 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Value Modelling of Feature Residuals for Anomaly Detection in Dynamic Graphs
Oct 08, 2024Detecting anomalies in a temporal sequence of graphs can be applied is areas such as the detection of accidents in transport networks and cyber attacks in computer networks. Existing methods for detecting abnormal graphs can suffer from multiple limitations, such as high false positive rates as well as difficulties with handling variable-sized graphs and non-trivial temporal dynamics. To address this, we propose a technique where temporal dependencies are explicitly modelled via time series analysis of a large set of pertinent graph features, followed by using residuals to remove the dependencies. Extreme Value Theory is then used to robustly model and classify any remaining extremes, aiming to produce low false positives rates. Comparative evaluations on a multitude of graph instances show that the proposed approach obtains considerably better accuracy than TensorSplat and Laplacian Anomaly Detection.
Monash Time Series Forecasting Archive
May 14, 2021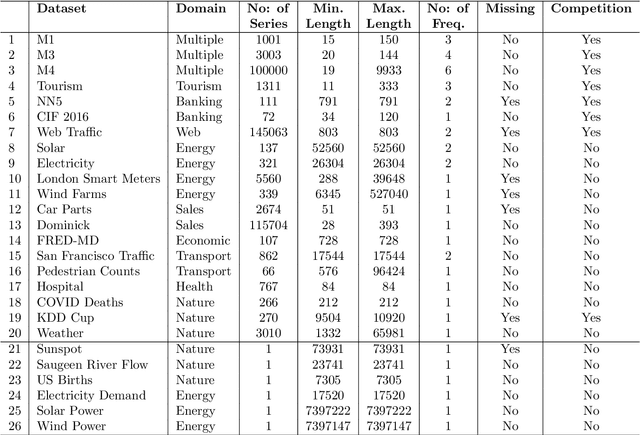


Many businesses and industries nowadays rely on large quantities of time series data making time series forecasting an important research area. Global forecasting models that are trained across sets of time series have shown a huge potential in providing accurate forecasts compared with the traditional univariate forecasting models that work on isolated series. However, there are currently no comprehensive time series archives for forecasting that contain datasets of time series from similar sources available for the research community to evaluate the performance of new global forecasting algorithms over a wide variety of datasets. In this paper, we present such a comprehensive time series forecasting archive containing 20 publicly available time series datasets from varied domains, with different characteristics in terms of frequency, series lengths, and inclusion of missing values. We also characterise the datasets, and identify similarities and differences among them, by conducting a feature analysis. Furthermore, we present the performance of a set of standard baseline forecasting methods over all datasets across eight error metrics, for the benefit of researchers using the archive to benchmark their forecasting algorithms.
Anomaly Detection in High Dimensional Data
Aug 12, 2019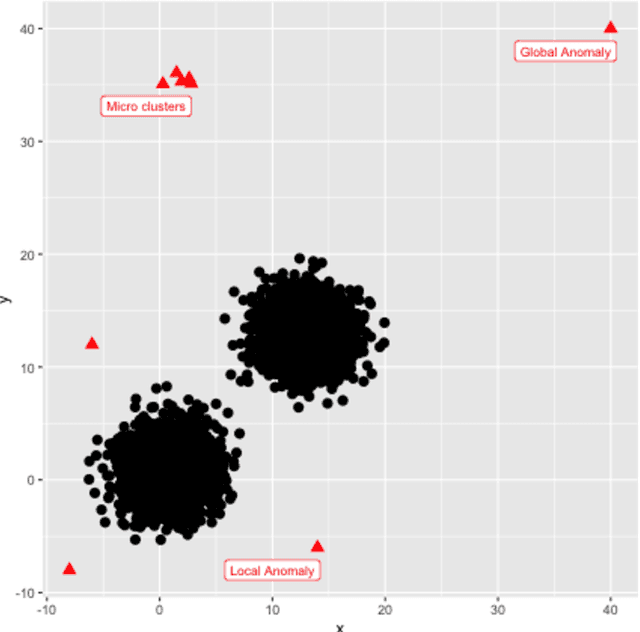
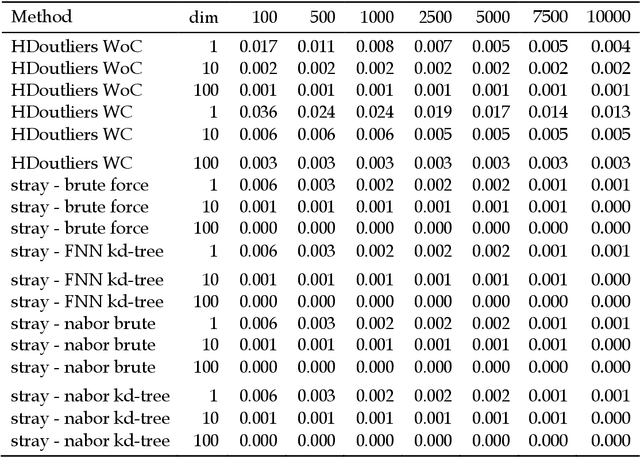
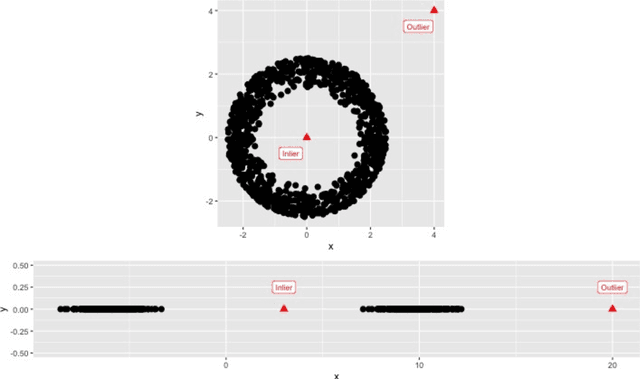
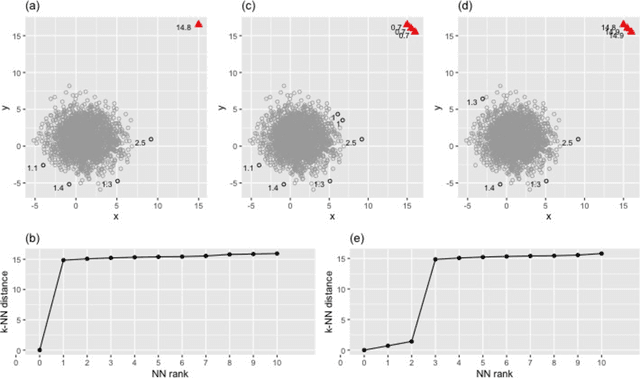
The HDoutliers algorithm is a powerful unsupervised algorithm for detecting anomalies in high-dimensional data, with a strong theoretical foundation. However, it suffers from some limitations that significantly hinder its performance level, under certain circumstances. In this article, we propose an algorithm that addresses these limitations. We define an anomaly as an observation that deviates markedly from the majority with a large distance gap. An approach based on extreme value theory is used for the anomalous threshold calculation. Using various synthetic and real datasets, we demonstrate the wide applicability and usefulness of our algorithm, which we call the stray algorithm. We also demonstrate how this algorithm can assist in detecting anomalies present in other data structures using feature engineering. We show the situations where the stray algorithm outperforms the HDoutliers algorithm both in accuracy and computational time. This framework is implemented in the open source R package stray.