 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Extensions and Efficiency Trade-Offs for Sustainable Time Series Classification
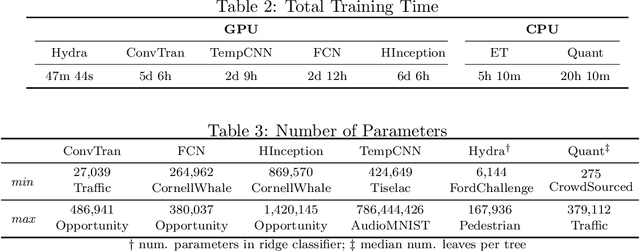
Apr 09, 2026Time series classification (TSC) enables important use cases, however lacks a unified understanding of performance trade-offs across models, datasets, and hardware. While resource awareness has grown in the field, TSC methods have not yet been rigorously evaluated for energy efficiency. This paper introduces a holistic evaluation framework that explicitly explores the balance of predictive performance and resource consumption in TSC. To boost efficiency, we apply a theoretically bounded pruning strategy to leading hybrid classifiers - Hydra and Quant - and present Hydrant, a novel, prunable combination of both. With over 4000 experimental configurations across 20 MONSTER datasets, 13 methods, and three compute setups, we systematically analyze how model design, hyperparameters, and hardware choices affect practical TSC performance. Our results showcase that pruning can significantly reduce energy consumption by up to 80% while maintaining competitive predictive quality, usually costing the model less than 5% of accuracy. The proposed methodology, experimental results, and accompanying software advance TSC toward sustainable and reproducible practice.
The Multiverse of Time Series Machine Learning: an Archive for Multivariate Time Series Classification
Mar 20, 2026Time series machine learning (TSML) is a growing research field that spans a wide range of tasks. The popularity of established tasks such as classification, clustering, and extrinsic regression has, in part, been driven by the availability of benchmark datasets. An archive of 30 multivariate time series classification datasets, introduced in 2018 and commonly known as the UEA archive, has since become an essential resource cited in hundreds of publications. We present a substantial expansion of this archive that more than quadruples its size, from 30 to 133 classification problems. We also release preprocessed versions of datasets containing missing values or unequal length series, bringing the total number of datasets to 147. Reflecting the growth of the archive and the broader community, we rebrand it as the Multiverse archive to capture its diversity of domains. The Multiverse archive includes datasets from multiple sources, consolidating other collections and standalone datasets into a single, unified repository. Recognising that running experiments across the full archive is computationally demanding, we recommend a subset of the full archive called Multiverse-core (MV-core) for initial exploration. To support researchers in using the new archive, we provide detailed guidance and a baseline evaluation of established and recent classification algorithms, establishing performance benchmarks for future research. We have created a dedicated repository for the Multiverse archive that provides a common aeon and scikit-learn compatible framework for reproducibility, an extensive record of published results, and an interactive interface to explore the results.
CEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025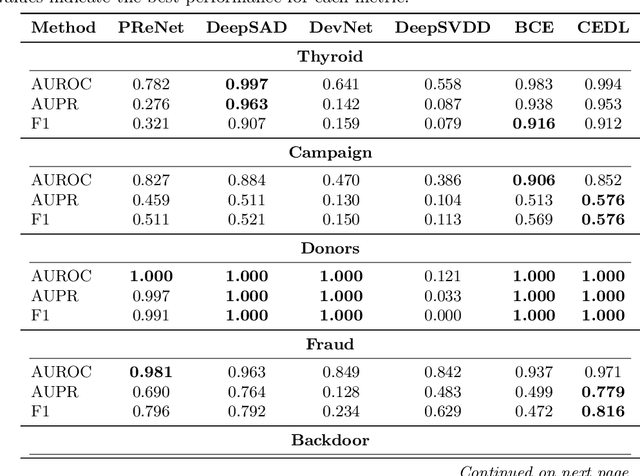
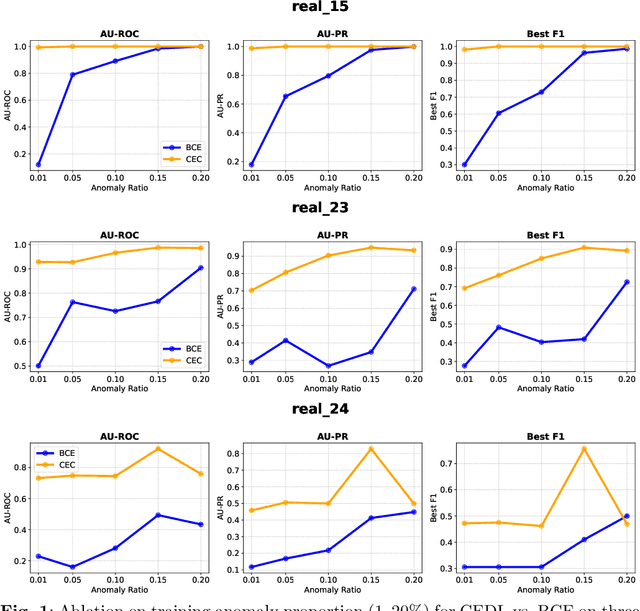
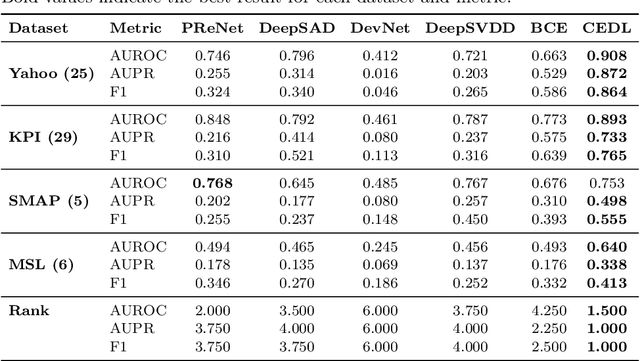
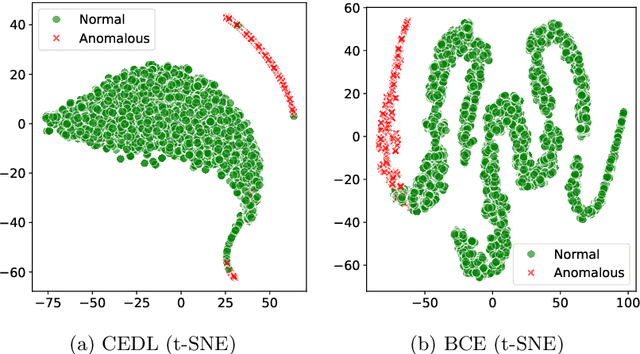
Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
EEG-X: Device-Agnostic and Noise-Robust Foundation Model for EEG
Nov 12, 2025



Foundation models for EEG analysis are still in their infancy, limited by two key challenges: (1) variability across datasets caused by differences in recording devices and configurations, and (2) the low signal-to-noise ratio (SNR) of EEG, where brain signals are often buried under artifacts and non-brain sources. To address these challenges, we present EEG-X, a device-agnostic and noise-robust foundation model for EEG representation learning. EEG-X introduces a novel location-based channel embedding that encodes spatial information and improves generalization across domains and tasks by allowing the model to handle varying channel numbers, combinations, and recording lengths. To enhance robustness against noise, EEG-X employs a noise-aware masking and reconstruction strategy in both raw and latent spaces. Unlike previous models that mask and reconstruct raw noisy EEG signals, EEG-X is trained to reconstruct denoised signals obtained through an artifact removal process, ensuring that the learned representations focus on neural activity rather than noise. To further enhance reconstruction-based pretraining, EEG-X introduces a dictionary-inspired convolutional transformation (DiCT) layer that projects signals into a structured feature space before computing reconstruction (MSE) loss, reducing noise sensitivity and capturing frequency- and shape-aware similarities. Experiments on datasets collected from diverse devices show that EEG-X outperforms state-of-the-art methods across multiple downstream EEG tasks and excels in cross-domain settings where pre-trained and downstream datasets differ in electrode layouts. The models and code are available at: https://github.com/Emotiv/EEG-X
Interpretable Representation Learning for Additive Rule Ensembles
Jun 26, 2025



Small additive ensembles of symbolic rules offer interpretable prediction models. Traditionally, these ensembles use rule conditions based on conjunctions of simple threshold propositions $x \geq t$ on a single input variable $x$ and threshold $t$, resulting geometrically in axis-parallel polytopes as decision regions. While this form ensures a high degree of interpretability for individual rules and can be learned efficiently using the gradient boosting approach, it relies on having access to a curated set of expressive and ideally independent input features so that a small ensemble of axis-parallel regions can describe the target variable well. Absent such features, reaching sufficient accuracy requires increasing the number and complexity of individual rules, which diminishes the interpretability of the model. Here, we extend classical rule ensembles by introducing logical propositions with learnable sparse linear transformations of input variables, i.e., propositions of the form $\mathbf{x}^\mathrm{T}\mathbf{w} \geq t$, where $\mathbf{w}$ is a learnable sparse weight vector, enabling decision regions as general polytopes with oblique faces. We propose a learning method using sequential greedy optimization based on an iteratively reweighted formulation of logistic regression. Experimental results demonstrate that the proposed method efficiently constructs rule ensembles with the same test risk as state-of-the-art methods while significantly reducing model complexity across ten benchmark datasets.
Uncertainty-Aware Graph Neural Networks: A Multi-Hop Evidence Fusion Approach
Jun 16, 2025Graph neural networks (GNNs) excel in graph representation learning by integrating graph structure and node features. Existing GNNs, unfortunately, fail to account for the uncertainty of class probabilities that vary with the depth of the model, leading to unreliable and risky predictions in real-world scenarios. To bridge the gap, in this paper, we propose a novel Evidence Fusing Graph Neural Network (EFGNN for short) to achieve trustworthy prediction, enhance node classification accuracy, and make explicit the risk of wrong predictions. In particular, we integrate the evidence theory with multi-hop propagation-based GNN architecture to quantify the prediction uncertainty of each node with the consideration of multiple receptive fields. Moreover, a parameter-free cumulative belief fusion (CBF) mechanism is developed to leverage the changes in prediction uncertainty and fuse the evidence to improve the trustworthiness of the final prediction. To effectively optimize the EFGNN model, we carefully design a joint learning objective composed of evidence cross-entropy, dissonance coefficient, and false confident penalty. The experimental results on various datasets and theoretical analyses demonstrate the effectiveness of the proposed model in terms of accuracy and trustworthiness, as well as its robustness to potential attacks. The source code of EFGNN is available at https://github.com/Shiy-Li/EFGNN.
Efficient Parameter Estimation for Bayesian Network Classifiers using Hierarchical Linear Smoothing
May 29, 2025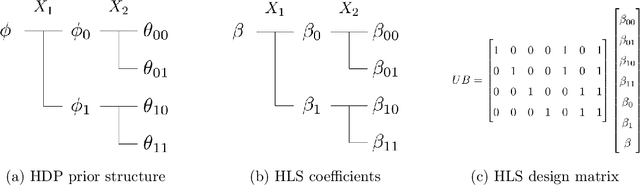

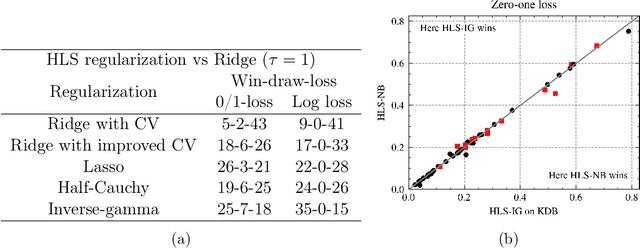

Bayesian network classifiers (BNCs) possess a number of properties desirable for a modern classifier: They are easily interpretable, highly scalable, and offer adaptable complexity. However, traditional methods for learning BNCs have historically underperformed when compared to leading classification methods such as random forests. Recent parameter smoothing techniques using hierarchical Dirichlet processes (HDPs) have enabled BNCs to achieve performance competitive with random forests on categorical data, but these techniques are relatively inflexible, and require a complicated, specialized sampling process. In this paper, we introduce a novel method for parameter estimation that uses a log-linear regression to approximate the behaviour of HDPs. As a linear model, our method is remarkably flexible and simple to interpret, and can leverage the vast literature on learning linear models. Our experiments show that our method can outperform HDP smoothing while being orders of magnitude faster, remaining competitive with random forests on categorical data.
MONSTER: Monash Scalable Time Series Evaluation Repository
Feb 21, 2025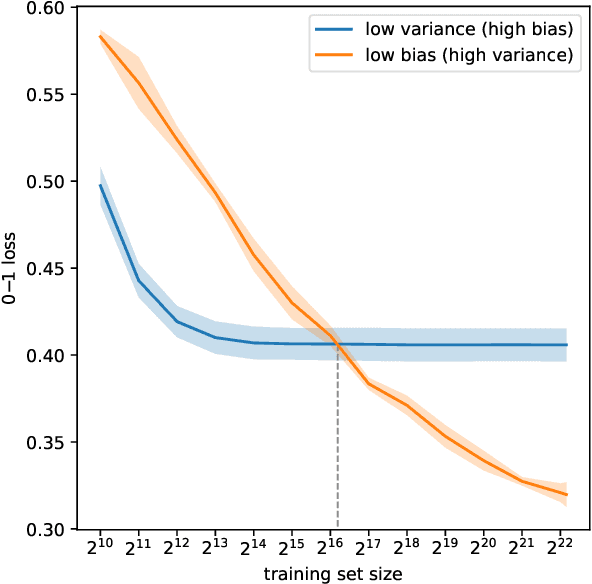
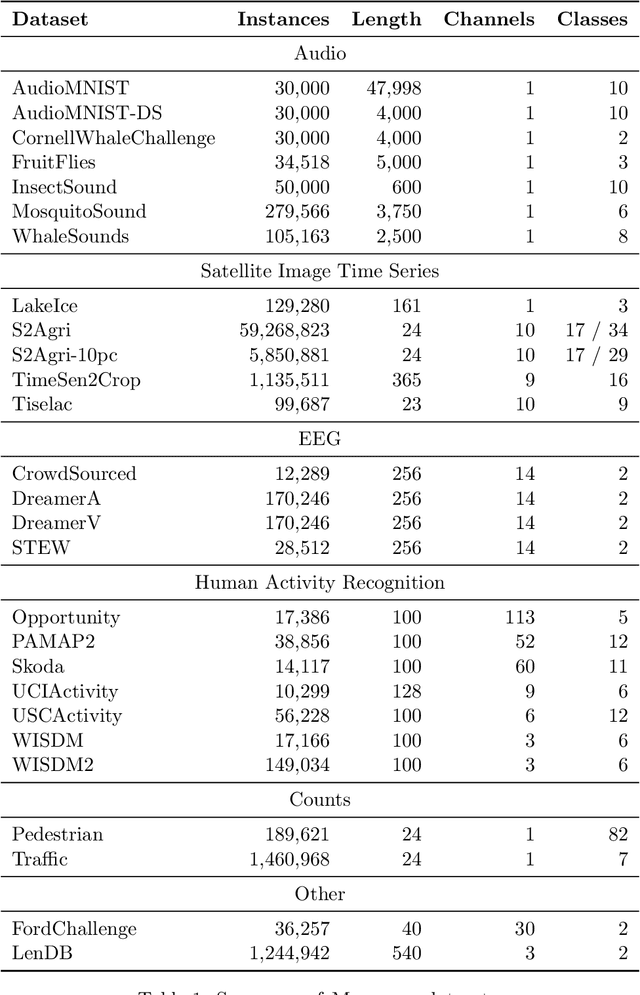
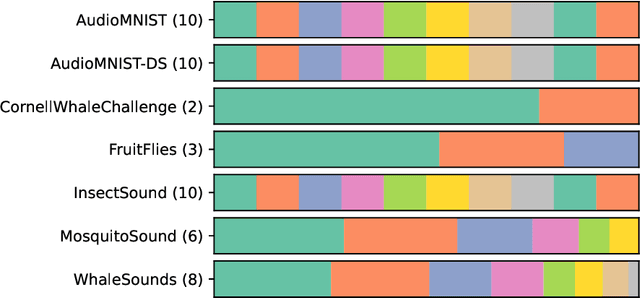
We introduce MONSTER-the MONash Scalable Time Series Evaluation Repository-a collection of large datasets for time series classification. The field of time series classification has benefitted from common benchmarks set by the UCR and UEA time series classification repositories. However, the datasets in these benchmarks are small, with median sizes of 217 and 255 examples, respectively. In consequence they favour a narrow subspace of models that are optimised to achieve low classification error on a wide variety of smaller datasets, that is, models that minimise variance, and give little weight to computational issues such as scalability. Our hope is to diversify the field by introducing benchmarks using larger datasets. We believe that there is enormous potential for new progress in the field by engaging with the theoretical and practical challenges of learning effectively from larger quantities of data.
GenIAS: Generator for Instantiating Anomalies in time Series
Feb 12, 2025



A recent and promising approach for building time series anomaly detection (TSAD) models is to inject synthetic samples of anomalies within real data sets. The existing injection mechanisms have significant limitations - most of them rely on ad hoc, hand-crafted strategies which fail to capture the natural diversity of anomalous patterns, or are restricted to univariate time series settings. To address these challenges, we design a generative model for TSAD using a variational autoencoder, which is referred to as a Generator for Instantiating Anomalies in Time Series (GenIAS). GenIAS is designed to produce diverse and realistic synthetic anomalies for TSAD tasks. By employing a novel learned perturbation mechanism in the latent space and injecting the perturbed patterns in different segments of time series, GenIAS can generate anomalies with greater diversity and varying scales. Further, guided by a new triplet loss function, which uses a min-max margin and a new variance-scaling approach to further enforce the learning of compact normal patterns, GenIAS ensures that anomalies are distinct from normal samples while remaining realistic. The approach is effective for both univariate and multivariate time series. We demonstrate the diversity and realism of the generated anomalies. Our extensive experiments demonstrate that GenIAS - when integrated into a TSAD task - consistently outperforms seventeen traditional and deep anomaly detection models, thereby highlighting the potential of generative models for time series anomaly generation.
Large Language Models in Drug Discovery and Development: From Disease Mechanisms to Clinical Trials
Sep 06, 2024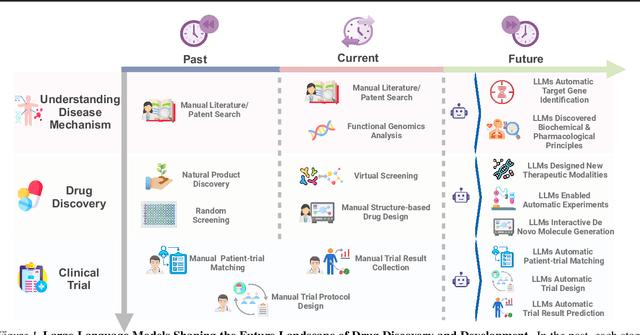
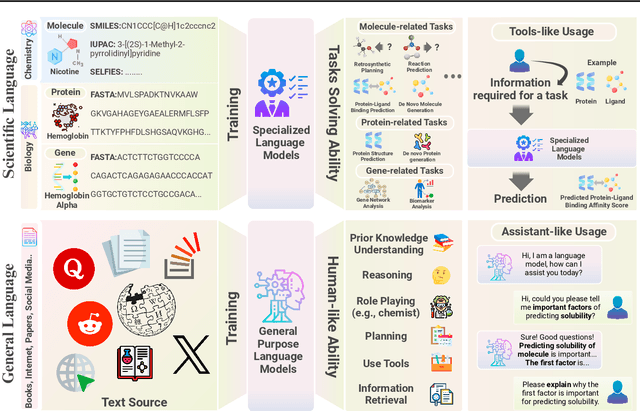
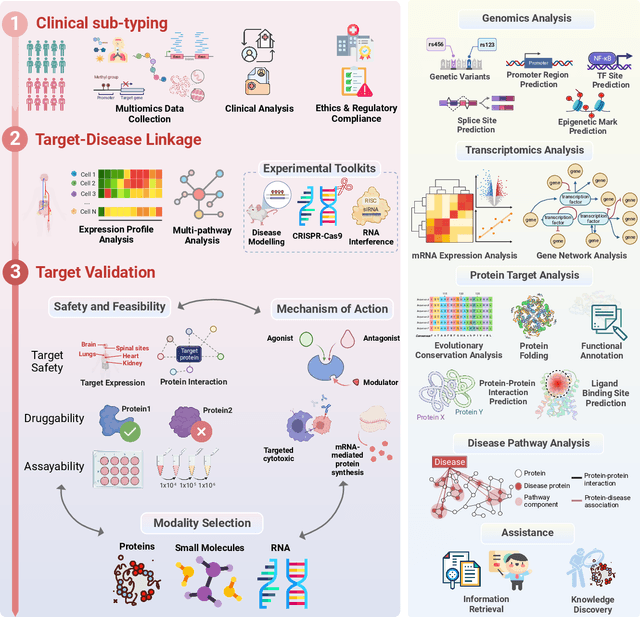
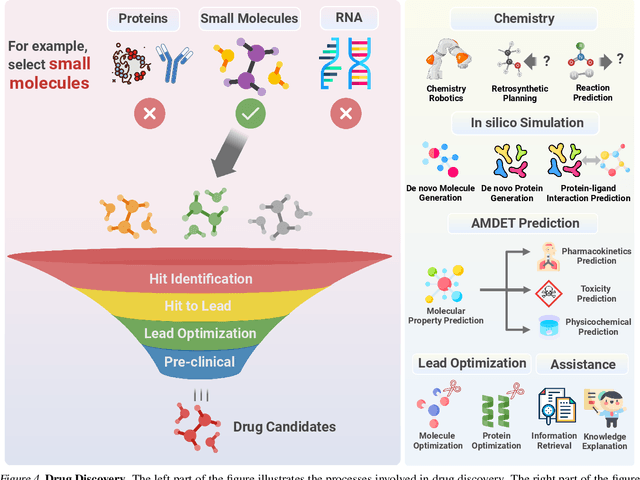
The integration of Large Language Models (LLMs) into the drug discovery and development field marks a significant paradigm shift, offering novel methodologies for understanding disease mechanisms, facilitating drug discovery, and optimizing clinical trial processes. This review highlights the expanding role of LLMs in revolutionizing various stages of the drug development pipeline. We investigate how these advanced computational models can uncover target-disease linkage, interpret complex biomedical data, enhance drug molecule design, predict drug efficacy and safety profiles, and facilitate clinical trial processes. Our paper aims to provide a comprehensive overview for researchers and practitioners in computational biology, pharmacology, and AI4Science by offering insights into the potential transformative impact of LLMs on drug discovery and development.