 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo MoCap Needed: Post-Training Motion Diffusion Models with Reinforcement Learning using Only Textual Prompts
Oct 08, 2025



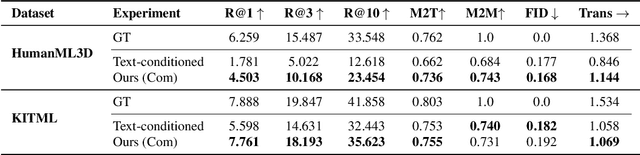
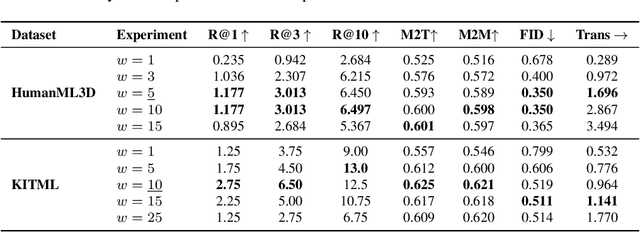
Diffusion models have recently advanced human motion generation, producing realistic and diverse animations from textual prompts. However, adapting these models to unseen actions or styles typically requires additional motion capture data and full retraining, which is costly and difficult to scale. We propose a post-training framework based on Reinforcement Learning that fine-tunes pretrained motion diffusion models using only textual prompts, without requiring any motion ground truth. Our approach employs a pretrained text-motion retrieval network as a reward signal and optimizes the diffusion policy with Denoising Diffusion Policy Optimization, effectively shifting the model's generative distribution toward the target domain without relying on paired motion data. We evaluate our method on cross-dataset adaptation and leave-one-out motion experiments using the HumanML3D and KIT-ML datasets across both latent- and joint-space diffusion architectures. Results from quantitative metrics and user studies show that our approach consistently improves the quality and diversity of generated motions, while preserving performance on the original distribution. Our approach is a flexible, data-efficient, and privacy-preserving solution for motion adaptation.
Deep Learning for Skeleton Based Human Motion Rehabilitation Assessment: A Benchmark
Jul 28, 2025Automated assessment of human motion plays a vital role in rehabilitation, enabling objective evaluation of patient performance and progress. Unlike general human activity recognition, rehabilitation motion assessment focuses on analyzing the quality of movement within the same action class, requiring the detection of subtle deviations from ideal motion. Recent advances in deep learning and video-based skeleton extraction have opened new possibilities for accessible, scalable motion assessment using affordable devices such as smartphones or webcams. However, the field lacks standardized benchmarks, consistent evaluation protocols, and reproducible methodologies, limiting progress and comparability across studies. In this work, we address these gaps by (i) aggregating existing rehabilitation datasets into a unified archive called Rehab-Pile, (ii) proposing a general benchmarking framework for evaluating deep learning methods in this domain, and (iii) conducting extensive benchmarking of multiple architectures across classification and regression tasks. All datasets and implementations are released to the community to support transparency and reproducibility. This paper aims to establish a solid foundation for future research in automated rehabilitation assessment and foster the development of reliable, accessible, and personalized rehabilitation solutions. The datasets, source-code and results of this article are all publicly available.
3D Face Reconstruction Error Decomposed: A Modular Benchmark for Fair and Fast Method Evaluation
May 23, 2025Computing the standard benchmark metric for 3D face reconstruction, namely geometric error, requires a number of steps, such as mesh cropping, rigid alignment, or point correspondence. Current benchmark tools are monolithic (they implement a specific combination of these steps), even though there is no consensus on the best way to measure error. We present a toolkit for a Modularized 3D Face reconstruction Benchmark (M3DFB), where the fundamental components of error computation are segregated and interchangeable, allowing one to quantify the effect of each. Furthermore, we propose a new component, namely correction, and present a computationally efficient approach that penalizes for mesh topology inconsistency. Using this toolkit, we test 16 error estimators with 10 reconstruction methods on two real and two synthetic datasets. Critically, the widely used ICP-based estimator provides the worst benchmarking performance, as it significantly alters the true ranking of the top-5 reconstruction methods. Notably, the correlation of ICP with the true error can be as low as 0.41. Moreover, non-rigid alignment leads to significant improvement (correlation larger than 0.90), highlighting the importance of annotating 3D landmarks on datasets. Finally, the proposed correction scheme, together with non-rigid warping, leads to an accuracy on a par with the best non-rigid ICP-based estimators, but runs an order of magnitude faster. Our open-source codebase is designed for researchers to easily compare alternatives for each component, thus helping accelerating progress in benchmarking for 3D face reconstruction and, furthermore, supporting the improvement of learned reconstruction methods, which depend on accurate error estimation for effective training.
Beyond Fixed Topologies: Unregistered Training and Comprehensive Evaluation Metrics for 3D Talking Heads
Oct 14, 2024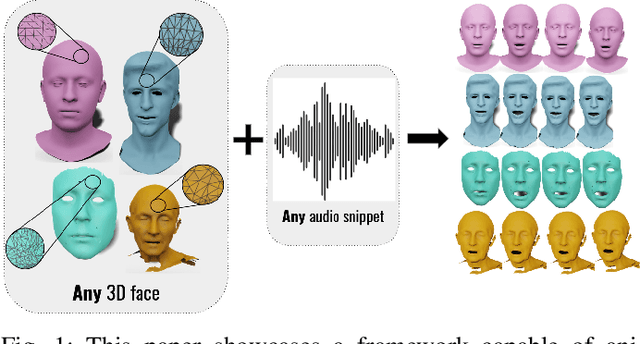
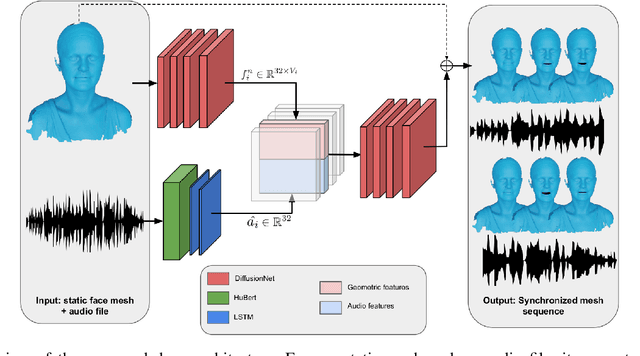
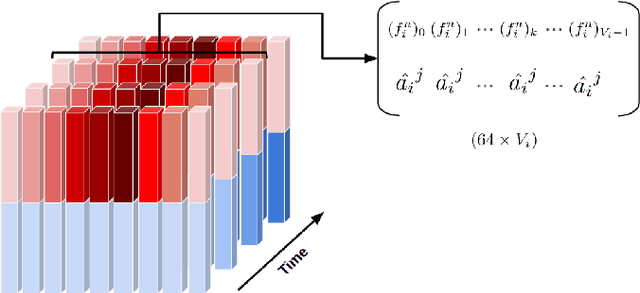

Generating speech-driven 3D talking heads presents numerous challenges; among those is dealing with varying mesh topologies. Existing methods require a registered setting, where all meshes share a common topology: a point-wise correspondence across all meshes the model can animate. While simplifying the problem, it limits applicability as unseen meshes must adhere to the training topology. This work presents a framework capable of animating 3D faces in arbitrary topologies, including real scanned data. Our approach relies on a model leveraging heat diffusion over meshes to overcome the fixed topology constraint. We explore two training settings: a supervised one, in which training sequences share a fixed topology within a sequence but any mesh can be animated at test time, and an unsupervised one, which allows effective training with varying mesh structures. Additionally, we highlight the limitations of current evaluation metrics and propose new metrics for better lip-syncing evaluation between speech and facial movements. Our extensive evaluation shows our approach performs favorably compared to fixed topology techniques, setting a new benchmark by offering a versatile and high-fidelity solution for 3D talking head generation.
Generation of Complex 3D Human Motion by Temporal and Spatial Composition of Diffusion Models
Sep 18, 2024

In this paper, we address the challenge of generating realistic 3D human motions for action classes that were never seen during the training phase. Our approach involves decomposing complex actions into simpler movements, specifically those observed during training, by leveraging the knowledge of human motion contained in GPTs models. These simpler movements are then combined into a single, realistic animation using the properties of diffusion models. Our claim is that this decomposition and subsequent recombination of simple movements can synthesize an animation that accurately represents the complex input action. This method operates during the inference phase and can be integrated with any pre-trained diffusion model, enabling the synthesis of motion classes not present in the training data. We evaluate our method by dividing two benchmark human motion datasets into basic and complex actions, and then compare its performance against the state-of-the-art.
Look Into the LITE in Deep Learning for Time Series Classification
Sep 04, 2024



Deep learning models have been shown to be a powerful solution for Time Series Classification (TSC). State-of-the-art architectures, while producing promising results on the UCR and the UEA archives , present a high number of trainable parameters. This can lead to long training with high CO2 emission, power consumption and possible increase in the number of FLoating-point Operation Per Second (FLOPS). In this paper, we present a new architecture for TSC, the Light Inception with boosTing tEchnique (LITE) with only 2.34% of the number of parameters of the state-of-the-art InceptionTime model, while preserving performance. This architecture, with only 9, 814 trainable parameters due to the usage of DepthWise Separable Convolutions (DWSC), is boosted by three techniques: multiplexing, custom filters, and dilated convolution. The LITE architecture, trained on the UCR, is 2.78 times faster than InceptionTime and consumes 2.79 times less CO2 and power. To evaluate the performance of the proposed architecture on multivariate time series data, we adapt LITE to handle multivariate time series, we call this version LITEMV. To bring theory into application, we also conducted experiments using LITEMV on multivariate time series representing human rehabilitation movements, showing that LITEMV not only is the most efficient model but also the best performing for this application on the Kimore dataset, a skeleton based human rehabilitation exercises dataset. Moreover, to address the interpretability of LITEMV, we present a study using Class Activation Maps to understand the classification decision taken by the model during evaluation.
JambaTalk: Speech-Driven 3D Talking Head Generation Based on Hybrid Transformer-Mamba Language Model
Aug 03, 2024In recent years, talking head generation has become a focal point for researchers. Considerable effort is being made to refine lip-sync motion, capture expressive facial expressions, generate natural head poses, and achieve high video quality. However, no single model has yet achieved equivalence across all these metrics. This paper aims to animate a 3D face using Jamba, a hybrid Transformers-Mamba model. Mamba, a pioneering Structured State Space Model (SSM) architecture, was designed to address the constraints of the conventional Transformer architecture. Nevertheless, it has several drawbacks. Jamba merges the advantages of both Transformer and Mamba approaches, providing a holistic solution. Based on the foundational Jamba block, we present JambaTalk to enhance motion variety and speed through multimodal integration. Extensive experiments reveal that our method achieves performance comparable or superior to state-of-the-art models.
Establishing a Unified Evaluation Framework for Human Motion Generation: A Comparative Analysis of Metrics
May 13, 2024



The development of generative artificial intelligence for human motion generation has expanded rapidly, necessitating a unified evaluation framework. This paper presents a detailed review of eight evaluation metrics for human motion generation, highlighting their unique features and shortcomings. We propose standardized practices through a unified evaluation setup to facilitate consistent model comparisons. Additionally, we introduce a novel metric that assesses diversity in temporal distortion by analyzing warping diversity, thereby enhancing the evaluation of temporal data. We also conduct experimental analyses of three generative models using a publicly available dataset, offering insights into the interpretation of each metric in specific case scenarios. Our goal is to offer a clear, user-friendly evaluation framework for newcomers, complemented by publicly accessible code.
ScanTalk: 3D Talking Heads from Unregistered Scans
Mar 19, 2024

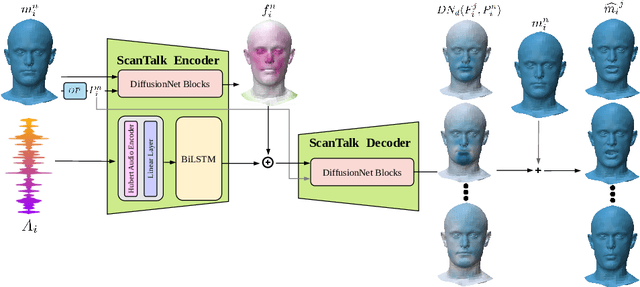

Speech-driven 3D talking heads generation has emerged as a significant area of interest among researchers, presenting numerous challenges. Existing methods are constrained by animating faces with fixed topologies, wherein point-wise correspondence is established, and the number and order of points remains consistent across all identities the model can animate. In this work, we present ScanTalk, a novel framework capable of animating 3D faces in arbitrary topologies including scanned data. Our approach relies on the DiffusionNet architecture to overcome the fixed topology constraint, offering promising avenues for more flexible and realistic 3D animations. By leveraging the power of DiffusionNet, ScanTalk not only adapts to diverse facial structures but also maintains fidelity when dealing with scanned data, thereby enhancing the authenticity and versatility of generated 3D talking heads. Through comprehensive comparisons with state-of-the-art methods, we validate the efficacy of our approach, demonstrating its capacity to generate realistic talking heads comparable to existing techniques. While our primary objective is to develop a generic method free from topological constraints, all state-of-the-art methodologies are bound by such limitations. Code for reproducing our results, and the pre-trained model will be made available.
EmoVOCA: Speech-Driven Emotional 3D Talking Heads
Mar 19, 2024



The domain of 3D talking head generation has witnessed significant progress in recent years. A notable challenge in this field consists in blending speech-related motions with expression dynamics, which is primarily caused by the lack of comprehensive 3D datasets that combine diversity in spoken sentences with a variety of facial expressions. Whereas literature works attempted to exploit 2D video data and parametric 3D models as a workaround, these still show limitations when jointly modeling the two motions. In this work, we address this problem from a different perspective, and propose an innovative data-driven technique that we used for creating a synthetic dataset, called EmoVOCA, obtained by combining a collection of inexpressive 3D talking heads and a set of 3D expressive sequences. To demonstrate the advantages of this approach, and the quality of the dataset, we then designed and trained an emotional 3D talking head generator that accepts a 3D face, an audio file, an emotion label, and an intensity value as inputs, and learns to animate the audio-synchronized lip movements with expressive traits of the face. Comprehensive experiments, both quantitative and qualitative, using our data and generator evidence superior ability in synthesizing convincing animations, when compared with the best performing methods in the literature. Our code and pre-trained model will be made available.