 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
Scalable Probabilistic Forecasting in Retail with Gradient Boosted Trees: A Practitioner's Approach
Nov 02, 2023


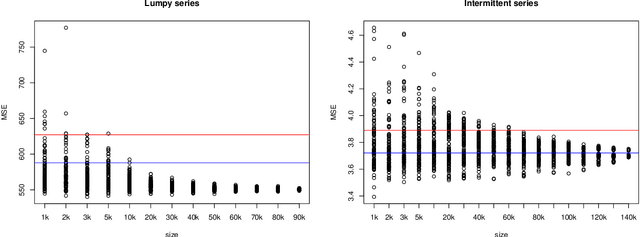
The recent M5 competition has advanced the state-of-the-art in retail forecasting. However, we notice important differences between the competition challenge and the challenges we face in a large e-commerce company. The datasets in our scenario are larger (hundreds of thousands of time series), and e-commerce can afford to have a larger assortment than brick-and-mortar retailers, leading to more intermittent data. To scale to larger dataset sizes with feasible computational effort, firstly, we investigate a two-layer hierarchy and propose a top-down approach to forecasting at an aggregated level with less amount of series and intermittency, and then disaggregating to obtain the decision-level forecasts. Probabilistic forecasts are generated under distributional assumptions. Secondly, direct training at the lower level with subsamples can also be an alternative way of scaling. Performance of modelling with subsets is evaluated with the main dataset. Apart from a proprietary dataset, the proposed scalable methods are evaluated using the Favorita dataset and the M5 dataset. We are able to show the differences in characteristics of the e-commerce and brick-and-mortar retail datasets. Notably, our top-down forecasting framework enters the top 50 of the original M5 competition, even with models trained at a higher level under a much simpler setting.
On Forecast Stability
Oct 26, 2023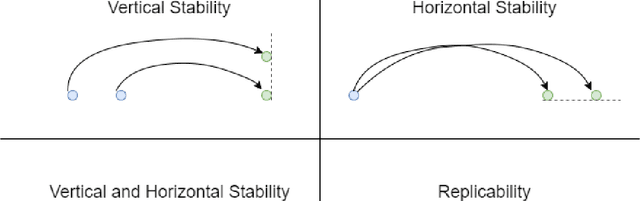

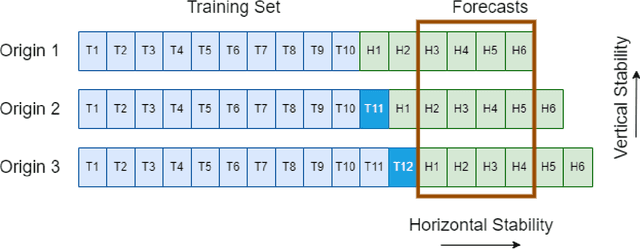

Forecasts are typically not produced in a vacuum but in a business context, where forecasts are generated on a regular basis and interact with each other. For decisions, it may be important that forecasts do not change arbitrarily, and are stable in some sense. However, this area has received only limited attention in the forecasting literature. In this paper, we explore two types of forecast stability that we call vertical stability and horizontal stability. The existing works in the literature are only applicable to certain base models and extending these frameworks to be compatible with any base model is not straightforward. Furthermore, these frameworks can only stabilise the forecasts vertically. To fill this gap, we propose a simple linear-interpolation-based approach that is applicable to stabilise the forecasts provided by any base model vertically and horizontally. The approach can produce both accurate and stable forecasts. Using N-BEATS, Pooled Regression and LightGBM as the base models, in our evaluation on four publicly available datasets, the proposed framework is able to achieve significantly higher stability and/or accuracy compared to a set of benchmarks including a state-of-the-art forecast stabilisation method across three error metrics and six stability metrics.
Handling Concept Drift in Global Time Series Forecasting
Apr 04, 2023



Machine learning (ML) based time series forecasting models often require and assume certain degrees of stationarity in the data when producing forecasts. However, in many real-world situations, the data distributions are not stationary and they can change over time while reducing the accuracy of the forecasting models, which in the ML literature is known as concept drift. Handling concept drift in forecasting is essential for many ML methods in use nowadays, however, the prior work only proposes methods to handle concept drift in the classification domain. To fill this gap, we explore concept drift handling methods in particular for Global Forecasting Models (GFM) which recently have gained popularity in the forecasting domain. We propose two new concept drift handling methods, namely: Error Contribution Weighting (ECW) and Gradient Descent Weighting (GDW), based on a continuous adaptive weighting concept. These methods use two forecasting models which are separately trained with the most recent series and all series, and finally, the weighted average of the forecasts provided by the two models are considered as the final forecasts. Using LightGBM as the underlying base learner, in our evaluation on three simulated datasets, the proposed models achieve significantly higher accuracy than a set of statistical benchmarks and LightGBM baselines across four evaluation metrics.
Comparison and Evaluation of Methods for a Predict+Optimize Problem in Renewable Energy
Dec 21, 2022
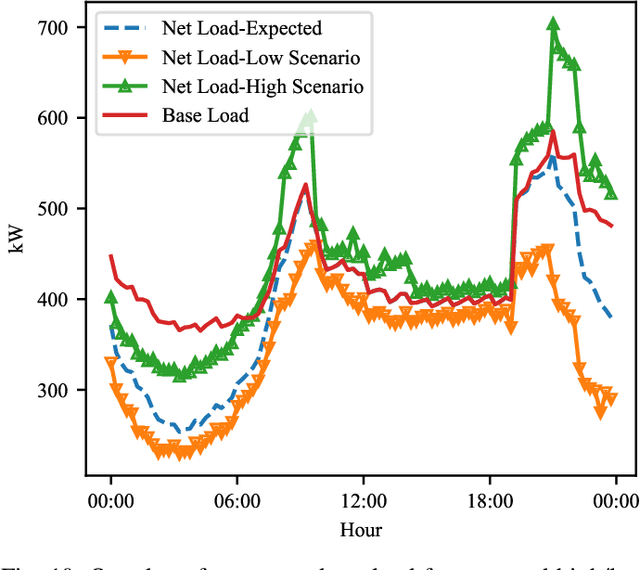
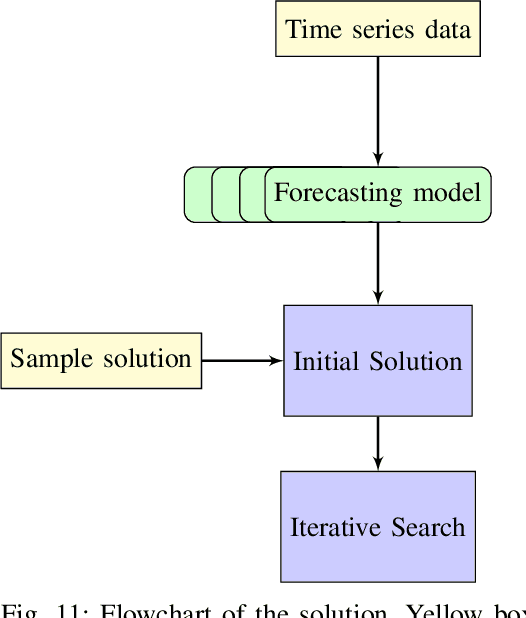
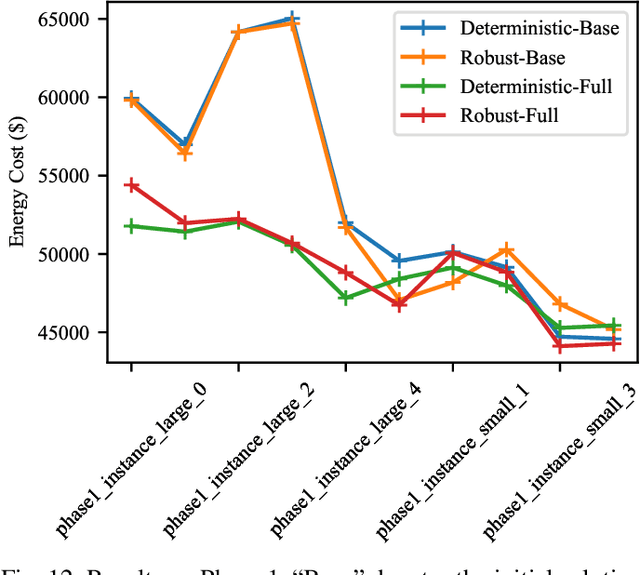
Algorithms that involve both forecasting and optimization are at the core of solutions to many difficult real-world problems, such as in supply chains (inventory optimization), traffic, and in the transition towards carbon-free energy generation in battery/load/production scheduling in sustainable energy systems. Typically, in these scenarios we want to solve an optimization problem that depends on unknown future values, which therefore need to be forecast. As both forecasting and optimization are difficult problems in their own right, relatively few research has been done in this area. This paper presents the findings of the ``IEEE-CIS Technical Challenge on Predict+Optimize for Renewable Energy Scheduling," held in 2021. We present a comparison and evaluation of the seven highest-ranked solutions in the competition, to provide researchers with a benchmark problem and to establish the state of the art for this benchmark, with the aim to foster and facilitate research in this area. The competition used data from the Monash Microgrid, as well as weather data and energy market data. It then focused on two main challenges: forecasting renewable energy production and demand, and obtaining an optimal schedule for the activities (lectures) and on-site batteries that lead to the lowest cost of energy. The most accurate forecasts were obtained by gradient-boosted tree and random forest models, and optimization was mostly performed using mixed integer linear and quadratic programming. The winning method predicted different scenarios and optimized over all scenarios jointly using a sample average approximation method.
SETAR-Tree: A Novel and Accurate Tree Algorithm for Global Time Series Forecasting
Nov 16, 2022Threshold Autoregressive (TAR) models have been widely used by statisticians for non-linear time series forecasting during the past few decades, due to their simplicity and mathematical properties. On the other hand, in the forecasting community, general-purpose tree-based regression algorithms (forests, gradient-boosting) have become popular recently due to their ease of use and accuracy. In this paper, we explore the close connections between TAR models and regression trees. These enable us to use the rich methodology from the literature on TAR models to define a hierarchical TAR model as a regression tree that trains globally across series, which we call SETAR-Tree. In contrast to the general-purpose tree-based models that do not primarily focus on forecasting, and calculate averages at the leaf nodes, we introduce a new forecasting-specific tree algorithm that trains global Pooled Regression (PR) models in the leaves allowing the models to learn cross-series information and also uses some time-series-specific splitting and stopping procedures. The depth of the tree is controlled by conducting a statistical linearity test commonly employed in TAR models, as well as measuring the error reduction percentage at each node split. Thus, the proposed tree model requires minimal external hyperparameter tuning and provides competitive results under its default configuration. We also use this tree algorithm to develop a forest where the forecasts provided by a collection of diverse SETAR-Trees are combined during the forecasting process. In our evaluation on eight publicly available datasets, the proposed tree and forest models are able to achieve significantly higher accuracy than a set of state-of-the-art tree-based algorithms and forecasting benchmarks across four evaluation metrics.
Monash Time Series Forecasting Archive
May 14, 2021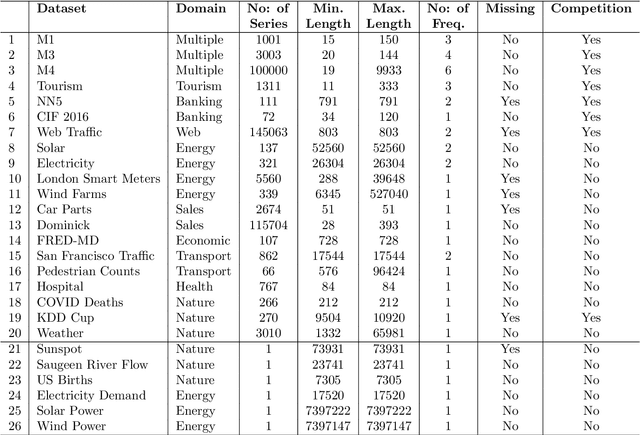


Many businesses and industries nowadays rely on large quantities of time series data making time series forecasting an important research area. Global forecasting models that are trained across sets of time series have shown a huge potential in providing accurate forecasts compared with the traditional univariate forecasting models that work on isolated series. However, there are currently no comprehensive time series archives for forecasting that contain datasets of time series from similar sources available for the research community to evaluate the performance of new global forecasting algorithms over a wide variety of datasets. In this paper, we present such a comprehensive time series forecasting archive containing 20 publicly available time series datasets from varied domains, with different characteristics in terms of frequency, series lengths, and inclusion of missing values. We also characterise the datasets, and identify similarities and differences among them, by conducting a feature analysis. Furthermore, we present the performance of a set of standard baseline forecasting methods over all datasets across eight error metrics, for the benefit of researchers using the archive to benchmark their forecasting algorithms.
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020

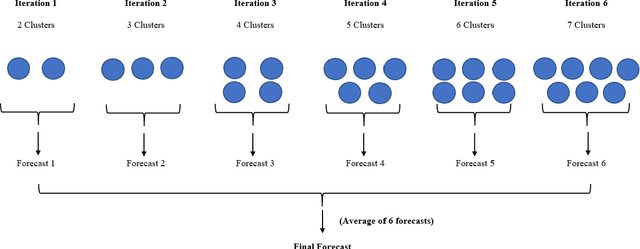
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
A Strong Baseline for Weekly Time Series Forecasting
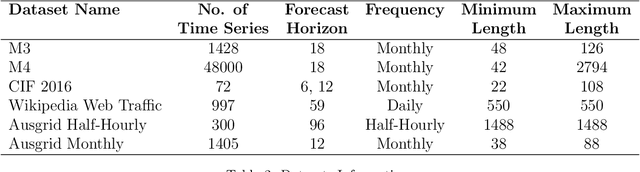
Oct 16, 2020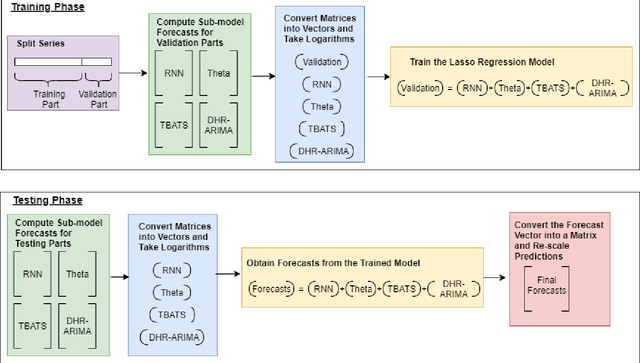

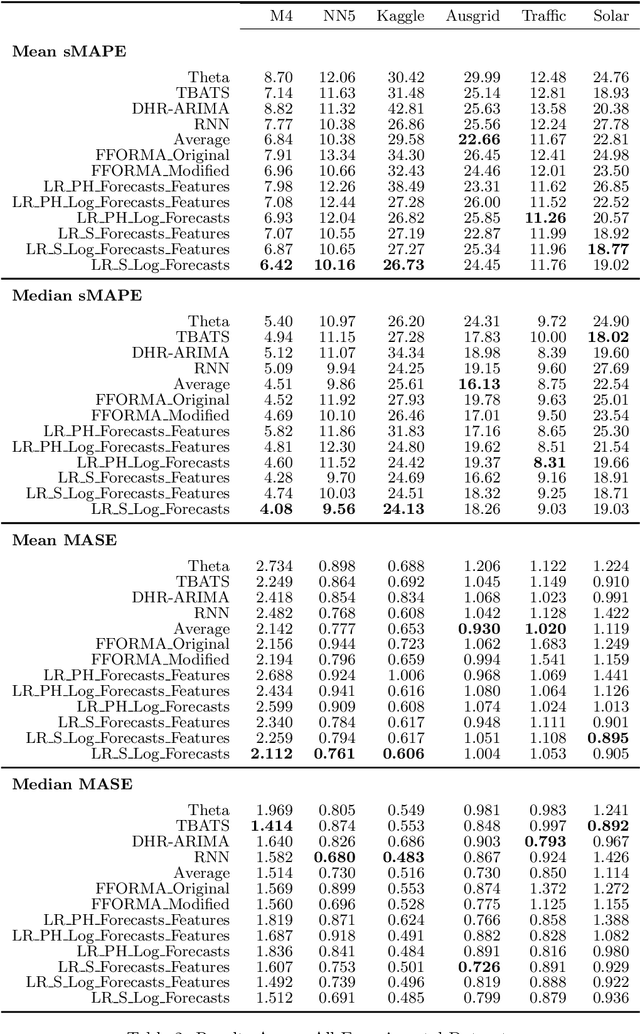
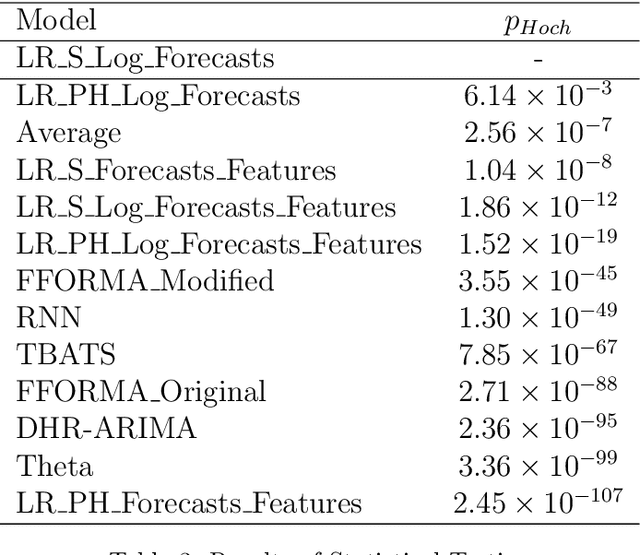
Many businesses and industries require accurate forecasts for weekly time series nowadays. The forecasting literature however does not currently provide easy-to-use, automatic, reproducible and accurate approaches dedicated to this task. We propose a forecasting method that can be used as a strong baseline in this domain, leveraging state-of-the-art forecasting techniques, forecast combination, and global modelling. Our approach uses four base forecasting models specifically suitable for forecasting weekly data: a global Recurrent Neural Network model, Theta, Trigonometric Box-Cox ARMA Trend Seasonal (TBATS), and Dynamic Harmonic Regression ARIMA (DHR-ARIMA). Those are then optimally combined using a lasso regression stacking approach. We evaluate the performance of our method against a set of state-of-the-art weekly forecasting models on six datasets. Across four evaluation metrics, we show that our method consistently outperforms the benchmark methods by a considerable margin with statistical significance. In particular, our model can produce the most accurate forecasts, in terms of mean sMAPE, for the M4 weekly dataset.
Seasonal Averaged One-Dependence Estimators: A Novel Algorithm to Address Seasonal Concept Drift in High-Dimensional Stream Classification
Jun 27, 2020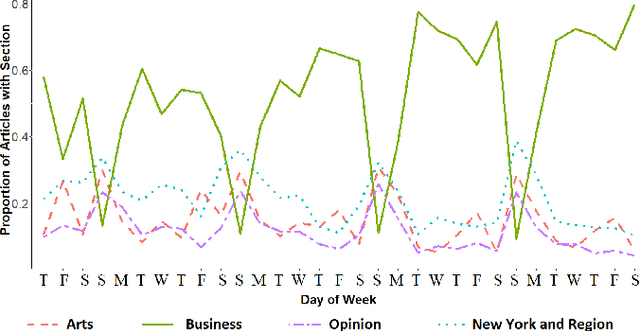
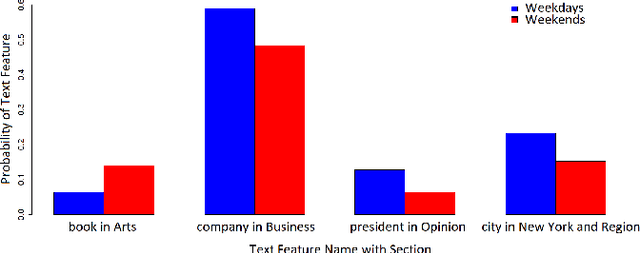
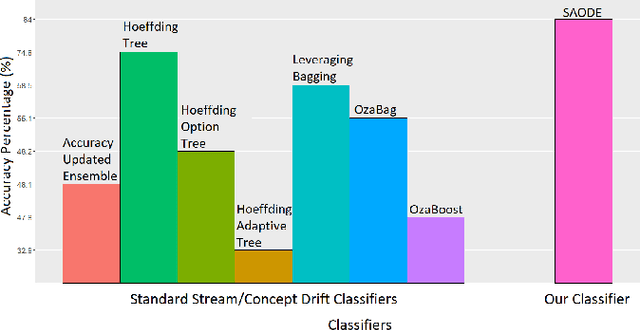
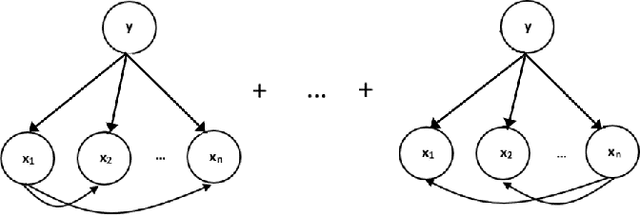
Stream classification methods classify a continuous stream of data as new labelled samples arrive. They often also have to deal with concept drift. This paper focuses on seasonal drift in stream classification, which can be found in many real-world application data sources. Traditional approaches of stream classification consider seasonal drift by including seasonal dummy/indicator variables or building separate models for each season. But these approaches have strong limitations in high-dimensional classification problems, or with complex seasonal patterns. This paper explores how to best handle seasonal drift in the specific context of news article categorization (or classification/tagging), where seasonal drift is overwhelmingly the main type of drift present in the data, and for which the data are high-dimensional. We introduce a novel classifier named Seasonal Averaged One-Dependence Estimators (SAODE), which extends the AODE classifier to handle seasonal drift by including time as a super parent. We assess our SAODE model using two large real-world text mining related datasets each comprising approximately a million records, against nine state-of-the-art stream and concept drift classification models, with and without seasonal indicators and with separate models built for each season. Across five different evaluation techniques, we show that our model consistently outperforms other methods by a large margin where the results are statistically significant.