 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Spatiotemporal Features in LSTM for Spatially Informed COVID-19 Hospitalization Forecasting
Jun 06, 2025The COVID-19 pandemic's severe impact highlighted the need for accurate, timely hospitalization forecasting to support effective healthcare planning. However, most forecasting models struggled, especially during variant surges, when they were needed most. This study introduces a novel Long Short-Term Memory (LSTM) framework for forecasting daily state-level incident hospitalizations in the United States. We present a spatiotemporal feature, Social Proximity to Hospitalizations (SPH), derived from Facebook's Social Connectedness Index to improve forecasts. SPH serves as a proxy for interstate population interaction, capturing transmission dynamics across space and time. Our parallel LSTM architecture captures both short- and long-term temporal dependencies, and our multi-horizon ensembling strategy balances consistency and forecasting error. Evaluation against COVID-19 Forecast Hub ensemble models during the Delta and Omicron surges reveals superiority of our model. On average, our model surpasses the ensemble by 27, 42, 54, and 69 hospitalizations per state on the $7^{th}$, $14^{th}$, $21^{st}$, and $28^{th}$ forecast days, respectively, during the Omicron surge. Data-ablation experiments confirm SPH's predictive power, highlighting its effectiveness in enhancing forecasting models. This research not only advances hospitalization forecasting but also underscores the significance of spatiotemporal features, such as SPH, in refining predictive performance in modeling the complex dynamics of infectious disease spread.
Partial Label Learning with Focal Loss for Sea Ice Classification Based on Ice Charts
Jun 05, 2024



Sea ice, crucial to the Arctic and Earth's climate, requires consistent monitoring and high-resolution mapping. Manual sea ice mapping, however, is time-consuming and subjective, prompting the need for automated deep learning-based classification approaches. However, training these algorithms is challenging because expert-generated ice charts, commonly used as training data, do not map single ice types but instead map polygons with multiple ice types. Moreover, the distribution of various ice types in these charts is frequently imbalanced, resulting in a performance bias towards the dominant class. In this paper, we present a novel GeoAI approach to training sea ice classification by formalizing it as a partial label learning task with explicit confidence scores to address multiple labels and class imbalance. We treat the polygon-level labels as candidate partial labels, assign the corresponding ice concentrations as confidence scores to each candidate label, and integrate them with focal loss to train a Convolutional Neural Network (CNN). Our proposed approach leads to enhanced performance for sea ice classification in Sentinel-1 dual-polarized SAR images, improving classification accuracy (from 87% to 92%) and weighted average F-1 score (from 90% to 93%) compared to the conventional training approach of using one-hot encoded labels and Categorical Cross-Entropy loss. It also improves the F-1 score in 4 out of the 6 sea ice classes.
A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the United States
Sep 27, 2021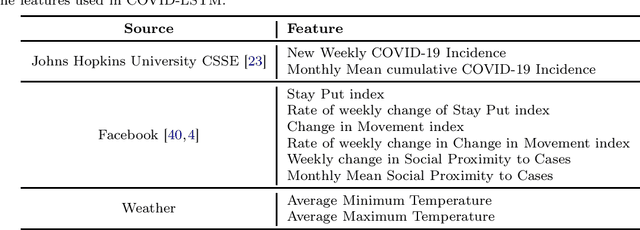


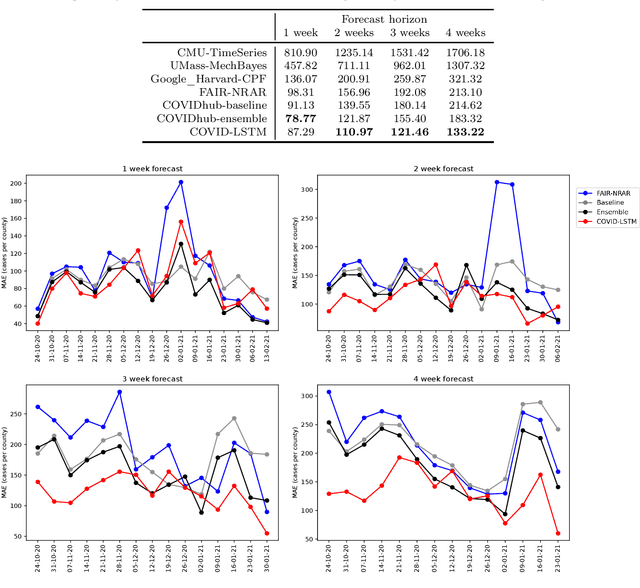
With COVID-19 affecting every country globally and changing everyday life, the ability to forecast the spread of the disease is more important than any previous epidemic. The conventional methods of disease-spread modeling, compartmental models, are based on the assumption of spatiotemporal homogeneity of the spread of the virus, which may cause forecasting to underperform, especially at high spatial resolutions. In this paper we approach the forecasting task with an alternative technique - spatiotemporal machine learning. We present COVID-LSTM, a data-driven model based on a Long Short-term Memory deep learning architecture for forecasting COVID-19 incidence at the county-level in the US. We use the weekly number of new positive cases as temporal input, and hand-engineered spatial features from Facebook movement and connectedness datasets to capture the spread of the disease in time and space. COVID-LSTM outperforms the COVID-19 Forecast Hub's Ensemble model (COVIDhub-ensemble) on our 17-week evaluation period, making it the first model to be more accurate than the COVIDhub-ensemble over one or more forecast periods. Over the 4-week forecast horizon, our model is on average 50 cases per county more accurate than the COVIDhub-ensemble. We highlight that the underutilization of data-driven forecasting of disease spread prior to COVID-19 is likely due to the lack of sufficient data available for previous diseases, in addition to the recent advances in machine learning methods for spatiotemporal forecasting. We discuss the impediments to the wider uptake of data-driven forecasting, and whether it is likely that more deep learning-based models will be used in the future.
A Bayesian-inspired, deep learning, semi-supervised domain adaptation technique for land cover mapping
May 25, 2020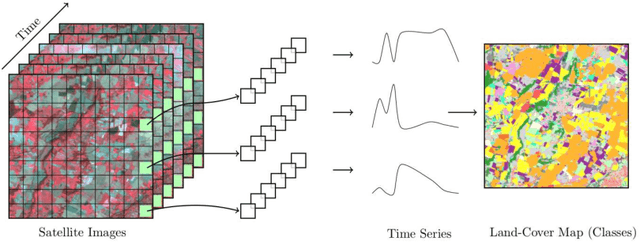
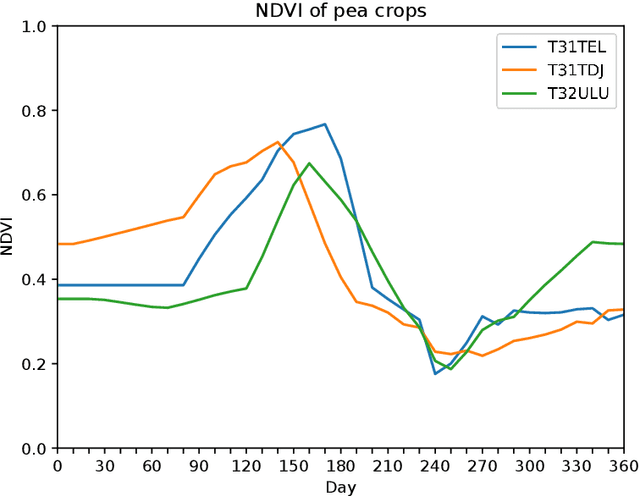
Land cover maps are a vital input variable to many types of environmental research and management. While they can be produced automatically by machine learning techniques, these techniques require substantial training data to achieve high levels of accuracy, which are not always available. One technique researchers use when labelled training data are scarce is domain adaptation (DA) -- where data from an alternate region, known as the source domain, are used to train a classifier and this model is adapted to map the study region, or target domain. The scenario we address in this paper is known as semi-supervised DA, where some labelled samples are available in the target domain. In this paper we present Sourcerer, a Bayesian-inspired, deep learning-based, semi-supervised DA technique for producing land cover maps from SITS data. The technique takes a convolutional neural network trained on a source domain and then trains further on the available target domain with a novel regularizer applied to the model weights. The regularizer adjusts the degree to which the model is modified to fit the target data, limiting the degree of change when the target data are few in number and increasing it as target data quantity increases. Our experiments on Sentinel-2 time series images compare Sourcerer with two state-of-the-art semi-supervised domain adaptation techniques and four baseline models. We show that on two different source-target domain pairings Sourcerer outperforms all other methods for any quantity of labelled target data available. In fact, the results on the more difficult target domain show that the starting accuracy of Sourcerer (when no labelled target data are available), 74.2%, is greater than the next-best state-of-the-art method trained on 20,000 labelled target instances.
InceptionTime: Finding AlexNet for Time Series Classification
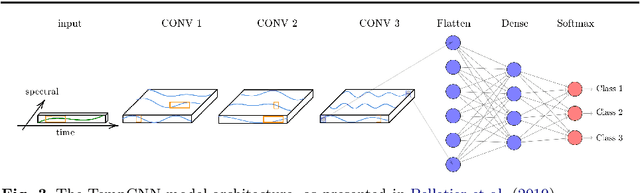
Sep 13, 2019
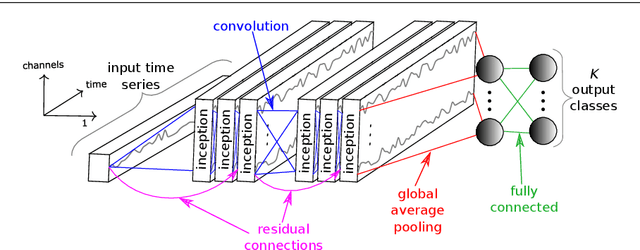
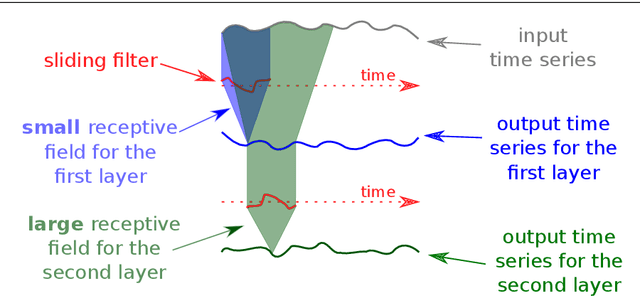
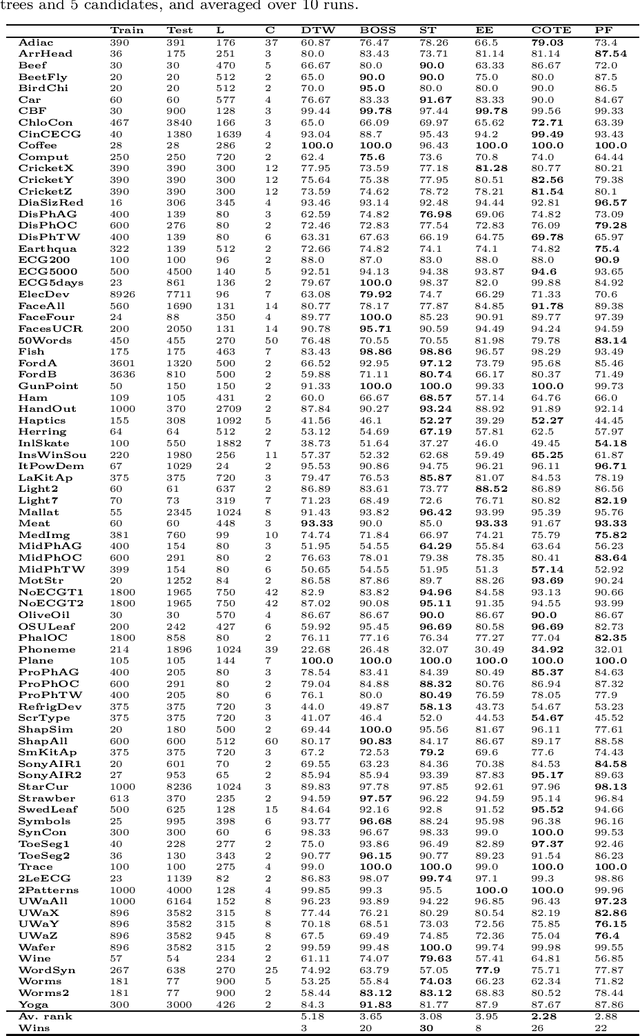
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018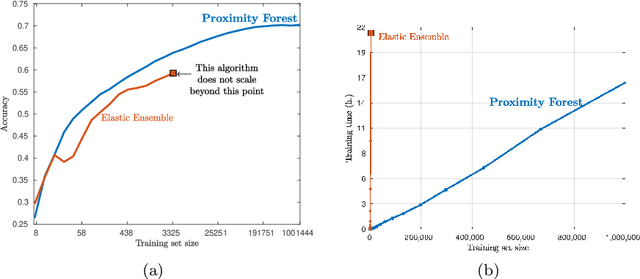
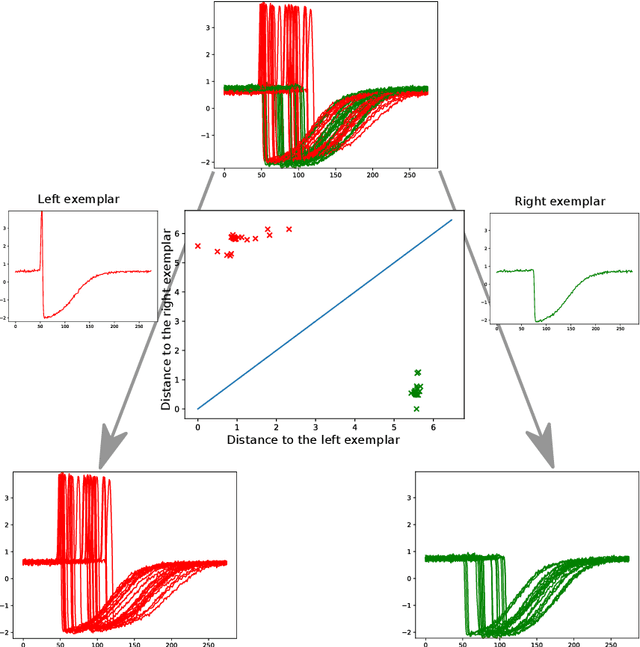
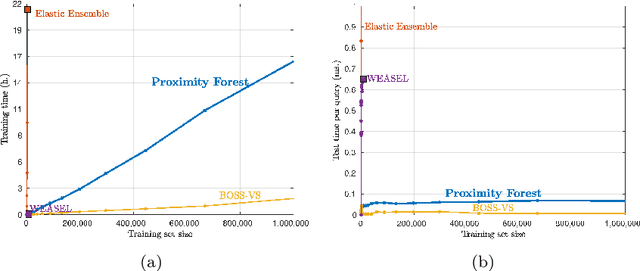
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.