 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONSTER: Monash Scalable Time Series Evaluation Repository
Feb 21, 2025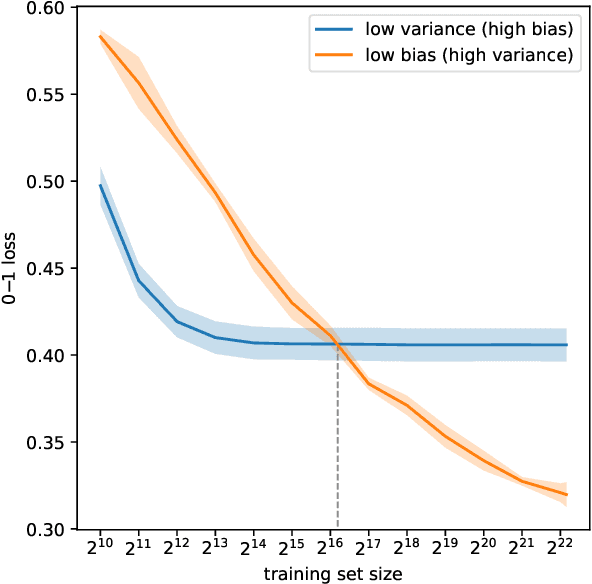
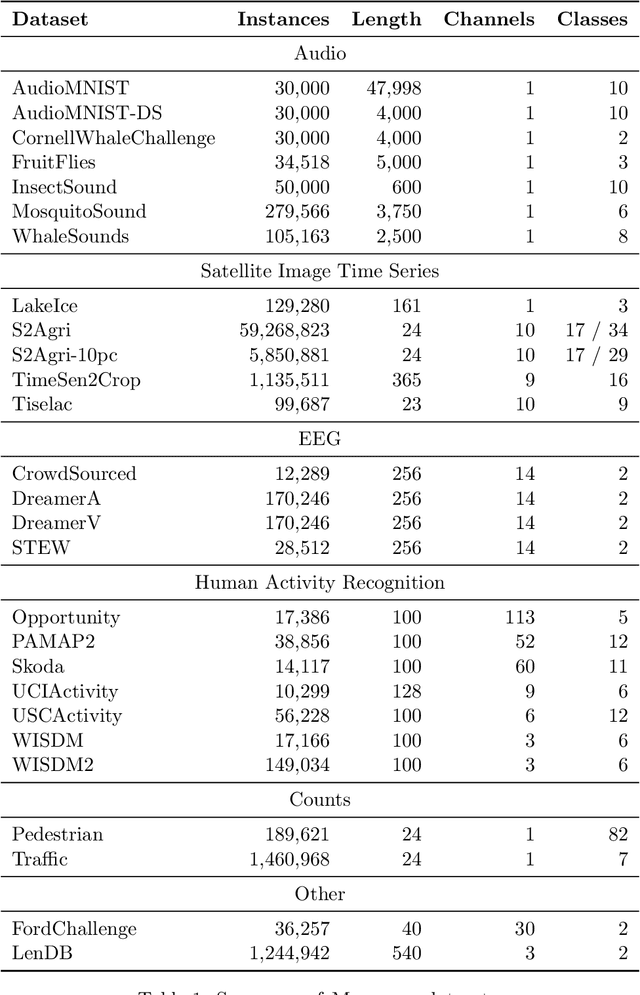
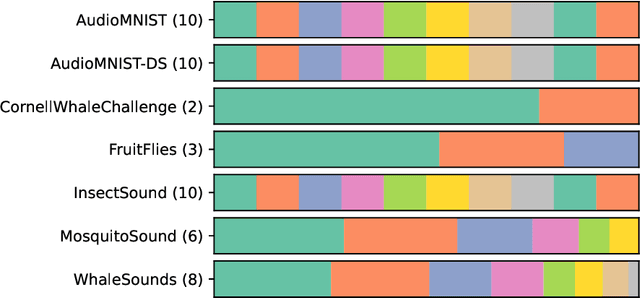
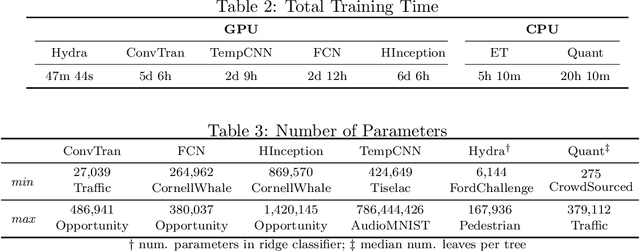
We introduce MONSTER-the MONash Scalable Time Series Evaluation Repository-a collection of large datasets for time series classification. The field of time series classification has benefitted from common benchmarks set by the UCR and UEA time series classification repositories. However, the datasets in these benchmarks are small, with median sizes of 217 and 255 examples, respectively. In consequence they favour a narrow subspace of models that are optimised to achieve low classification error on a wide variety of smaller datasets, that is, models that minimise variance, and give little weight to computational issues such as scalability. Our hope is to diversify the field by introducing benchmarks using larger datasets. We believe that there is enormous potential for new progress in the field by engaging with the theoretical and practical challenges of learning effectively from larger quantities of data.
Series2Vec: Similarity-based Self-supervised Representation Learning for Time Series Classification
Dec 12, 2023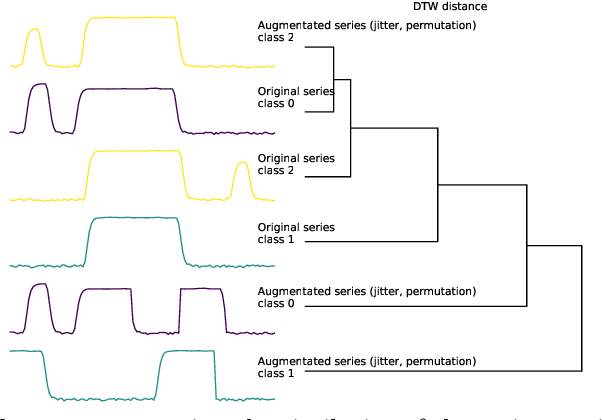
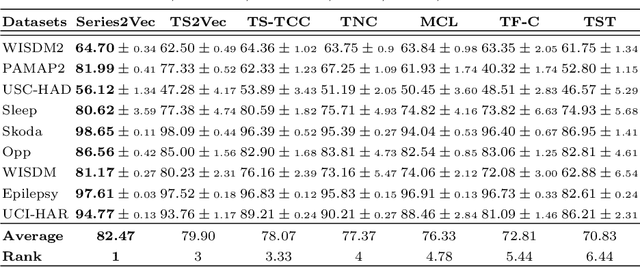
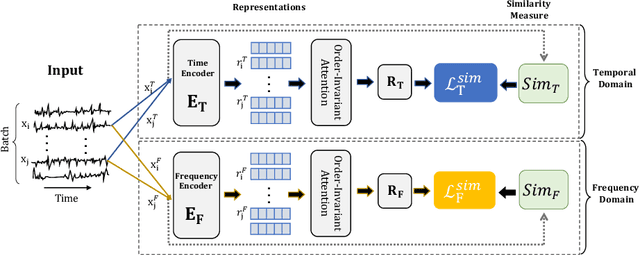

We argue that time series analysis is fundamentally different in nature to either vision or natural language processing with respect to the forms of meaningful self-supervised learning tasks that can be defined. Motivated by this insight, we introduce a novel approach called \textit{Series2Vec} for self-supervised representation learning. Unlike other self-supervised methods in time series, which carry the risk of positive sample variants being less similar to the anchor sample than series in the negative set, Series2Vec is trained to predict the similarity between two series in both temporal and spectral domains through a self-supervised task. Series2Vec relies primarily on the consistency of the unsupervised similarity step, rather than the intrinsic quality of the similarity measurement, without the need for hand-crafted data augmentation. To further enforce the network to learn similar representations for similar time series, we propose a novel approach that applies order-invariant attention to each representation within the batch during training. Our evaluation of Series2Vec on nine large real-world datasets, along with the UCR/UEA archive, shows enhanced performance compared to current state-of-the-art self-supervised techniques for time series. Additionally, our extensive experiments show that Series2Vec performs comparably with fully supervised training and offers high efficiency in datasets with limited-labeled data. Finally, we show that the fusion of Series2Vec with other representation learning models leads to enhanced performance for time series classification. Code and models are open-source at \url{https://github.com/Navidfoumani/Series2Vec.}
Improving Position Encoding of Transformers for Multivariate Time Series Classification
May 26, 2023Transformers have demonstrated outstanding performance in many applications of deep learning. When applied to time series data, transformers require effective position encoding to capture the ordering of the time series data. The efficacy of position encoding in time series analysis is not well-studied and remains controversial, e.g., whether it is better to inject absolute position encoding or relative position encoding, or a combination of them. In order to clarify this, we first review existing absolute and relative position encoding methods when applied in time series classification. We then proposed a new absolute position encoding method dedicated to time series data called time Absolute Position Encoding (tAPE). Our new method incorporates the series length and input embedding dimension in absolute position encoding. Additionally, we propose computationally Efficient implementation of Relative Position Encoding (eRPE) to improve generalisability for time series. We then propose a novel multivariate time series classification (MTSC) model combining tAPE/eRPE and convolution-based input encoding named ConvTran to improve the position and data embedding of time series data. The proposed absolute and relative position encoding methods are simple and efficient. They can be easily integrated into transformer blocks and used for downstream tasks such as forecasting, extrinsic regression, and anomaly detection. Extensive experiments on 32 multivariate time-series datasets show that our model is significantly more accurate than state-of-the-art convolution and transformer-based models. Code and models are open-sourced at \url{https://github.com/Navidfoumani/ConvTran}.
An Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
May 19, 2023
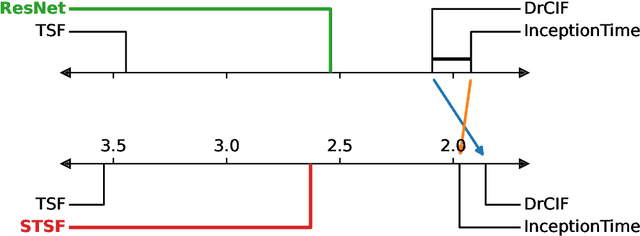
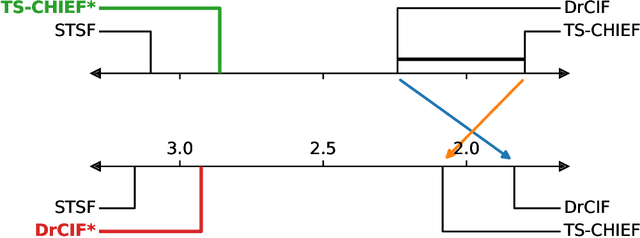
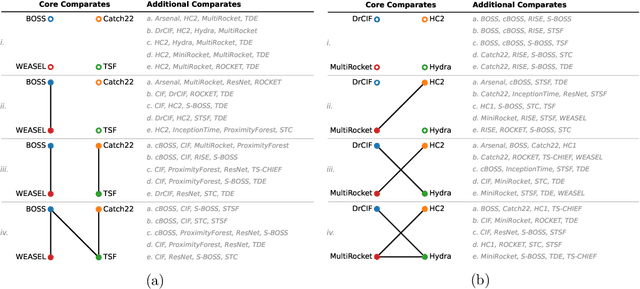
The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
Proximity Forest 2.0: A new effective and scalable similarity-based classifier for time series
Apr 13, 2023



Time series classification (TSC) is a challenging task due to the diversity of types of feature that may be relevant for different classification tasks, including trends, variance, frequency, magnitude, and various patterns. To address this challenge, several alternative classes of approach have been developed, including similarity-based, features and intervals, shapelets, dictionary, kernel, neural network, and hybrid approaches. While kernel, neural network, and hybrid approaches perform well overall, some specialized approaches are better suited for specific tasks. In this paper, we propose a new similarity-based classifier, Proximity Forest version 2.0 (PF 2.0), which outperforms previous state-of-the-art similarity-based classifiers across the UCR benchmark and outperforms state-of-the-art kernel, neural network, and hybrid methods on specific datasets in the benchmark that are best addressed by similarity-base methods. PF 2.0 incorporates three recent advances in time series similarity measures -- (1) computationally efficient early abandoning and pruning to speedup elastic similarity computations; (2) a new elastic similarity measure, Amerced Dynamic Time Warping (ADTW); and (3) cost function tuning. It rationalizes the set of similarity measures employed, reducing the eight base measures of the original PF to three and using the first derivative transform with all similarity measures, rather than a limited subset. We have implemented both PF 1.0 and PF 2.0 in a single C++ framework, making the PF framework more efficient.
Deep Learning for Time Series Classification and Extrinsic Regression: A Current Survey
Feb 06, 2023



Time Series Classification and Extrinsic Regression are important and challenging machine learning tasks. Deep learning has revolutionized natural language processing and computer vision and holds great promise in other fields such as time series analysis where the relevant features must often be abstracted from the raw data but are not known a priori. This paper surveys the current state of the art in the fast-moving field of deep learning for time series classification and extrinsic regression. We review different network architectures and training methods used for these tasks and discuss the challenges and opportunities when applying deep learning to time series data. We also summarize two critical applications of time series classification and extrinsic regression, human activity recognition and satellite earth observation.
Parameterizing the cost function of Dynamic Time Warping with application to time series classification
Jan 24, 2023Dynamic Time Warping (DTW) is a popular time series distance measure that aligns the points in two series with one another. These alignments support warping of the time dimension to allow for processes that unfold at differing rates. The distance is the minimum sum of costs of the resulting alignments over any allowable warping of the time dimension. The cost of an alignment of two points is a function of the difference in the values of those points. The original cost function was the absolute value of this difference. Other cost functions have been proposed. A popular alternative is the square of the difference. However, to our knowledge, this is the first investigation of both the relative impacts of using different cost functions and the potential to tune cost functions to different tasks. We do so in this paper by using a tunable cost function {\lambda}{\gamma} with parameter {\gamma}. We show that higher values of {\gamma} place greater weight on larger pairwise differences, while lower values place greater weight on smaller pairwise differences. We demonstrate that training {\gamma} significantly improves the accuracy of both the DTW nearest neighbor and Proximity Forest classifiers.
FRANS: Automatic Feature Extraction for Time Series Forecasting
Sep 15, 2022
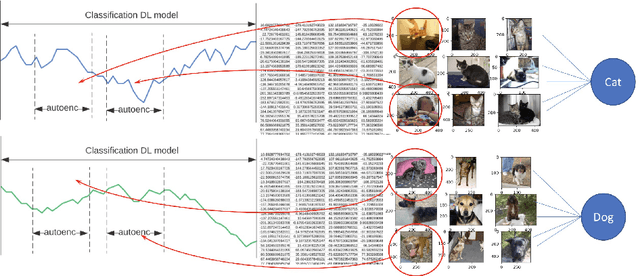
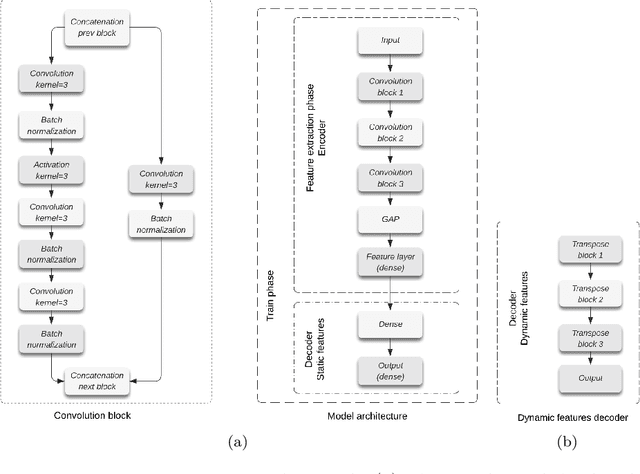
Feature extraction methods help in dimensionality reduction and capture relevant information. In time series forecasting (TSF), features can be used as auxiliary information to achieve better accuracy. Traditionally, features used in TSF are handcrafted, which requires domain knowledge and significant data-engineering work. In this research, we first introduce a notion of static and dynamic features, which then enables us to develop our autonomous Feature Retrieving Autoregressive Network for Static features (FRANS) that does not require domain knowledge. The method is based on a CNN classifier that is trained to create for each series a collective and unique class representation either from parts of the series or, if class labels are available, from a set of series of the same class. It allows to discriminate series with similar behaviour but from different classes and makes the features extracted from the classifier to be maximally discriminatory. We explore the interpretability of our features, and evaluate the prediction capabilities of the method within the forecasting meta-learning environment FFORMA. Our results show that our features lead to improvement in accuracy in most situations. Once trained our approach creates features orders of magnitude faster than statistical methods.
Classification of multivariate weakly-labelled time-series with attention
Feb 21, 2021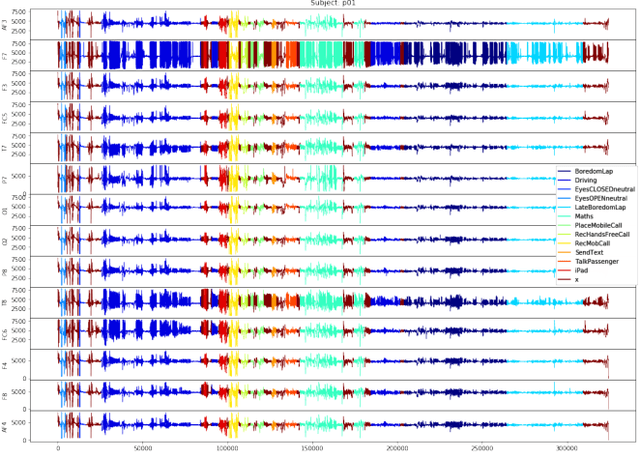
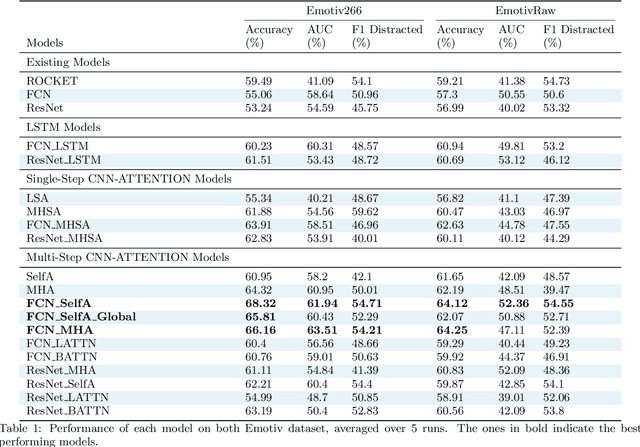
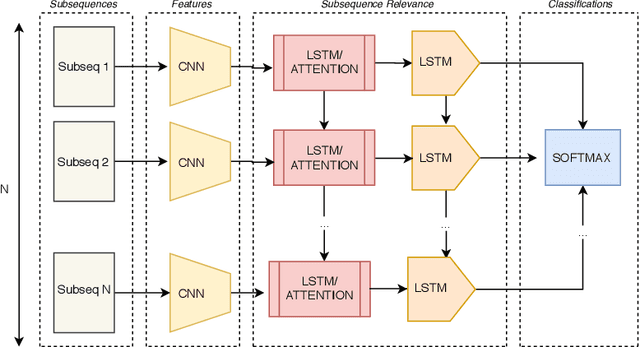
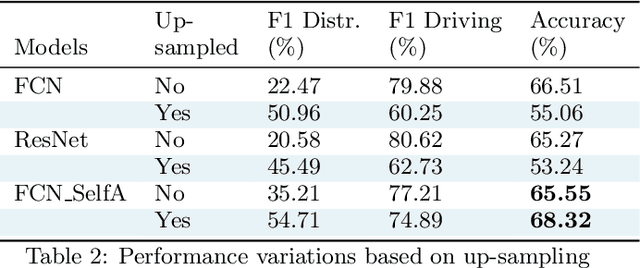
This research identifies a gap in weakly-labelled multivariate time-series classification (TSC), where state-of-the-art TSC models do not per-form well. Weakly labelled time-series are time-series containing noise and significant redundancies. In response to this gap, this paper proposes an approach of exploiting context relevance of subsequences from previous subsequences to improve classification accuracy. To achieve this, state-of-the-art Attention algorithms are experimented in combination with the top CNN models for TSC (FCN and ResNet), in an CNN-LSTM architecture. Attention is a popular strategy for context extraction with exceptional performance in modern sequence-to-sequence tasks. This paper shows how attention algorithms can be used for improved weakly labelledTSC by evaluating models on a multivariate EEG time-series dataset obtained using a commercial Emotiv headsets from participants performing various activities while driving. These time-series are segmented into sub-sequences and labelled to allow supervised TSC.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
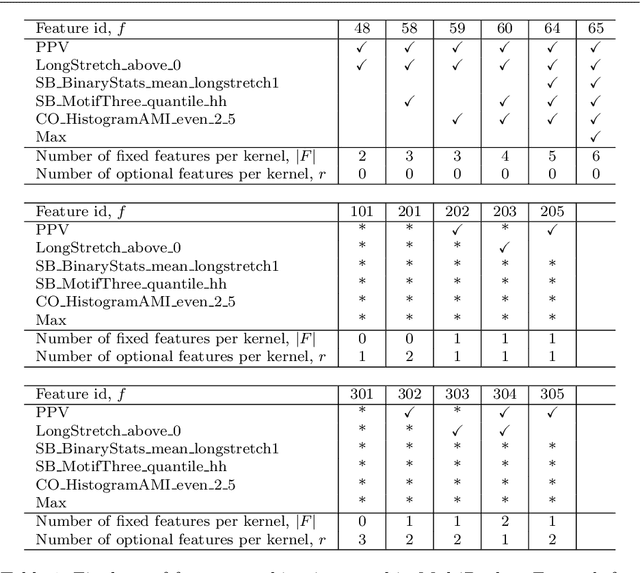
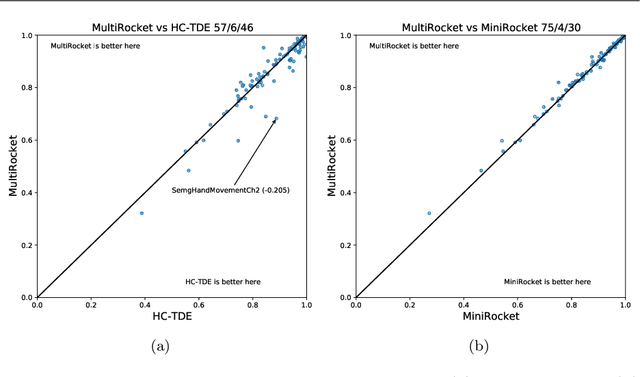

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors