 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight lower bounds for Dynamic Time Warping
Mar 02, 2021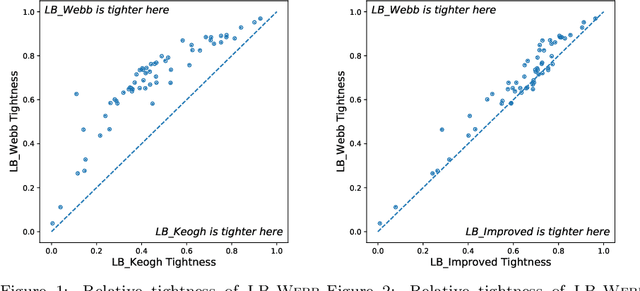
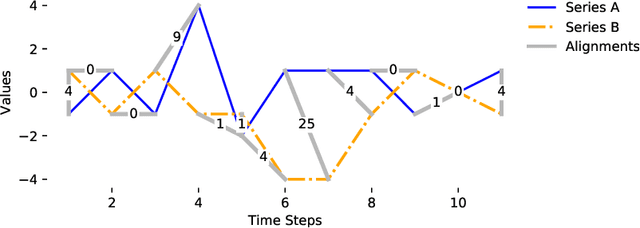
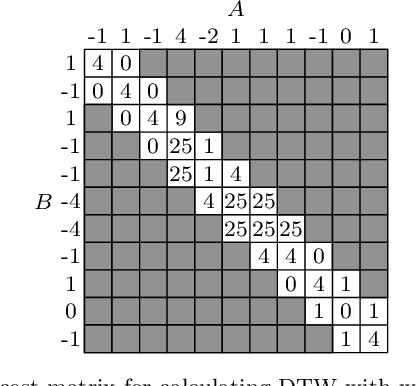
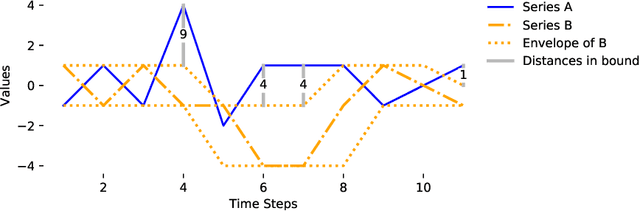
Dynamic Time Warping (DTW) is a popular similarity measure for aligning and comparing time series. Due to DTW's high computation time, lower bounds are often employed to screen poor matches. Many alternative lower bounds have been proposed, providing a range of different trade-offs between tightness and computational efficiency. LB Keogh provides a useful trade-off in many applications. Two recent lower bounds, LB Improved and LB Enhanced, are substantially tighter than LB Keogh. All three have the same worst case computational complexity - linear with respect to series length and constant with respect to window size. We present four new DTW lower bounds in the same complexity class. LB Petitjean is substantially tighter than LB Improved, with only modest additional computational overhead. LB Webb is more efficient than LB Improved, while often providing a tighter bound. LB Webb is always tighter than LB Keogh. The parameter free LB Webb is usually tighter than LB Enhanced. A parameterized variant, LB Webb Enhanced, is always tighter than LB Enhanced. A further variant, LB Webb*, is useful for some constrained distance functions. In extensive experiments, LB Webb proves to be very effective for nearest neighbor search.
* 26 pages, 23 figures, expanded version of a paper accepted for publication in Pattern Recognition. This revision fixed minor typos in the two algorithms
Elastic Similarity Measures for Multivariate Time Series Classification
Feb 20, 2021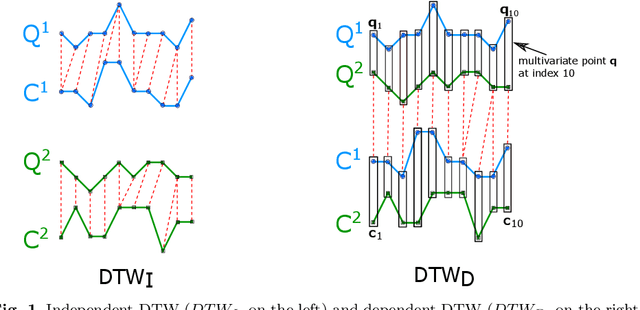
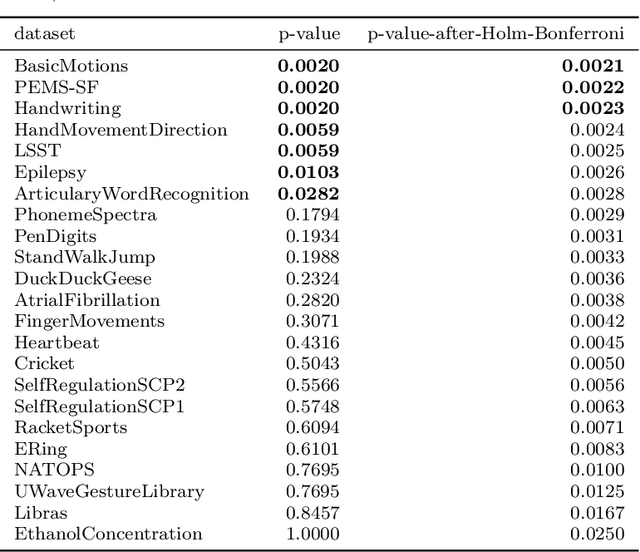
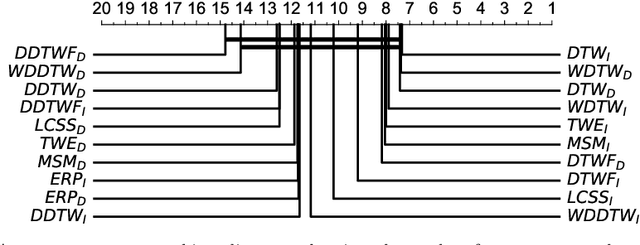
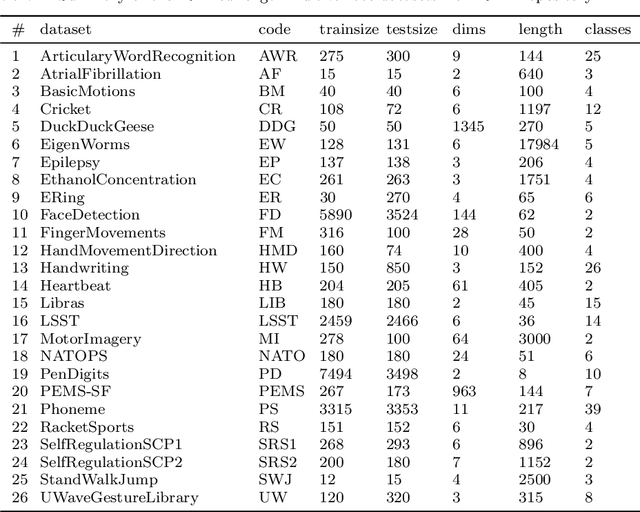
Elastic similarity measures are a class of similarity measures specifically designed to work with time series data. When scoring the similarity between two time series, they allow points that do not correspond in timestamps to be aligned. This can compensate for misalignments in the time axis of time series data, and for similar processes that proceed at variable and differing paces. Elastic similarity measures are widely used in machine learning tasks such as classification, clustering and outlier detection when using time series data. There is a multitude of research on various univariate elastic similarity measures. However, except for multivariate versions of the well known Dynamic Time Warping (DTW) there is a lack of work to generalise other similarity measures for multivariate cases. This paper adapts two existing strategies used in multivariate DTW, namely, Independent and Dependent DTW, to several commonly used elastic similarity measures. Using 23 datasets from the University of East Anglia (UEA) multivariate archive, for nearest neighbour classification, we demonstrate that each measure outperforms all others on at least one dataset and that there are datasets for which either the dependent versions of all measures are more accurate than their independent counterparts or vice versa. This latter finding suggests that these differences arise from a fundamental property of the data. We also show that an ensemble of such nearest neighbour classifiers is highly competitive with other state-of-the-art multivariate time series classifiers.
Discriminative, Generative and Self-Supervised Approaches for Target-Agnostic Learning
Nov 12, 2020
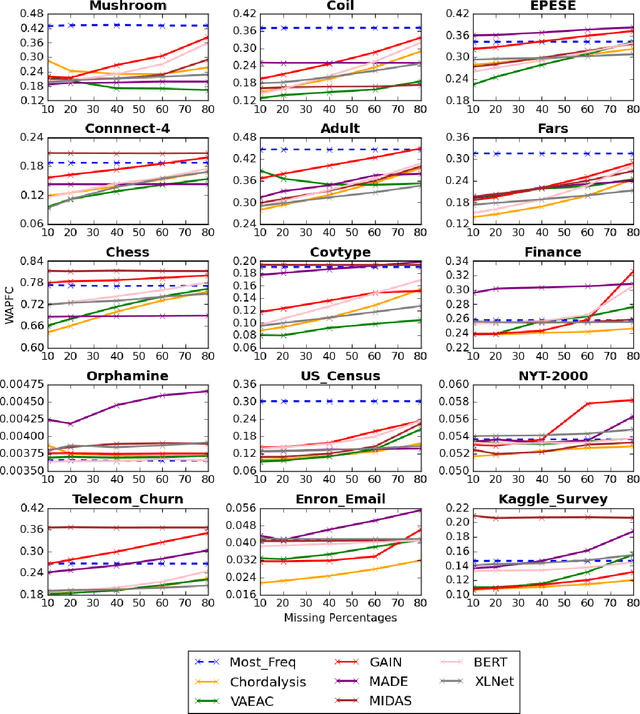
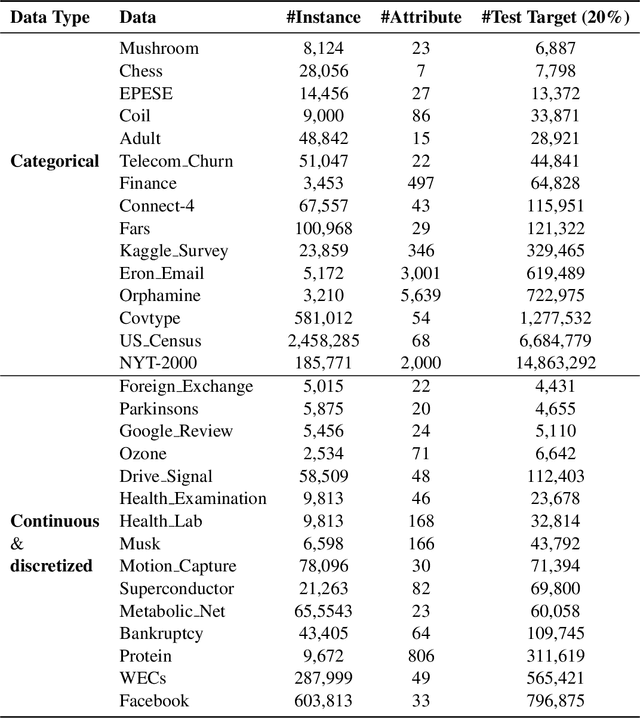
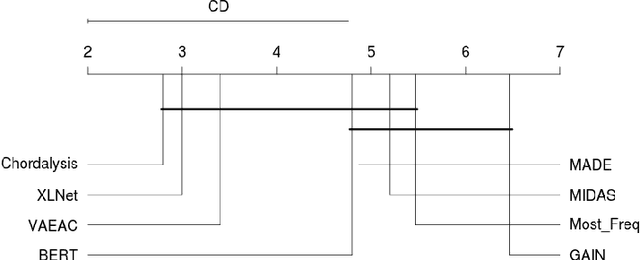
Supervised learning, characterized by both discriminative and generative learning, seeks to predict the values of single (or sometimes multiple) predefined target attributes based on a predefined set of predictor attributes. For applications where the information available and predictions to be made may vary from instance to instance, we propose the task of target-agnostic learning where arbitrary disjoint sets of attributes can be used for each of predictors and targets for each to-be-predicted instance. For this task, we survey a wide range of techniques available for handling missing values, self-supervised training and pseudo-likelihood training, and adapt them to a suite of algorithms that are suitable for the task. We conduct extensive experiments on this suite of algorithms on a large collection of categorical, continuous and discretized datasets, and report their performance in terms of both classification and regression errors. We also report the training and prediction time of these algorithms when handling large-scale datasets. Both generative and self-supervised learning models are shown to perform well at the task, although their characteristics towards the different types of data are quite different. Nevertheless, our derived theorem for the pseudo-likelihood theory also shows that they are related for inferring a joint distribution model based on the pseudo-likelihood training.
Seasonal Averaged One-Dependence Estimators: A Novel Algorithm to Address Seasonal Concept Drift in High-Dimensional Stream Classification
Jun 27, 2020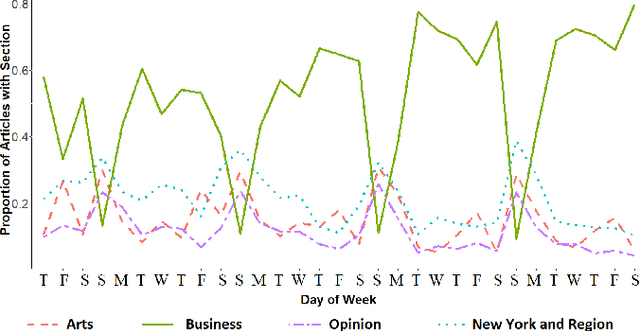
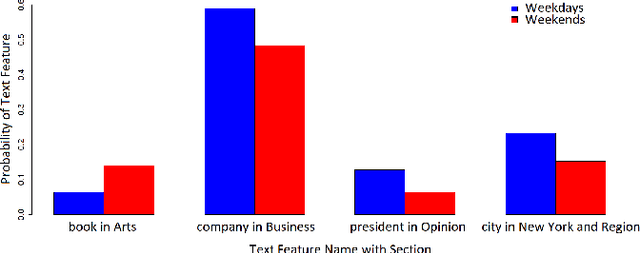
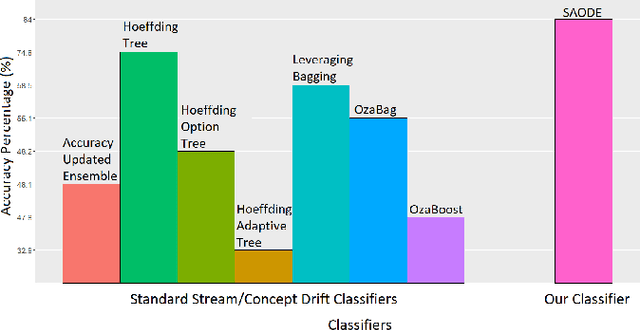
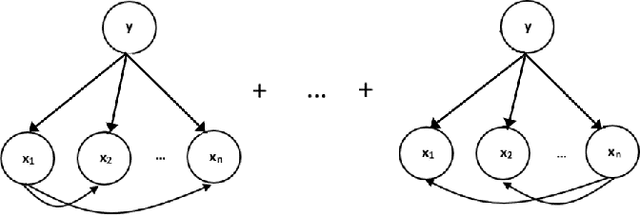
Stream classification methods classify a continuous stream of data as new labelled samples arrive. They often also have to deal with concept drift. This paper focuses on seasonal drift in stream classification, which can be found in many real-world application data sources. Traditional approaches of stream classification consider seasonal drift by including seasonal dummy/indicator variables or building separate models for each season. But these approaches have strong limitations in high-dimensional classification problems, or with complex seasonal patterns. This paper explores how to best handle seasonal drift in the specific context of news article categorization (or classification/tagging), where seasonal drift is overwhelmingly the main type of drift present in the data, and for which the data are high-dimensional. We introduce a novel classifier named Seasonal Averaged One-Dependence Estimators (SAODE), which extends the AODE classifier to handle seasonal drift by including time as a super parent. We assess our SAODE model using two large real-world text mining related datasets each comprising approximately a million records, against nine state-of-the-art stream and concept drift classification models, with and without seasonal indicators and with separate models built for each season. Across five different evaluation techniques, we show that our model consistently outperforms other methods by a large margin where the results are statistically significant.
Time Series Regression
Jun 23, 2020
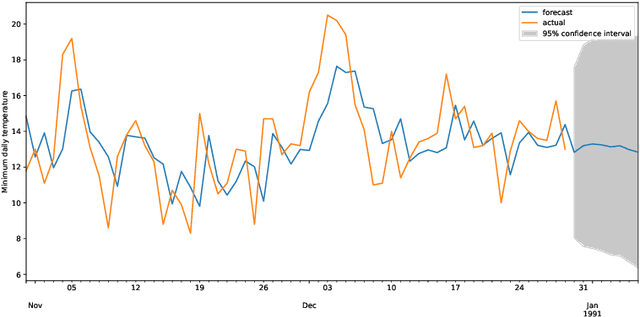
This paper introduces Time Series Regression (TSR): a little-studied task of which the aim is to learn the relationship between a time series and a continuous target variable. In contrast to time series classification (TSC), which predicts a categorical class label, TSR predicts a numerical value. This task generalizes forecasting, relaxing the requirement that the value predicted be a future value of the input series or primarily depend on more recent values. In this paper, we motivate and introduce this task, and benchmark possible solutions to tackling it on a novel archive of 19 TSR datasets which we have assembled. Our results show that the state-of-the-art TSC model Rocket, when adapted for regression, performs the best overall compared to other TSC models and state-of-the-art machine learning (ML) models such as XGBoost, Random Forest and Support Vector Regression.More importantly, we show that much research is needed in this field to improve the accuracy of ML models.
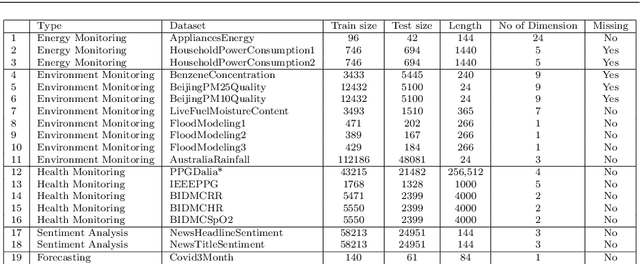
Monash University, UEA, UCR Time Series Regression Archive
Jun 22, 2020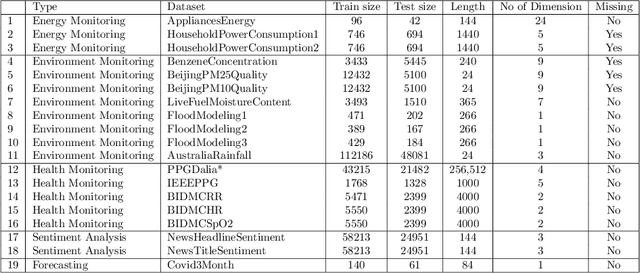
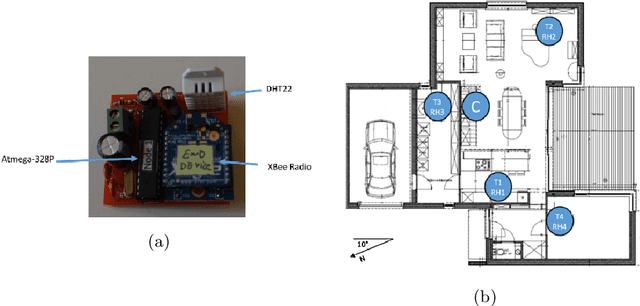
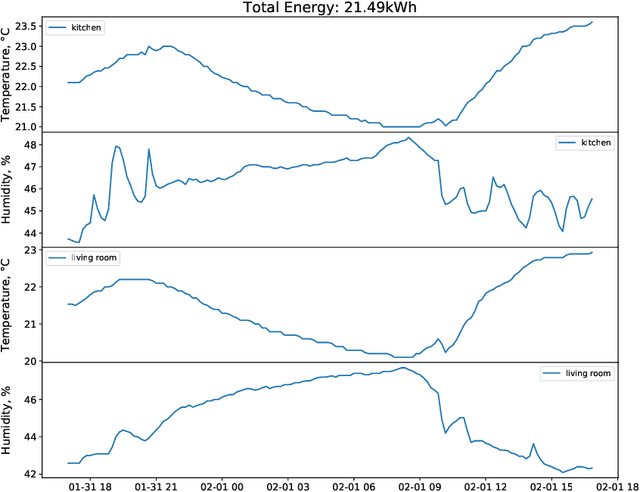
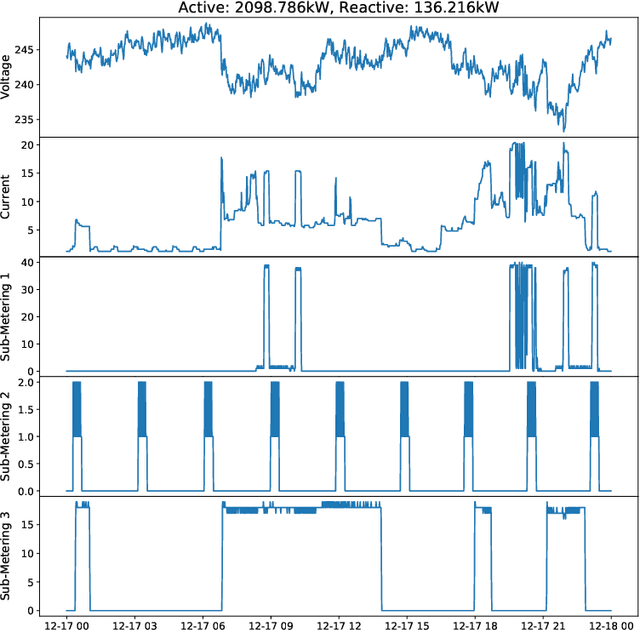
Time series research has gathered lots of interests in the last decade, especially for Time Series Classification (TSC) and Time Series Forecasting (TSF). Research in TSC has greatly benefited from the University of California Riverside and University of East Anglia (UCR/UEA) Time Series Archives. On the other hand, the advancement in Time Series Forecasting relies on time series forecasting competitions such as the Makridakis competitions, NN3 and NN5 Neural Network competitions, and a few Kaggle competitions. Each year, thousands of papers proposing new algorithms for TSC and TSF have utilized these benchmarking archives. These algorithms are designed for these specific problems, but may not be useful for tasks such as predicting the heart rate of a person using photoplethysmogram (PPG) and accelerometer data. We refer to this problem as Time Series Regression (TSR), where we are interested in a more general methodology of predicting a single continuous value, from univariate or multivariate time series. This prediction can be from the same time series or not directly related to the predictor time series and does not necessarily need to be a future value or depend heavily on recent values. To the best of our knowledge, research into TSR has received much less attention in the time series research community and there are no models developed for general time series regression problems. Most models are developed for a specific problem. Therefore, we aim to motivate and support the research into TSR by introducing the first TSR benchmarking archive. This archive contains 19 datasets from different domains, with varying number of dimensions, unequal length dimensions, and missing values. In this paper, we introduce the datasets in this archive and did an initial benchmark on existing models.
Time series classification for varying length series
Oct 10, 2019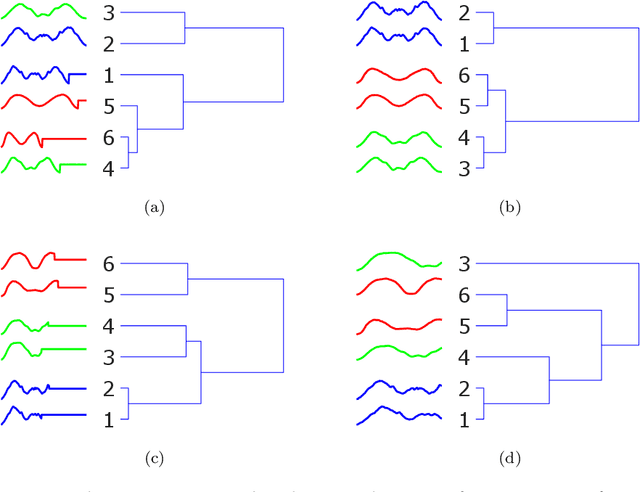
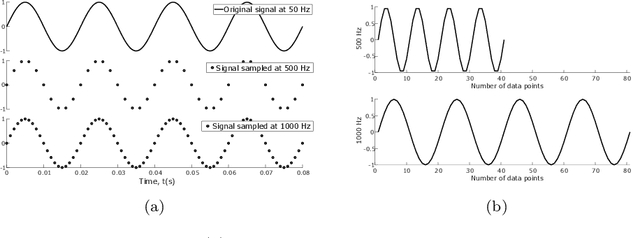
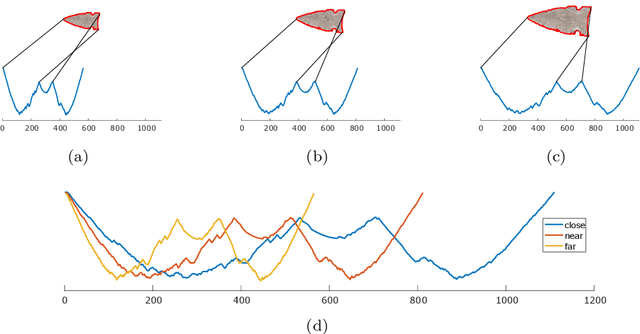
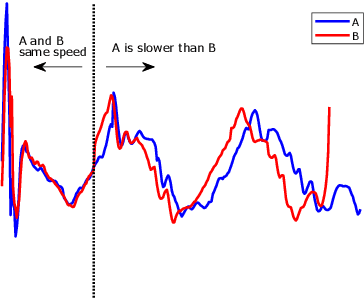
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.
TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification
Jun 25, 2019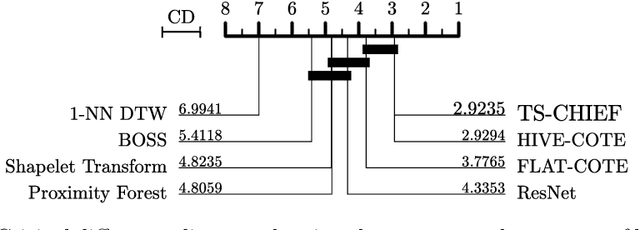
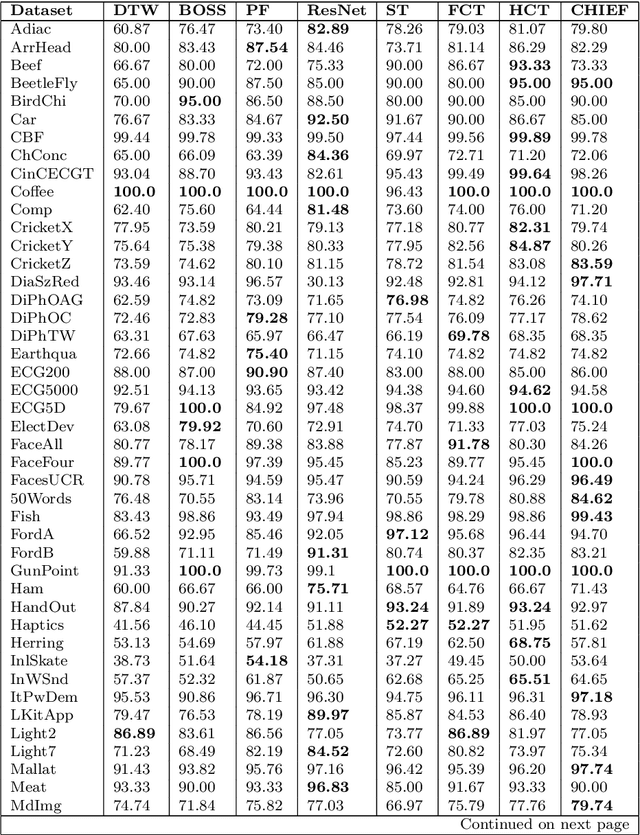
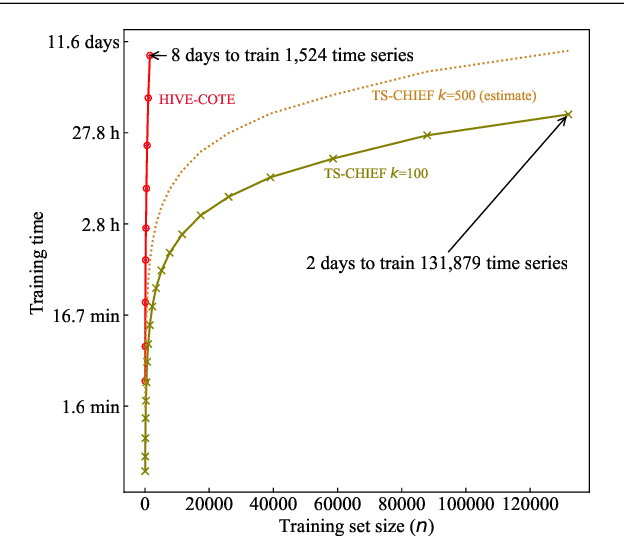
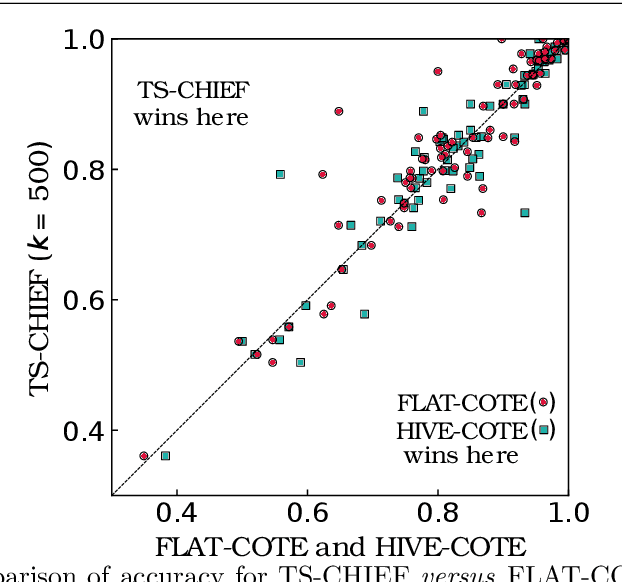
Time Series Classification (TSC) has seen enormous progress over the last two decades. HIVE-COTE (Hierarchical Vote Collective of Transformation-based Ensembles) is the current state of the art in terms of classification accuracy. HIVE-COTE recognizes that time series are a specific data type for which the traditional attribute-value representation, used predominantly in machine learning, fails to provide a relevant representation. HIVE-COTE combines multiple types of classifiers: each extracting information about a specific aspect of a time series, be it in the time domain, frequency domain or summarization of intervals within the series. However, HIVE-COTE (and its predecessor, FLAT-COTE) is often infeasible to run on even modest amounts of data. For instance, training HIVE-COTE on a dataset with only 1,500 time series can require 8 days of CPU time. It has polynomial runtime w.r.t training set size, so this problem compounds as data quantity increases. We propose a novel TSC algorithm, TS-CHIEF, which is highly competitive to HIVE-COTE in accuracy, but requires only a fraction of the runtime. TS-CHIEF constructs an ensemble classifier that integrates the most effective embeddings of time series that research has developed in the last decade. It uses tree-structured classifiers to do so efficiently. We assess TS-CHIEF on 85 datasets of the UCR archive, where it achieves state-of-the-art accuracy with scalability and efficiency. We demonstrate that TS-CHIEF can be trained on 130k time series in 2 days, a data quantity that is beyond the reach of any TSC algorithm with comparable accuracy.
Temporal Convolutional Neural Network for the Classification of Satellite Image Time Series
Nov 26, 2018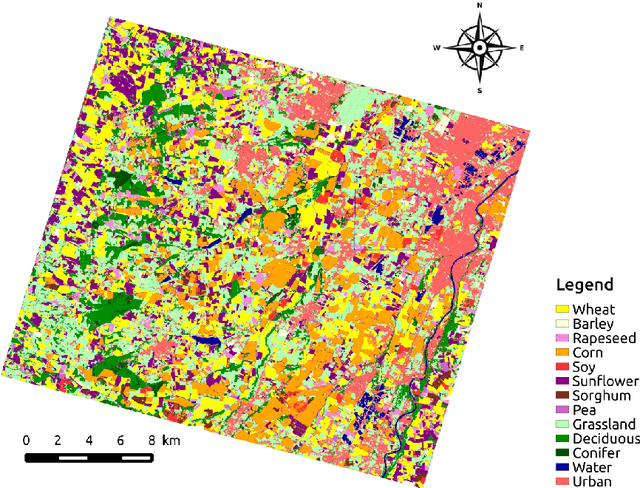
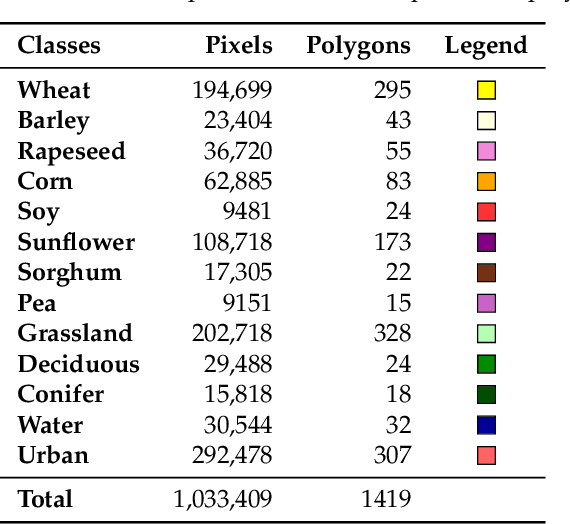

New remote sensing sensors acquire now high spatial and spectral Satellite Image Time Series (SITS) of the world. These series of images are a key component of any classification framework to obtain up-to-date and accurate land cover maps of the Earth's soils. More specifically, the combination of the temporal, spectral and spatial resolutions of new SITS enables the monitoring of vegetation dynamics. Although some traditional classification algorithms, such as Random Forest (RF), have been successfully applied for SITS classification, these algorithms do not fully take advantage of the temporal domain. Conversely, deep-learning based methods have been successfully used to make the most of sequential data such as text and audio data. For the first time, this paper explores the use of Convolutional Neural Networks (CNNs) with convolutions applied in the temporal dimension for SITS classification. The goal is to quantitatively and qualitatively evaluate the contribution of temporal CNNs for SITS classification. More precisely, this paper proposes a set of experiments performed on a million Formosat-2 time series. The experimental results show that temporal CNNs are 2 to 3 % more accurate than RF. The experiments also highlight some counter-intuitive results on pooling layers: contrary to image classification, their use decreases accuracy. Moreover, we provide some general guidelines on the network architecture, common regularization mechanisms, and hyper-parameter values such as the batch size. Finally, the visual quality of the land cover maps produced by the temporal CNN is assessed.
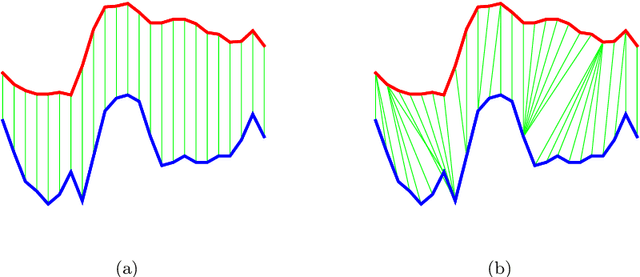
Elastic bands across the path: A new framework and methods to lower bound DTW
Oct 17, 2018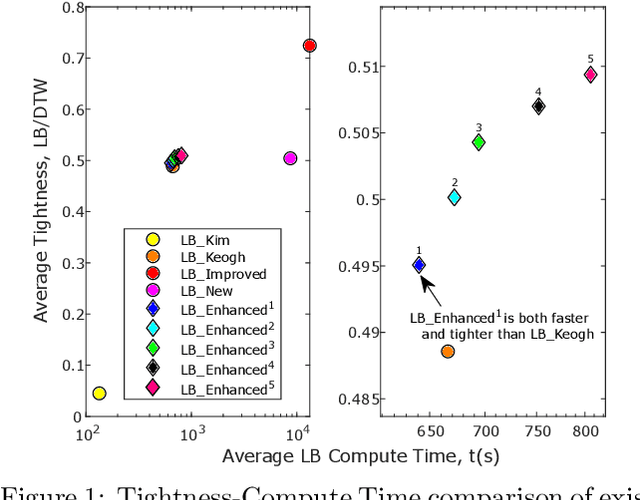
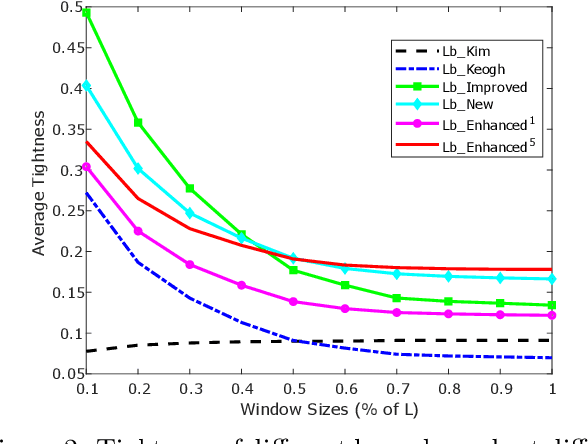
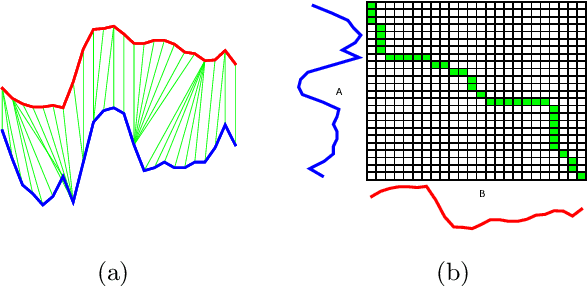
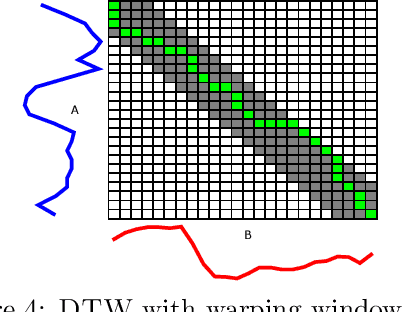
There has been renewed recent interest in developing effective lower bounds for Dynamic Time Warping (DTW) distance between time series. These have many applications in time series indexing, clustering, forecasting, regression and classification. One of the key time series classification algorithms, the nearest neighbor algorithm with DTW distance (NN-DTW) is very expensive to compute, due to the quadratic complexity of DTW. Lower bound search can speed up NN-DTW substantially. An effective and tight lower bound quickly prunes off unpromising nearest neighbor candidates from the search space and minimises the number of the costly DTW computations. The speed up provided by lower bound search becomes increasingly critical as training set size increases. Different lower bounds provide different trade-offs between computation time and tightness. Most existing lower bounds interact with DTW warping window sizes. They are very tight and effective at smaller warping window sizes, but become looser as the warping window increases, thus reducing the pruning effectiveness for NN-DTW. In this work, we present a new class of lower bounds that are tighter than the popular Keogh lower bound, while requiring similar computation time. Our new lower bounds take advantage of the DTW boundary condition, monotonicity and continuity constraints to create a tighter lower bound. Of particular significance, they remain relatively tight even for large windows. A single parameter to these new lower bounds controls the speed-tightness trade-off. We demonstrate that these new lower bounds provide an exceptional balance between computation time and tightness for the NN-DTW time series classification task, resulting in greatly improved efficiency for NN-DTW lower bound search.