 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeDBA: Generating Effective Time Series Prototypes using ShapeDTW Barycenter Averaging
Sep 28, 2023



Time series data can be found in almost every domain, ranging from the medical field to manufacturing and wireless communication. Generating realistic and useful exemplars and prototypes is a fundamental data analysis task. In this paper, we investigate a novel approach to generating realistic and useful exemplars and prototypes for time series data. Our approach uses a new form of time series average, the ShapeDTW Barycentric Average. We therefore turn our attention to accurately generating time series prototypes with a novel approach. The existing time series prototyping approaches rely on the Dynamic Time Warping (DTW) similarity measure such as DTW Barycentering Average (DBA) and SoftDBA. These last approaches suffer from a common problem of generating out-of-distribution artifacts in their prototypes. This is mostly caused by the DTW variant used and its incapability of detecting neighborhood similarities, instead it detects absolute similarities. Our proposed method, ShapeDBA, uses the ShapeDTW variant of DTW, that overcomes this issue. We chose time series clustering, a popular form of time series analysis to evaluate the outcome of ShapeDBA compared to the other prototyping approaches. Coupled with the k-means clustering algorithm, and evaluated on a total of 123 datasets from the UCR archive, our proposed averaging approach is able to achieve new state-of-the-art results in terms of Adjusted Rand Index.
Estimating Divergences in High Dimensions
Dec 08, 2021



The problem of estimating the divergence between 2 high dimensional distributions with limited samples is an important problem in various fields such as machine learning. Although previous methods perform well with moderate dimensional data, their accuracy starts to degrade in situations with 100s of binary variables. Therefore, we propose the use of decomposable models for estimating divergences in high dimensional data. These allow us to factorize the estimated density of the high-dimensional distribution into a product of lower dimensional functions. We conduct formal and experimental analyses to explore the properties of using decomposable models in the context of divergence estimation. To this end, we show empirically that estimating the Kullback-Leibler divergence using decomposable models from a maximum likelihood estimator outperforms existing methods for divergence estimation in situations where dimensionality is high and useful decomposable models can be learnt from the available data.
A Bayesian-inspired, deep learning, semi-supervised domain adaptation technique for land cover mapping
May 25, 2020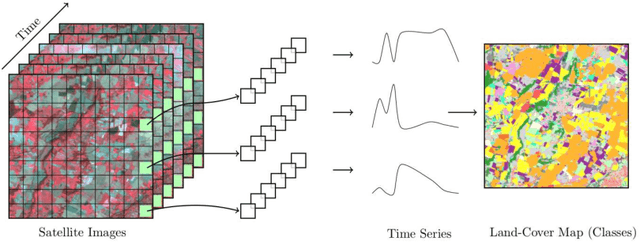
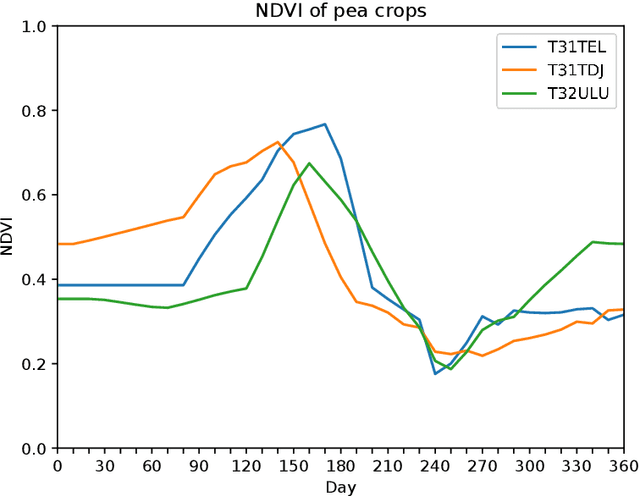
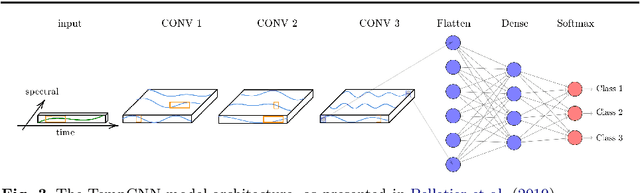
Land cover maps are a vital input variable to many types of environmental research and management. While they can be produced automatically by machine learning techniques, these techniques require substantial training data to achieve high levels of accuracy, which are not always available. One technique researchers use when labelled training data are scarce is domain adaptation (DA) -- where data from an alternate region, known as the source domain, are used to train a classifier and this model is adapted to map the study region, or target domain. The scenario we address in this paper is known as semi-supervised DA, where some labelled samples are available in the target domain. In this paper we present Sourcerer, a Bayesian-inspired, deep learning-based, semi-supervised DA technique for producing land cover maps from SITS data. The technique takes a convolutional neural network trained on a source domain and then trains further on the available target domain with a novel regularizer applied to the model weights. The regularizer adjusts the degree to which the model is modified to fit the target data, limiting the degree of change when the target data are few in number and increasing it as target data quantity increases. Our experiments on Sentinel-2 time series images compare Sourcerer with two state-of-the-art semi-supervised domain adaptation techniques and four baseline models. We show that on two different source-target domain pairings Sourcerer outperforms all other methods for any quantity of labelled target data available. In fact, the results on the more difficult target domain show that the starting accuracy of Sourcerer (when no labelled target data are available), 74.2%, is greater than the next-best state-of-the-art method trained on 20,000 labelled target instances.
ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels
Oct 29, 2019

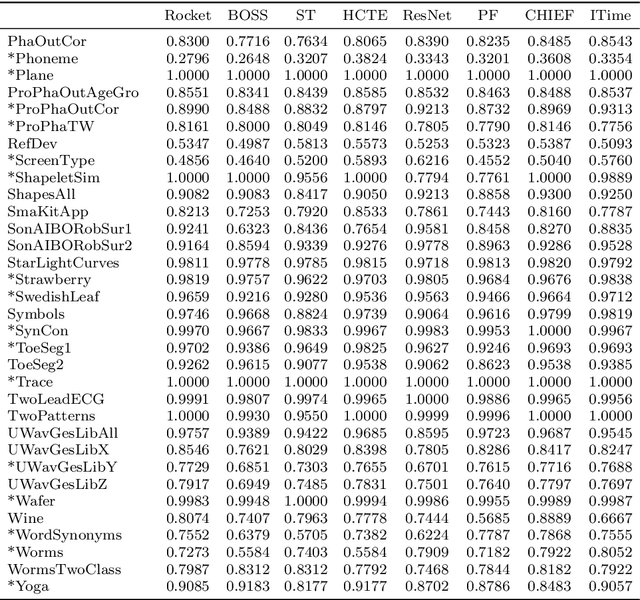

Most methods for time series classification that attain state-of-the-art accuracy have high computational complexity, requiring significant training time even for smaller datasets, and are intractable for larger datasets. Additionally, many existing methods focus on a single type of feature such as shape or frequency. Building on the recent success of convolutional neural networks for time series classification, we show that simple linear classifiers using random convolutional kernels achieve state-of-the-art accuracy with a fraction of the computational expense of existing methods.
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019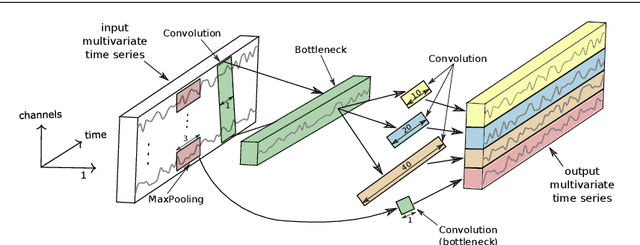
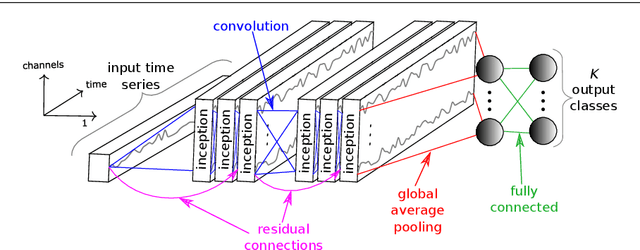
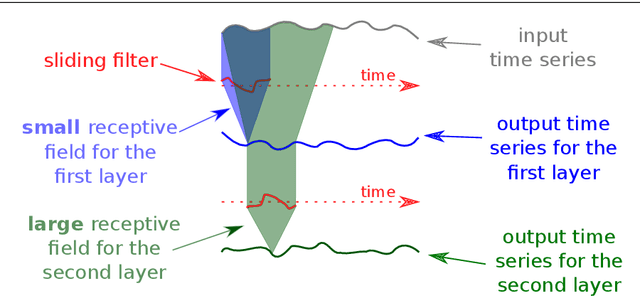
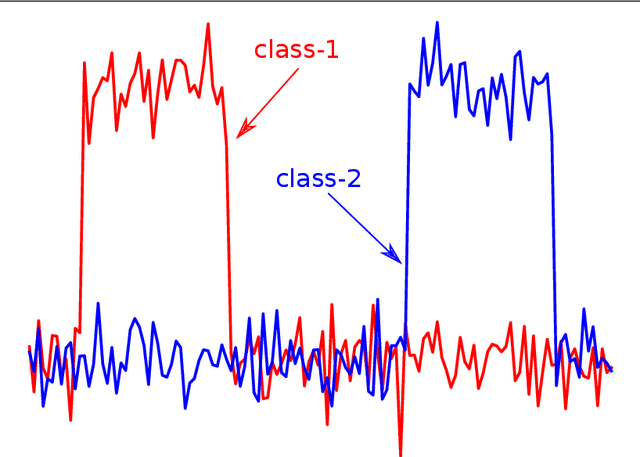
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Automatic alignment of surgical videos using kinematic data
Apr 26, 2019



Over the past one hundred years, the classic teaching methodology of "see one, do one, teach one" has governed the surgical education systems worldwide. With the advent of Operation Room 2.0, recording video, kinematic and many other types of data during the surgery became an easy task, thus allowing artificial intelligence systems to be deployed and used in surgical and medical practice. Recently, surgical videos has been shown to provide a structure for peer coaching enabling novice trainees to learn from experienced surgeons by replaying those videos. However, the high inter-operator variability in surgical gesture duration and execution renders learning from comparing novice to expert surgical videos a very difficult task. In this paper, we propose a novel technique to align multiple videos based on the alignment of their corresponding kinematic multivariate time series data. By leveraging the Dynamic Time Warping measure, our algorithm synchronizes a set of videos in order to show the same gesture being performed at different speed. We believe that the proposed approach is a valuable addition to the existing learning tools for surgery.
Understanding Concept Drift
Apr 02, 2017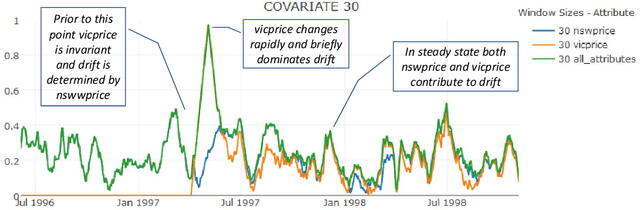
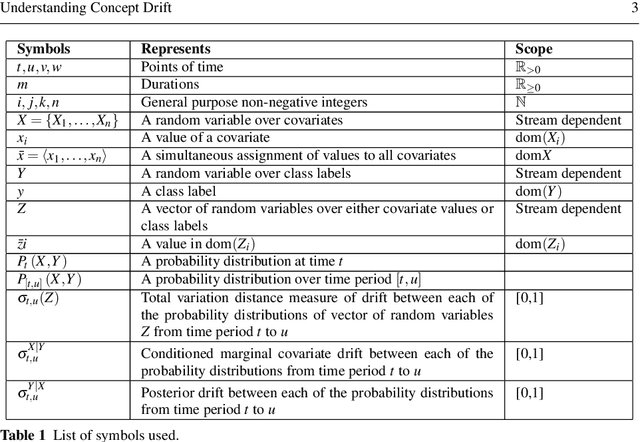
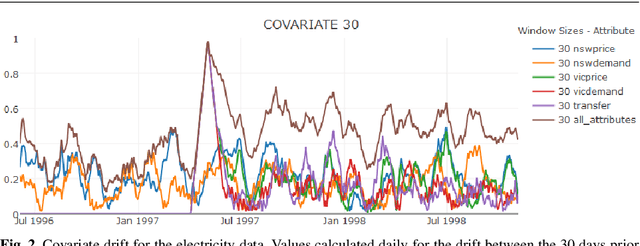
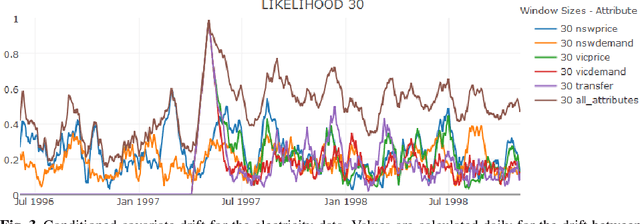
Concept drift is a major issue that greatly affects the accuracy and reliability of many real-world applications of machine learning. We argue that to tackle concept drift it is important to develop the capacity to describe and analyze it. We propose tools for this purpose, arguing for the importance of quantitative descriptions of drift in marginal distributions. We present quantitative drift analysis techniques along with methods for communicating their results. We demonstrate their effectiveness by application to three real-world learning tasks.