 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Detection of Relevant Objectives and Adaptation to Preference Drifts in Interactive Evolutionary Multi-Objective Optimization
Nov 07, 2024



Evolutionary Multi-Objective Optimization Algorithms (EMOAs) are widely employed to tackle problems with multiple conflicting objectives. Recent research indicates that not all objectives are equally important to the decision-maker (DM). In the context of interactive EMOAs, preference information elicited from the DM during the optimization process can be leveraged to identify and discard irrelevant objectives, a crucial step when objective evaluations are computationally expensive. However, much of the existing literature fails to account for the dynamic nature of DM preferences, which can evolve throughout the decision-making process and affect the relevance of objectives. This study addresses this limitation by simulating dynamic shifts in DM preferences within a ranking-based interactive algorithm. Additionally, we propose methods to discard outdated or conflicting preferences when such shifts occur. Building on prior research, we also introduce a mechanism to safeguard relevant objectives that may become trapped in local or global optima due to the diminished correlation with the DM-provided rankings. Our experimental results demonstrate that the proposed methods effectively manage evolving preferences and significantly enhance the quality and desirability of the solutions produced by the algorithm.
On the performance of deep learning for numerical optimization: an application to protein structure prediction
Dec 17, 2020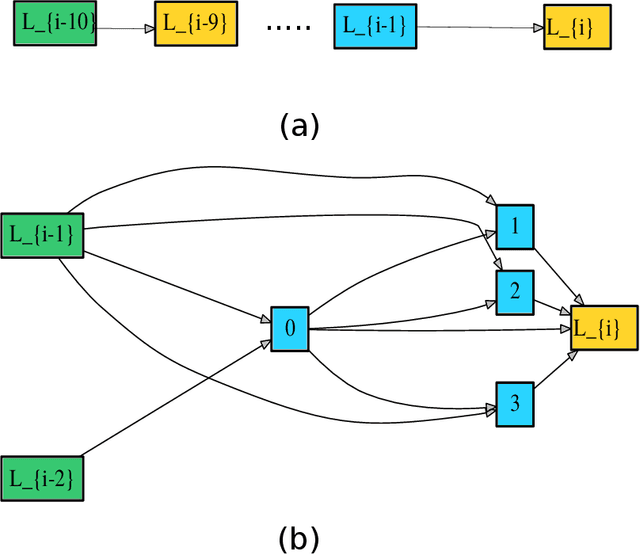
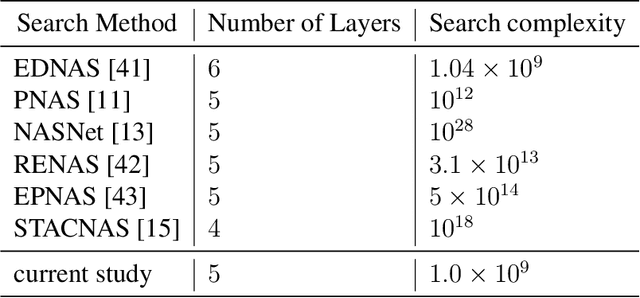
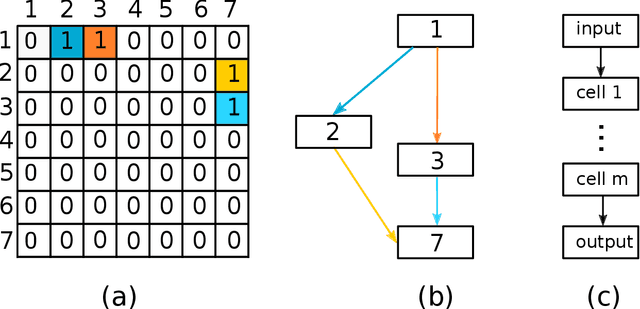
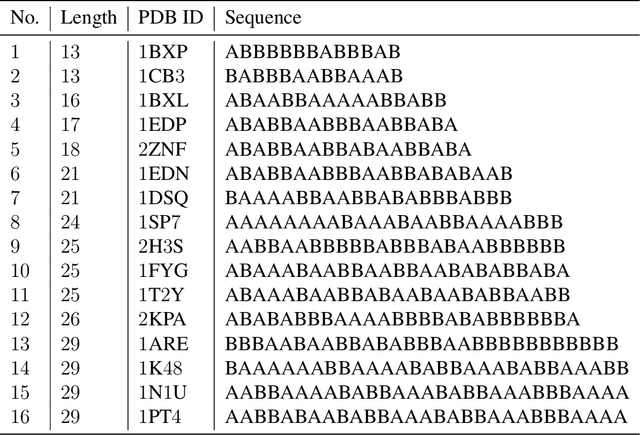
Deep neural networks have recently drawn considerable attention to build and evaluate artificial learning models for perceptual tasks. Here, we present a study on the performance of the deep learning models to deal with global optimization problems. The proposed approach adopts the idea of the neural architecture search (NAS) to generate efficient neural networks for solving the problem at hand. The space of network architectures is represented using a directed acyclic graph and the goal is to find the best architecture to optimize the objective function for a new, previously unknown task. Different from proposing very large networks with GPU computational burden and long training time, we focus on searching for lightweight implementations to find the best architecture. The performance of NAS is first analyzed through empirical experiments on CEC 2017 benchmark suite. Thereafter, it is applied to a set of protein structure prediction (PSP) problems. The experiments reveal that the generated learning models can achieve competitive results when compared to hand-designed algorithms; given enough computational budget
Bypassing or flying above the obstacles? A novel multi-objective UAV path planning problem
Apr 12, 2020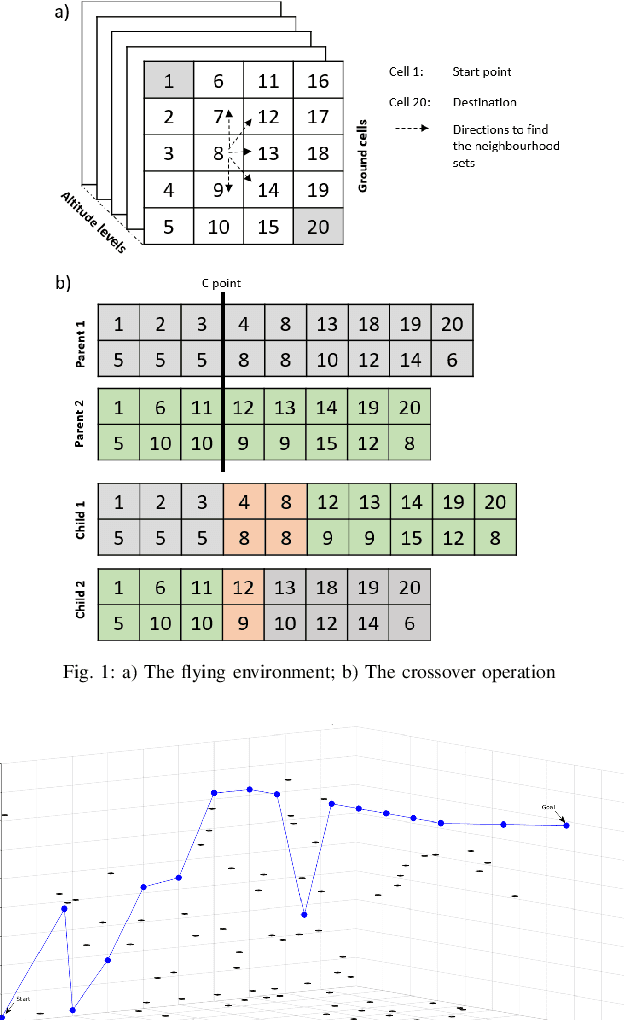
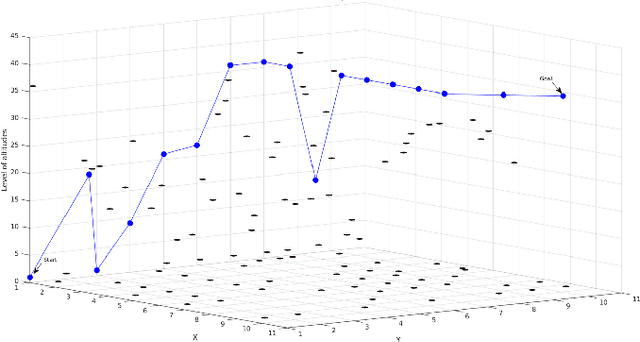
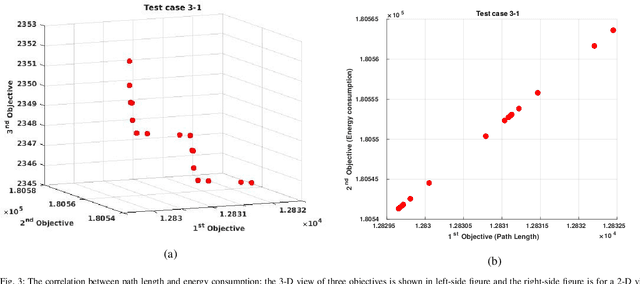
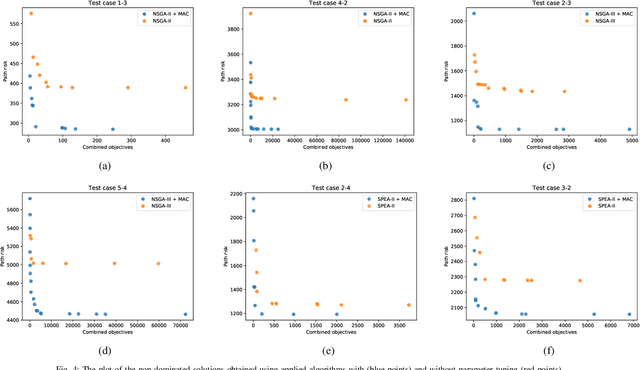
This study proposes a novel multi-objective integer programming model for a collision-free discrete drone path planning problem. Considering the possibility of bypassing obstacles or flying above them, this study aims to minimize the path length, energy consumption, and maximum path risk simultaneously. The static environment is represented as 3D grid cells. Due to the NP-hardness nature of the problem, several state-of-theart evolutionary multi-objective optimization (EMO) algorithms with customized crossover and mutation operators are applied to find a set of non-dominated solutions. The results show the effectiveness of applied algorithms in solving several generated test cases.
From feature selection to continuous optimization
Nov 01, 2019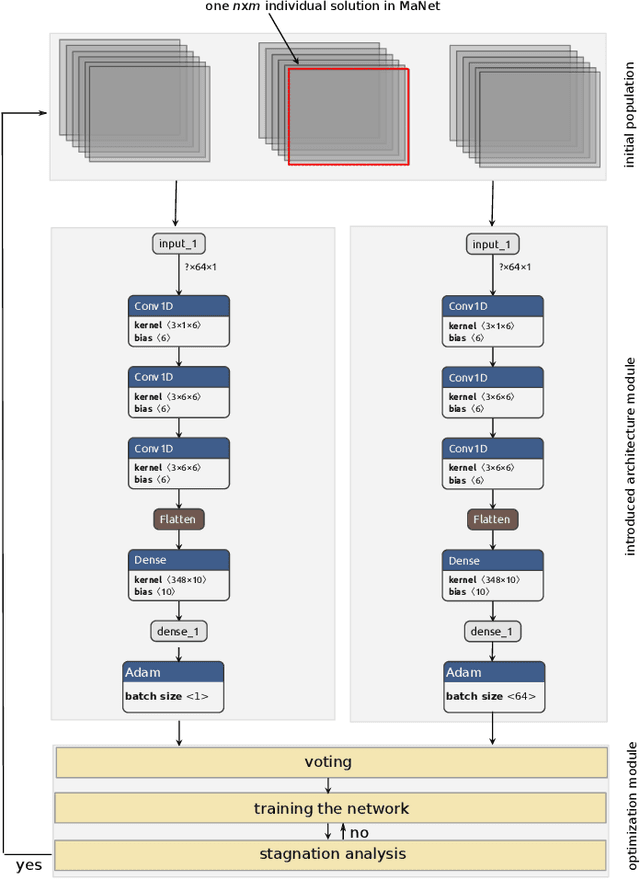

Metaheuristic algorithms (MAs) have seen unprecedented growth thanks to their successful applications in fields including engineering and health sciences. In this work, we investigate the use of a deep learning (DL) model as an alternative tool to do so. The proposed method, called MaNet, is motivated by the fact that most of the DL models often need to solve massive nasty optimization problems consisting of millions of parameters. Feature selection is the main adopted concepts in MaNet that helps the algorithm to skip irrelevant or partially relevant evolutionary information and uses those which contribute most to the overall performance. The introduced model is applied on several unimodal and multimodal continuous problems. The experiments indicate that MaNet is able to yield competitive results compared to one of the best hand-designed algorithms for the aforementioned problems, in terms of the solution accuracy and scalability.
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019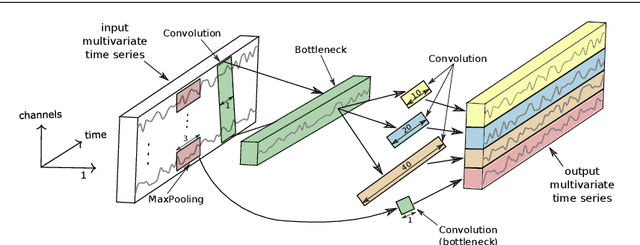
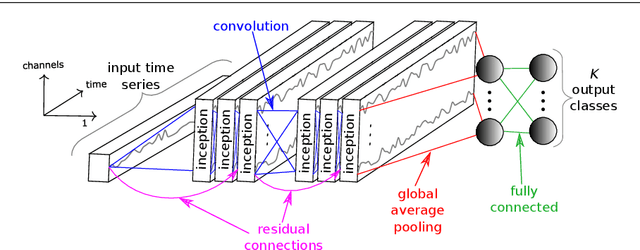
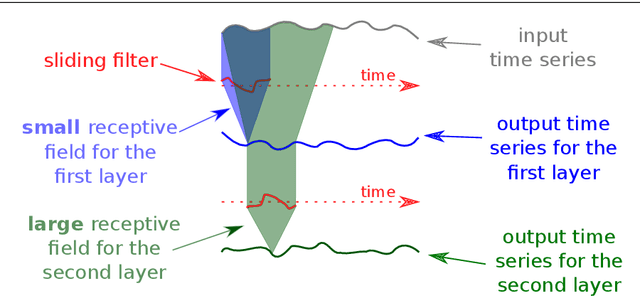
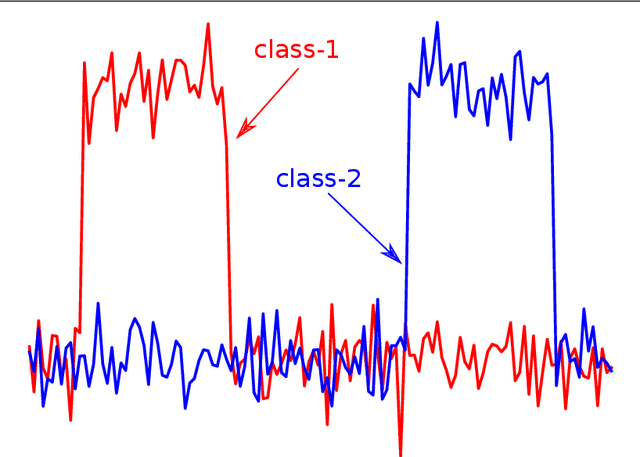
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Accurate and interpretable evaluation of surgical skills from kinematic data using fully convolutional neural networks
Aug 20, 2019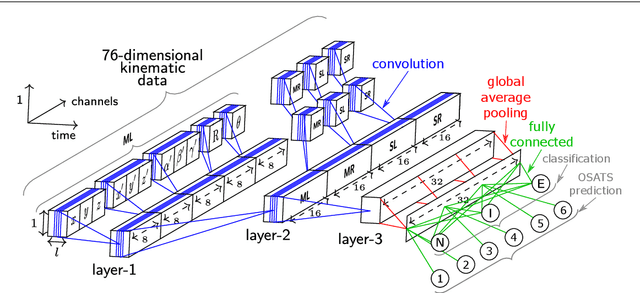
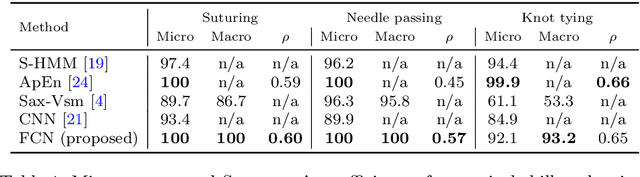
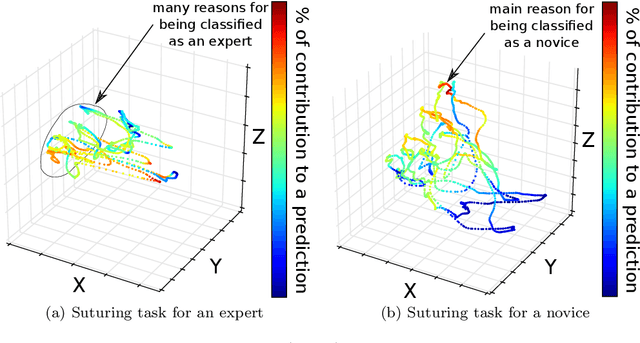

Purpose: Manual feedback from senior surgeons observing less experienced trainees is a laborious task that is very expensive, time-consuming and prone to subjectivity. With the number of surgical procedures increasing annually, there is an unprecedented need to provide an accurate, objective and automatic evaluation of trainees' surgical skills in order to improve surgical practice. Methods: In this paper, we designed a convolutional neural network (CNN) to classify surgical skills by extracting latent patterns in the trainees' motions performed during robotic surgery. The method is validated on the JIGSAWS dataset for two surgical skills evaluation tasks: classification and regression. Results: Our results show that deep neural networks constitute robust machine learning models that are able to reach new competitive state-of-the-art performance on the JIGSAWS dataset. While we leveraged from CNNs' efficiency, we were able to minimize its black-box effect using the class activation map technique. Conclusions: This characteristic allowed our method to automatically pinpoint which parts of the surgery influenced the skill evaluation the most, thus allowing us to explain a surgical skill classification and provide surgeons with a novel personalized feedback technique. We believe this type of interpretable machine learning model could integrate within "Operation Room 2.0" and support novice surgeons in improving their skills to eventually become experts.
Automatic alignment of surgical videos using kinematic data
Apr 26, 2019



Over the past one hundred years, the classic teaching methodology of "see one, do one, teach one" has governed the surgical education systems worldwide. With the advent of Operation Room 2.0, recording video, kinematic and many other types of data during the surgery became an easy task, thus allowing artificial intelligence systems to be deployed and used in surgical and medical practice. Recently, surgical videos has been shown to provide a structure for peer coaching enabling novice trainees to learn from experienced surgeons by replaying those videos. However, the high inter-operator variability in surgical gesture duration and execution renders learning from comparing novice to expert surgical videos a very difficult task. In this paper, we propose a novel technique to align multiple videos based on the alignment of their corresponding kinematic multivariate time series data. By leveraging the Dynamic Time Warping measure, our algorithm synchronizes a set of videos in order to show the same gesture being performed at different speed. We believe that the proposed approach is a valuable addition to the existing learning tools for surgery.
Automatic hyperparameter selection in Autodock
Dec 02, 2018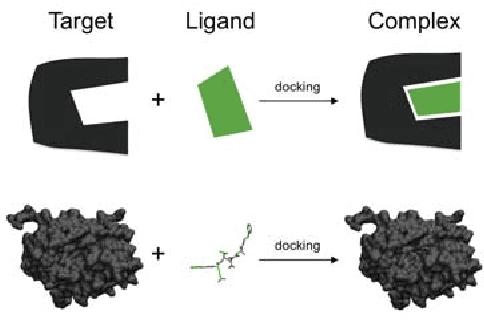
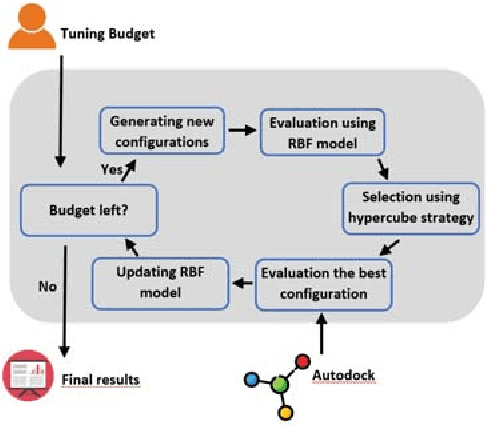

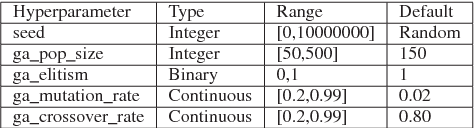
Autodock is a widely used molecular modeling tool which predicts how small molecules bind to a receptor of known 3D structure. The current version of AutoDock uses meta-heuristic algorithms in combination with local search methods for doing the conformation search. Appropriate settings of hyperparameters in these algorithms are important, particularly for novice users who often find it hard to identify the best configuration. In this work, we design a surrogate based multi-objective algorithm to help such users by automatically tuning hyperparameter settings. The proposed method iteratively uses a radial basis function model and non-dominated sorting to evaluate the sampled configurations during the search phase. Our experimental results using Autodock show that the introduced component is practical and effective.
Transfer learning for time series classification
Nov 05, 2018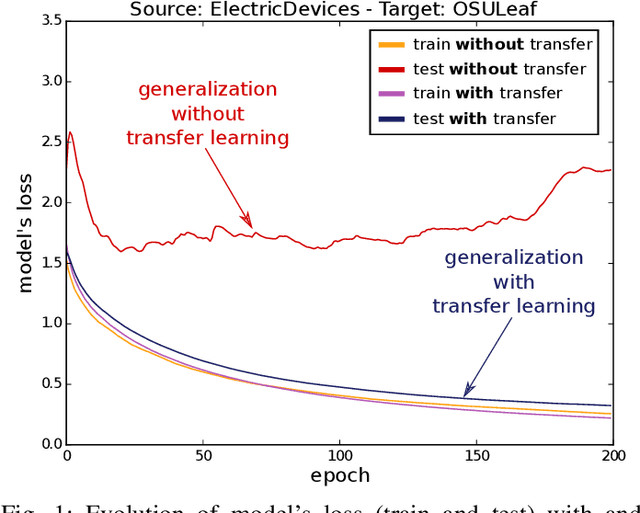

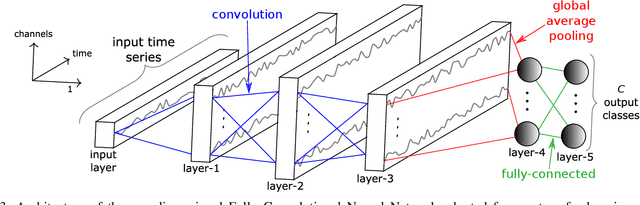
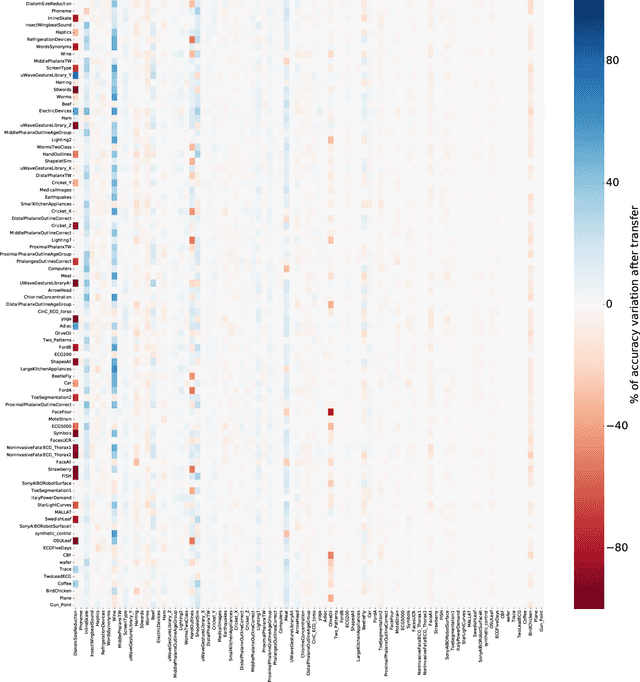
Transfer learning for deep neural networks is the process of first training a base network on a source dataset, and then transferring the learned features (the network's weights) to a second network to be trained on a target dataset. This idea has been shown to improve deep neural network's generalization capabilities in many computer vision tasks such as image recognition and object localization. Apart from these applications, deep Convolutional Neural Networks (CNNs) have also recently gained popularity in the Time Series Classification (TSC) community. However, unlike for image recognition problems, transfer learning techniques have not yet been investigated thoroughly for the TSC task. This is surprising as the accuracy of deep learning models for TSC could potentially be improved if the model is fine-tuned from a pre-trained neural network instead of training it from scratch. In this paper, we fill this gap by investigating how to transfer deep CNNs for the TSC task. To evaluate the potential of transfer learning, we performed extensive experiments using the UCR archive which is the largest publicly available TSC benchmark containing 85 datasets. For each dataset in the archive, we pre-trained a model and then fine-tuned it on the other datasets resulting in 7140 different deep neural networks. These experiments revealed that transfer learning can improve or degrade the model's predictions depending on the dataset used for transfer. Therefore, in an effort to predict the best source dataset for a given target dataset, we propose a new method relying on Dynamic Time Warping to measure inter-datasets similarities. We describe how our method can guide the transfer to choose the best source dataset leading to an improvement in accuracy on 71 out of 85 datasets.
Deep learning for time series classification: a review
Sep 12, 2018


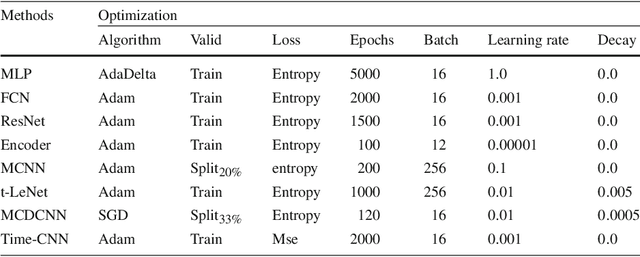
Time Series Classification (TSC) is an important and challenging problem in data mining. With the increase of time series data availability, hundreds of TSC algorithms have been proposed. Among these methods, only a few have considered Deep Neural Networks (DNNs) to perform this task. This is surprising as deep learning has seen very successful applications in the last years. DNNs have indeed revolutionized the field of computer vision especially with the advent of novel deeper architectures such as Residual and Convolutional Neural Networks. Apart from images, sequential data such as text and audio can also be processed with DNNs to reach state of the art performance for document classification and speech recognition. In this article, we study the current state of the art performance of deep learning algorithms for TSC by presenting an empirical study of the most recent DNN architectures for TSC. We give an overview of the most successful deep learning applications in various time series domains under a unified taxonomy of DNNs for TSC. We also provide an open source deep learning framework to the TSC community where we implemented each of the compared approaches and evaluated them on a univariate TSC benchmark (the UCR archive) and 12 multivariate time series datasets. By training 8,730 deep learning models on 97 time series datasets, we propose the most exhaustive study of DNNs for TSC to date.