 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Similarity Measures for Multivariate Time Series Classification
Feb 20, 2021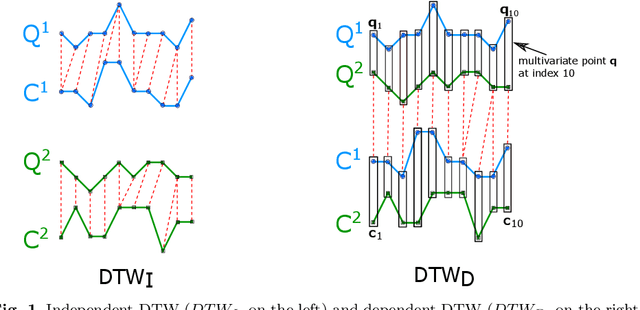
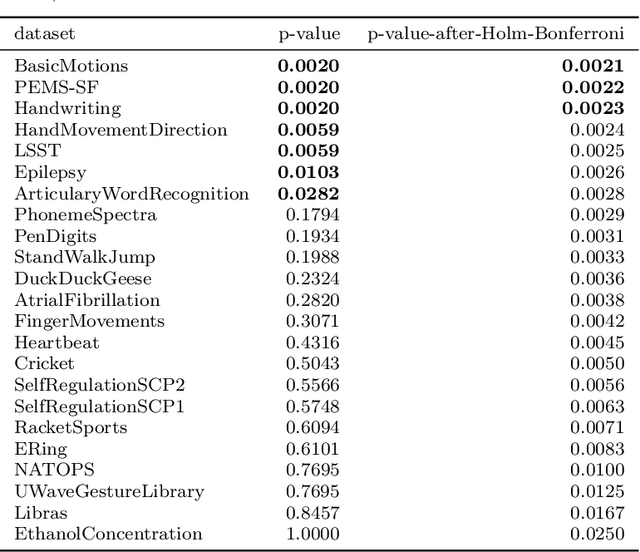
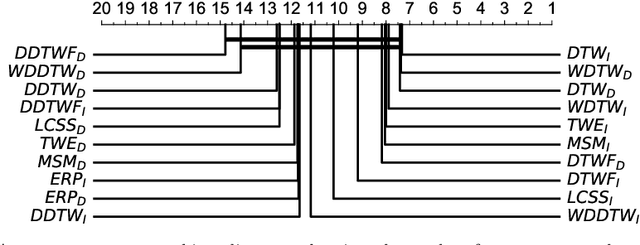
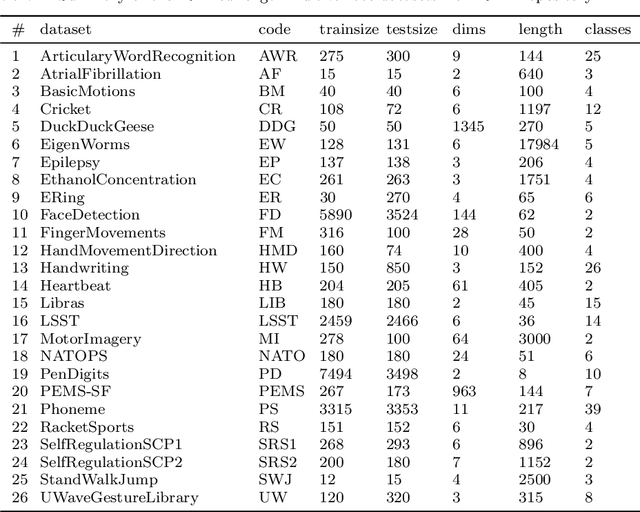
Elastic similarity measures are a class of similarity measures specifically designed to work with time series data. When scoring the similarity between two time series, they allow points that do not correspond in timestamps to be aligned. This can compensate for misalignments in the time axis of time series data, and for similar processes that proceed at variable and differing paces. Elastic similarity measures are widely used in machine learning tasks such as classification, clustering and outlier detection when using time series data. There is a multitude of research on various univariate elastic similarity measures. However, except for multivariate versions of the well known Dynamic Time Warping (DTW) there is a lack of work to generalise other similarity measures for multivariate cases. This paper adapts two existing strategies used in multivariate DTW, namely, Independent and Dependent DTW, to several commonly used elastic similarity measures. Using 23 datasets from the University of East Anglia (UEA) multivariate archive, for nearest neighbour classification, we demonstrate that each measure outperforms all others on at least one dataset and that there are datasets for which either the dependent versions of all measures are more accurate than their independent counterparts or vice versa. This latter finding suggests that these differences arise from a fundamental property of the data. We also show that an ensemble of such nearest neighbour classifiers is highly competitive with other state-of-the-art multivariate time series classifiers.
TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification
Jun 25, 2019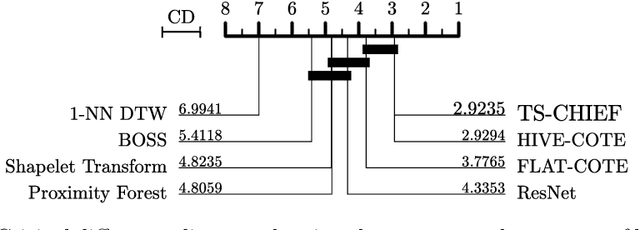
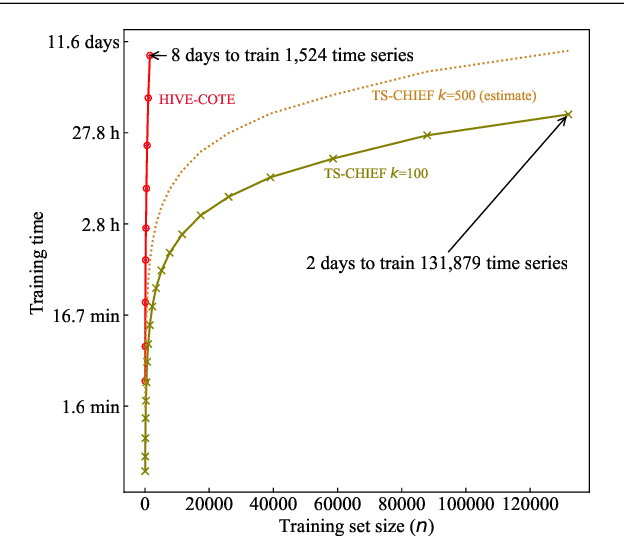
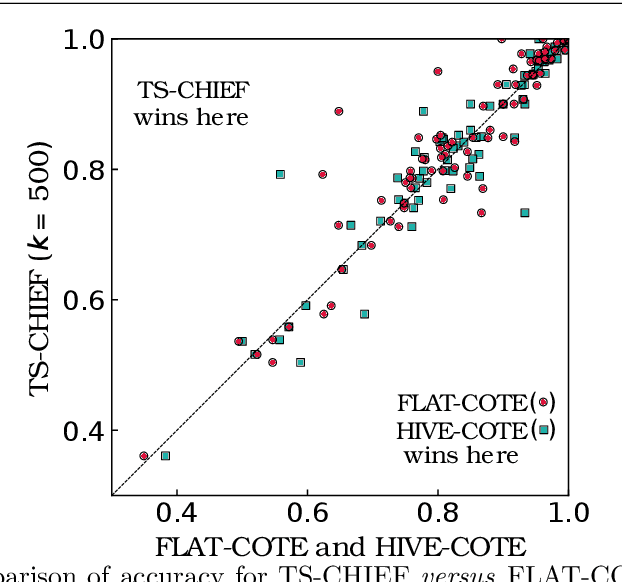
Time Series Classification (TSC) has seen enormous progress over the last two decades. HIVE-COTE (Hierarchical Vote Collective of Transformation-based Ensembles) is the current state of the art in terms of classification accuracy. HIVE-COTE recognizes that time series are a specific data type for which the traditional attribute-value representation, used predominantly in machine learning, fails to provide a relevant representation. HIVE-COTE combines multiple types of classifiers: each extracting information about a specific aspect of a time series, be it in the time domain, frequency domain or summarization of intervals within the series. However, HIVE-COTE (and its predecessor, FLAT-COTE) is often infeasible to run on even modest amounts of data. For instance, training HIVE-COTE on a dataset with only 1,500 time series can require 8 days of CPU time. It has polynomial runtime w.r.t training set size, so this problem compounds as data quantity increases. We propose a novel TSC algorithm, TS-CHIEF, which is highly competitive to HIVE-COTE in accuracy, but requires only a fraction of the runtime. TS-CHIEF constructs an ensemble classifier that integrates the most effective embeddings of time series that research has developed in the last decade. It uses tree-structured classifiers to do so efficiently. We assess TS-CHIEF on 85 datasets of the UCR archive, where it achieves state-of-the-art accuracy with scalability and efficiency. We demonstrate that TS-CHIEF can be trained on 130k time series in 2 days, a data quantity that is beyond the reach of any TSC algorithm with comparable accuracy.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018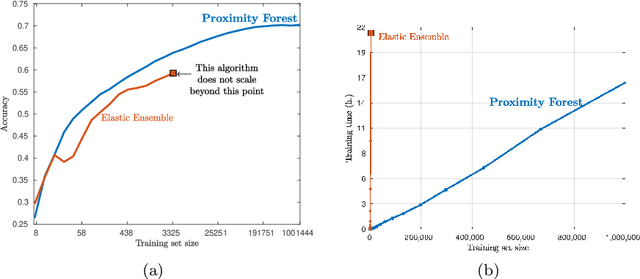
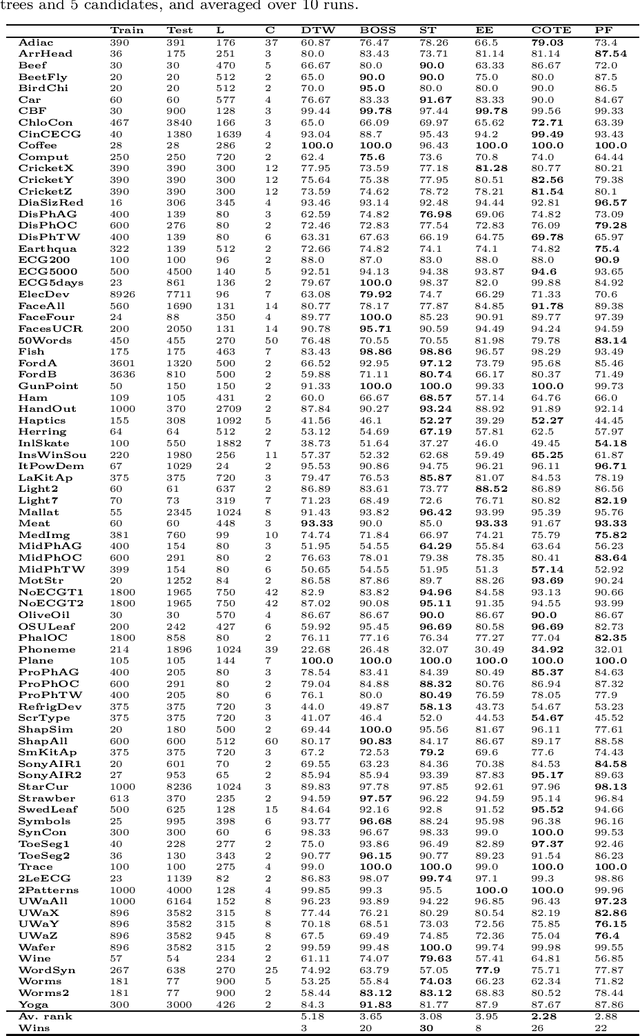
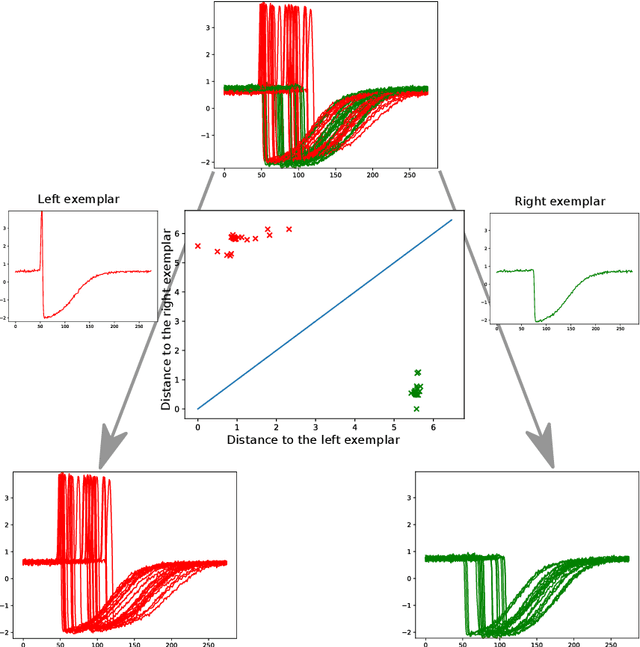
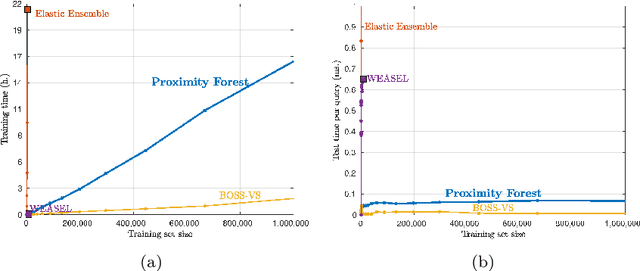
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.