 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{M}^{2}$LLM: Multi-view Molecular Representation Learning with Large Language Models
Aug 12, 2025Accurate molecular property prediction is a critical challenge with wide-ranging applications in chemistry, materials science, and drug discovery. Molecular representation methods, including fingerprints and graph neural networks (GNNs), achieve state-of-the-art results by effectively deriving features from molecular structures. However, these methods often overlook decades of accumulated semantic and contextual knowledge. Recent advancements in large language models (LLMs) demonstrate remarkable reasoning abilities and prior knowledge across scientific domains, leading us to hypothesize that LLMs can generate rich molecular representations when guided to reason in multiple perspectives. To address these gaps, we propose $\text{M}^{2}$LLM, a multi-view framework that integrates three perspectives: the molecular structure view, the molecular task view, and the molecular rules view. These views are fused dynamically to adapt to task requirements, and experiments demonstrate that $\text{M}^{2}$LLM achieves state-of-the-art performance on multiple benchmarks across classification and regression tasks. Moreover, we demonstrate that representation derived from LLM achieves exceptional performance by leveraging two core functionalities: the generation of molecular embeddings through their encoding capabilities and the curation of molecular features through advanced reasoning processes.
Collaborative Expert LLMs Guided Multi-Objective Molecular Optimization
Mar 05, 2025



Molecular optimization is a crucial yet complex and time-intensive process that often acts as a bottleneck for drug development. Traditional methods rely heavily on trial and error, making multi-objective optimization both time-consuming and resource-intensive. Current AI-based methods have shown limited success in handling multi-objective optimization tasks, hampering their practical utilization. To address this challenge, we present MultiMol, a collaborative large language model (LLM) system designed to guide multi-objective molecular optimization. MultiMol comprises two agents, including a data-driven worker agent and a literature-guided research agent. The data-driven worker agent is a large language model being fine-tuned to learn how to generate optimized molecules considering multiple objectives, while the literature-guided research agent is responsible for searching task-related literature to find useful prior knowledge that facilitates identifying the most promising optimized candidates. In evaluations across six multi-objective optimization tasks, MultiMol significantly outperforms existing methods, achieving a 82.30% success rate, in sharp contrast to the 27.50% success rate of current strongest methods. To further validate its practical impact, we tested MultiMol on two real-world challenges. First, we enhanced the selectivity of Xanthine Amine Congener (XAC), a promiscuous ligand that binds both A1R and A2AR, successfully biasing it towards A1R. Second, we improved the bioavailability of Saquinavir, an HIV-1 protease inhibitor with known bioavailability limitations. Overall, these results indicate that MultiMol represents a highly promising approach for multi-objective molecular optimization, holding great potential to accelerate the drug development process and contribute to the advancement of pharmaceutical research.
Large Language Models in Drug Discovery and Development: From Disease Mechanisms to Clinical Trials
Sep 06, 2024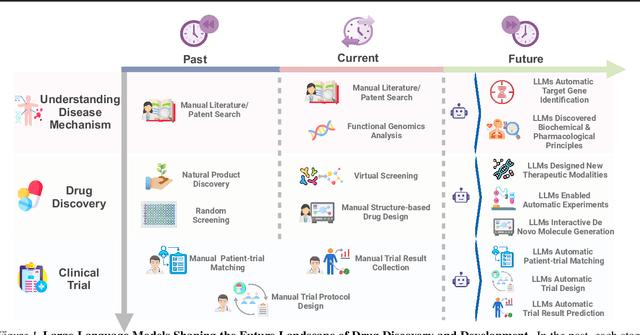
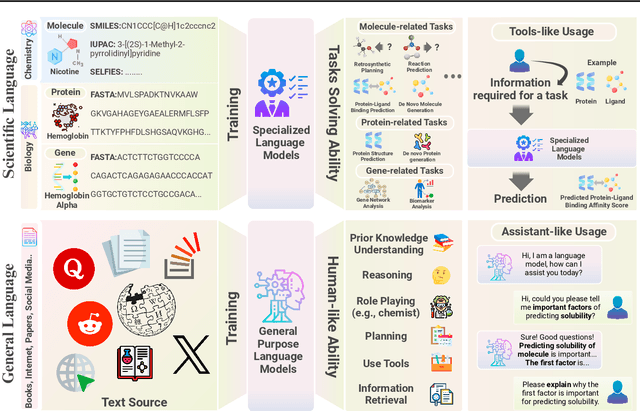
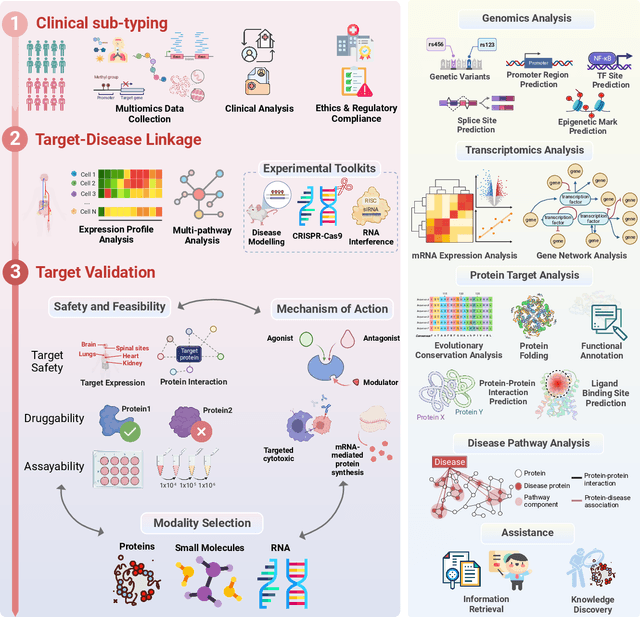
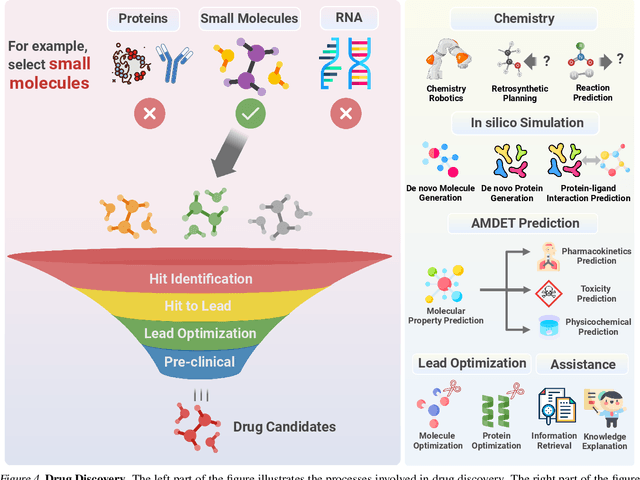
The integration of Large Language Models (LLMs) into the drug discovery and development field marks a significant paradigm shift, offering novel methodologies for understanding disease mechanisms, facilitating drug discovery, and optimizing clinical trial processes. This review highlights the expanding role of LLMs in revolutionizing various stages of the drug development pipeline. We investigate how these advanced computational models can uncover target-disease linkage, interpret complex biomedical data, enhance drug molecule design, predict drug efficacy and safety profiles, and facilitate clinical trial processes. Our paper aims to provide a comprehensive overview for researchers and practitioners in computational biology, pharmacology, and AI4Science by offering insights into the potential transformative impact of LLMs on drug discovery and development.
Graph Spatiotemporal Process for Multivariate Time Series Anomaly Detection with Missing Values
Jan 11, 2024



The detection of anomalies in multivariate time series data is crucial for various practical applications, including smart power grids, traffic flow forecasting, and industrial process control. However, real-world time series data is usually not well-structured, posting significant challenges to existing approaches: (1) The existence of missing values in multivariate time series data along variable and time dimensions hinders the effective modeling of interwoven spatial and temporal dependencies, resulting in important patterns being overlooked during model training; (2) Anomaly scoring with irregularly-sampled observations is less explored, making it difficult to use existing detectors for multivariate series without fully-observed values. In this work, we introduce a novel framework called GST-Pro, which utilizes a graph spatiotemporal process and anomaly scorer to tackle the aforementioned challenges in detecting anomalies on irregularly-sampled multivariate time series. Our approach comprises two main components. First, we propose a graph spatiotemporal process based on neural controlled differential equations. This process enables effective modeling of multivariate time series from both spatial and temporal perspectives, even when the data contains missing values. Second, we present a novel distribution-based anomaly scoring mechanism that alleviates the reliance on complete uniform observations. By analyzing the predictions of the graph spatiotemporal process, our approach allows anomalies to be easily detected. Our experimental results show that the GST-Pro method can effectively detect anomalies in time series data and outperforms state-of-the-art methods, regardless of whether there are missing values present in the data. Our code is available: https://github.com/huankoh/GST-Pro.
Large Language Models for Scientific Synthesis, Inference and Explanation
Oct 12, 2023Large language models are a form of artificial intelligence systems whose primary knowledge consists of the statistical patterns, semantic relationships, and syntactical structures of language1. Despite their limited forms of "knowledge", these systems are adept at numerous complex tasks including creative writing, storytelling, translation, question-answering, summarization, and computer code generation. However, they have yet to demonstrate advanced applications in natural science. Here we show how large language models can perform scientific synthesis, inference, and explanation. We present a method for using general-purpose large language models to make inferences from scientific datasets of the form usually associated with special-purpose machine learning algorithms. We show that the large language model can augment this "knowledge" by synthesizing from the scientific literature. When a conventional machine learning system is augmented with this synthesized and inferred knowledge it can outperform the current state of the art across a range of benchmark tasks for predicting molecular properties. This approach has the further advantage that the large language model can explain the machine learning system's predictions. We anticipate that our framework will open new avenues for AI to accelerate the pace of scientific discovery.
Correlation-aware Spatial-Temporal Graph Learning for Multivariate Time-series Anomaly Detection
Jul 17, 2023


Multivariate time-series anomaly detection is critically important in many applications, including retail, transportation, power grid, and water treatment plants. Existing approaches for this problem mostly employ either statistical models which cannot capture the non-linear relations well or conventional deep learning models (e.g., CNN and LSTM) that do not explicitly learn the pairwise correlations among variables. To overcome these limitations, we propose a novel method, correlation-aware spatial-temporal graph learning (termed CST-GL), for time series anomaly detection. CST-GL explicitly captures the pairwise correlations via a multivariate time series correlation learning module based on which a spatial-temporal graph neural network (STGNN) can be developed. Then, by employing a graph convolution network that exploits one- and multi-hop neighbor information, our STGNN component can encode rich spatial information from complex pairwise dependencies between variables. With a temporal module that consists of dilated convolutional functions, the STGNN can further capture long-range dependence over time. A novel anomaly scoring component is further integrated into CST-GL to estimate the degree of an anomaly in a purely unsupervised manner. Experimental results demonstrate that CST-GL can detect anomalies effectively in general settings as well as enable early detection across different time delays.
A Survey on Graph Neural Networks for Time Series: Forecasting, Classification, Imputation, and Anomaly Detection
Jul 07, 2023



Time series are the primary data type used to record dynamic system measurements and generated in great volume by both physical sensors and online processes (virtual sensors). Time series analytics is therefore crucial to unlocking the wealth of information implicit in available data. With the recent advancements in graph neural networks (GNNs), there has been a surge in GNN-based approaches for time series analysis. Approaches can explicitly model inter-temporal and inter-variable relationships, which traditional and other deep neural network-based methods struggle to do. In this survey, we provide a comprehensive review of graph neural networks for time series analysis (GNN4TS), encompassing four fundamental dimensions: Forecasting, classification, anomaly detection, and imputation. Our aim is to guide designers and practitioners to understand, build applications, and advance research of GNN4TS. At first, we provide a comprehensive task-oriented taxonomy of GNN4TS. Then, we present and discuss representative research works and, finally, discuss mainstream applications of GNN4TS. A comprehensive discussion of potential future research directions completes the survey. This survey, for the first time, brings together a vast array of knowledge on GNN-based time series research, highlighting both the foundations, practical applications, and opportunities of graph neural networks for time series analysis.
How Far are We from Robust Long Abstractive Summarization?
Oct 30, 2022
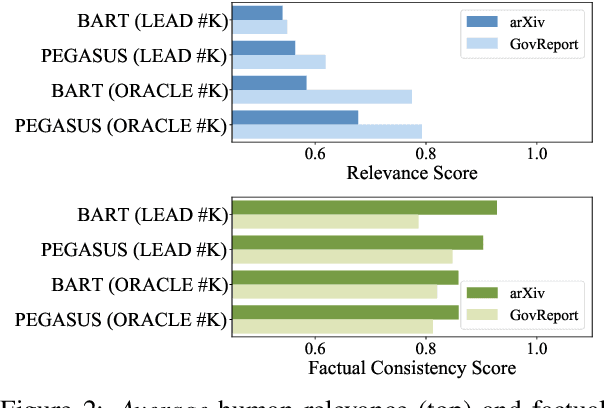
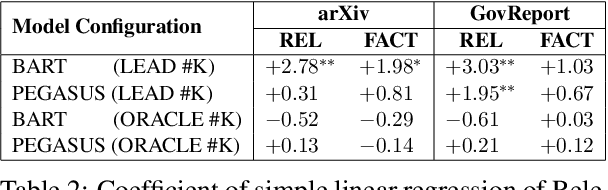
Abstractive summarization has made tremendous progress in recent years. In this work, we perform fine-grained human annotations to evaluate long document abstractive summarization systems (i.e., models and metrics) with the aim of implementing them to generate reliable summaries. For long document abstractive models, we show that the constant strive for state-of-the-art ROUGE results can lead us to generate more relevant summaries but not factual ones. For long document evaluation metrics, human evaluation results show that ROUGE remains the best at evaluating the relevancy of a summary. It also reveals important limitations of factuality metrics in detecting different types of factual errors and the reasons behind the effectiveness of BARTScore. We then suggest promising directions in the endeavor of developing factual consistency metrics. Finally, we release our annotated long document dataset with the hope that it can contribute to the development of metrics across a broader range of summarization settings.
An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics
Jul 03, 2022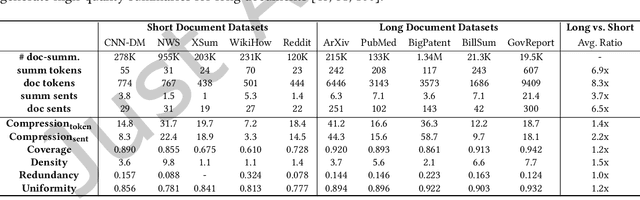
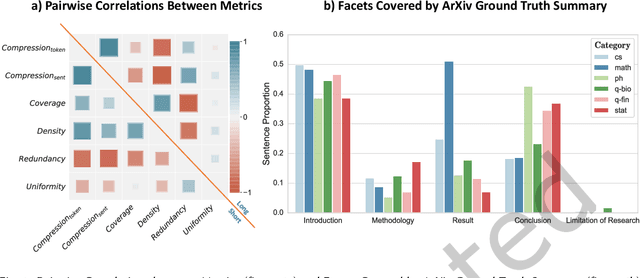
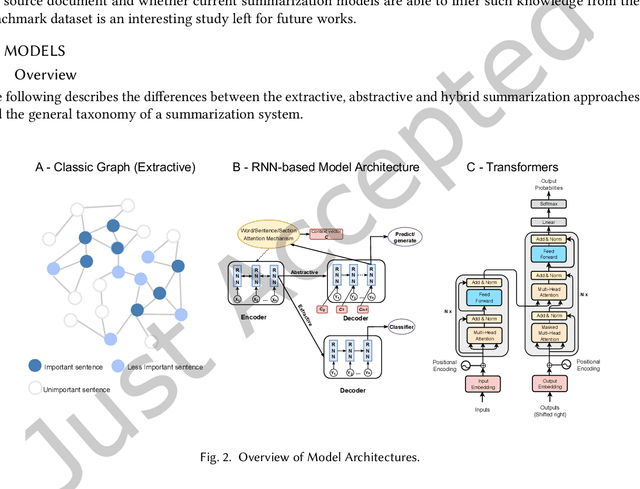
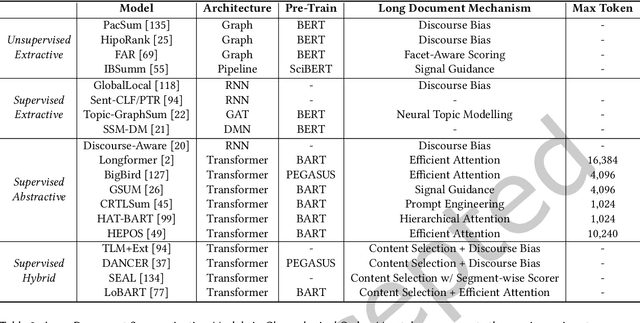
Long documents such as academic articles and business reports have been the standard format to detail out important issues and complicated subjects that require extra attention. An automatic summarization system that can effectively condense long documents into short and concise texts to encapsulate the most important information would thus be significant in aiding the reader's comprehension. Recently, with the advent of neural architectures, significant research efforts have been made to advance automatic text summarization systems, and numerous studies on the challenges of extending these systems to the long document domain have emerged. In this survey, we provide a comprehensive overview of the research on long document summarization and a systematic evaluation across the three principal components of its research setting: benchmark datasets, summarization models, and evaluation metrics. For each component, we organize the literature within the context of long document summarization and conduct an empirical analysis to broaden the perspective on current research progress. The empirical analysis includes a study on the intrinsic characteristics of benchmark datasets, a multi-dimensional analysis of summarization models, and a review of the summarization evaluation metrics. Based on the overall findings, we conclude by proposing possible directions for future exploration in this rapidly growing field.
Leveraging Information Bottleneck for Scientific Document Summarization
Oct 04, 2021
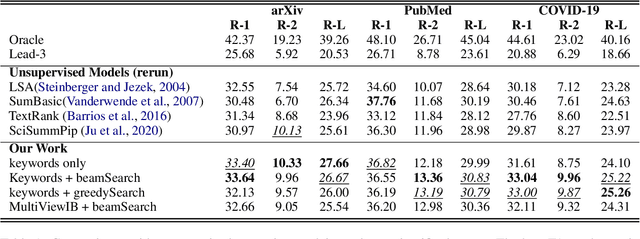
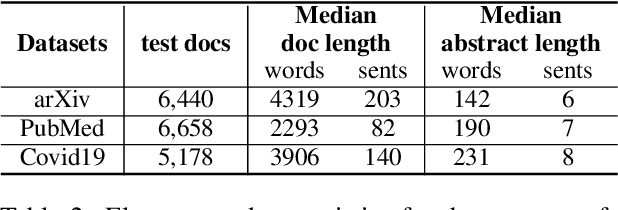
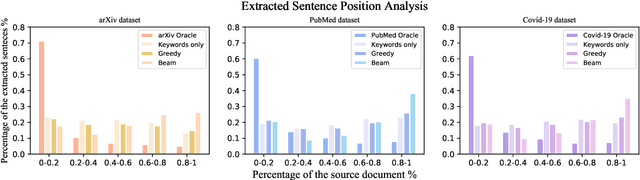
This paper presents an unsupervised extractive approach to summarize scientific long documents based on the Information Bottleneck principle. Inspired by previous work which uses the Information Bottleneck principle for sentence compression, we extend it to document level summarization with two separate steps. In the first step, we use signal(s) as queries to retrieve the key content from the source document. Then, a pre-trained language model conducts further sentence search and edit to return the final extracted summaries. Importantly, our work can be flexibly extended to a multi-view framework by different signals. Automatic evaluation on three scientific document datasets verifies the effectiveness of the proposed framework. The further human evaluation suggests that the extracted summaries cover more content aspects than previous systems.