic Segmentation
Jul 12, 2022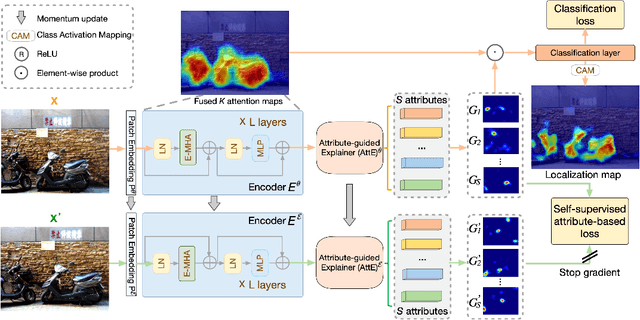



Recently vision transformer models have become prominent models for a range of vision tasks. These models, however, are usually opaque with weak feature interpretability. Moreover, there is no method currently built for an intrinsically interpretable transformer, which is able to explain its reasoning process and provide a faithful explanation. To close these crucial gaps, we propose a novel vision transformer dubbed the eXplainable Vision Transformer (eX-ViT), an intrinsically interpretable transformer model that is able to jointly discover robust interpretable features and perform the prediction. Specifically, eX-ViT is composed of the Explainable Multi-Head Attention (E-MHA) module, the Attribute-guided Explainer (AttE) module and the self-supervised attribute-guided loss. The E-MHA tailors explainable attention weights that are able to learn semantically interpretable representations from local patches in terms of model decisions with noise robustness. Meanwhile, AttE is proposed to encode discriminative attribute features for the target object through diverse attribute discovery, which constitutes faithful evidence for the model's predictions. In addition, a self-supervised attribute-guided loss is developed for our eX-ViT, which aims at learning enhanced representations through the attribute discriminability mechanism and attribute diversity mechanism, to localize diverse and discriminative attributes and generate more robust explanations. As a result, we can uncover faithful and robust interpretations with diverse attributes through the proposed eX-ViT.
Transformer Tracking with Cyclic Shifting Window Attention
May 08, 2022


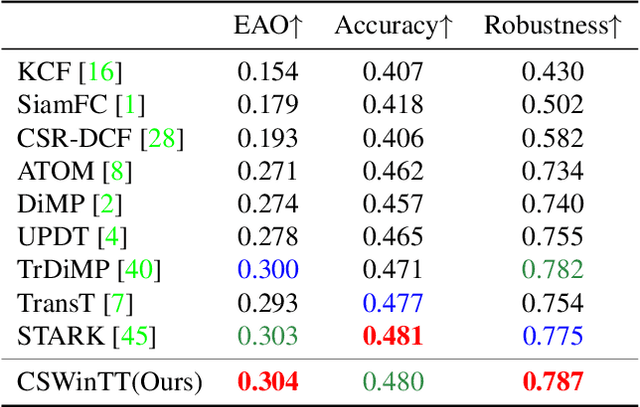
Transformer architecture has been showing its great strength in visual object tracking, for its effective attention mechanism. Existing transformer-based approaches adopt the pixel-to-pixel attention strategy on flattened image features and unavoidably ignore the integrity of objects. In this paper, we propose a new transformer architecture with multi-scale cyclic shifting window attention for visual object tracking, elevating the attention from pixel to window level. The cross-window multi-scale attention has the advantage of aggregating attention at different scales and generates the best fine-scale match for the target object. Furthermore, the cyclic shifting strategy brings greater accuracy by expanding the window samples with positional information, and at the same time saves huge amounts of computational power by removing redundant calculations. Extensive experiments demonstrate the superior performance of our method, which also sets the new state-of-the-art records on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks.