 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising harmful data sources when constructing multi-fidelity surrogate models
Mar 12, 2024



Surrogate modelling techniques have seen growing attention in recent years when applied to both modelling and optimisation of industrial design problems. These techniques are highly relevant when assessing the performance of a particular design carries a high cost, as the overall cost can be mitigated via the construction of a model to be queried in lieu of the available high-cost source. The construction of these models can sometimes employ other sources of information which are both cheaper and less accurate. The existence of these sources however poses the question of which sources should be used when constructing a model. Recent studies have attempted to characterise harmful data sources to guide practitioners in choosing when to ignore a certain source. These studies have done so in a synthetic setting, characterising sources using a large amount of data that is not available in practice. Some of these studies have also been shown to potentially suffer from bias in the benchmarks used in the analysis. In this study, we present a characterisation of harmful low-fidelity sources using only the limited data available to train a surrogate model. We employ recently developed benchmark filtering techniques to conduct a bias-free assessment, providing objectively varied benchmark suites of different sizes for future research. Analysing one of these benchmark suites with the technique known as Instance Space Analysis, we provide an intuitive visualisation of when a low-fidelity source should be used and use this analysis to provide guidelines that can be used in an applied industrial setting.
Comprehensive Algorithm Portfolio Evaluation using Item Response Theory
Jul 29, 2023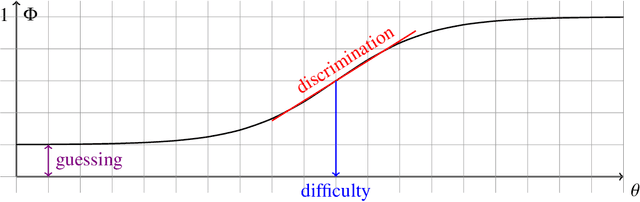
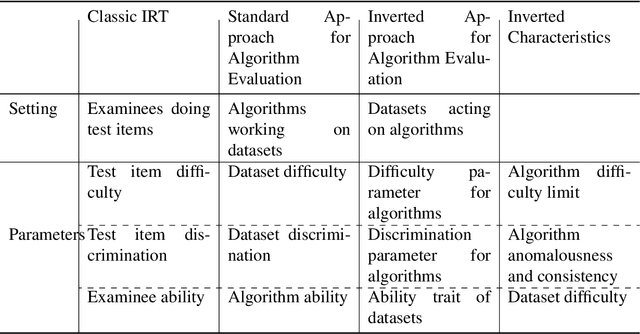
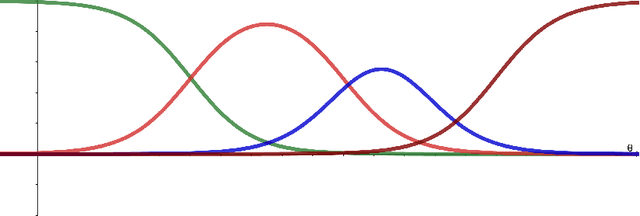
Item Response Theory (IRT) has been proposed within the field of Educational Psychometrics to assess student ability as well as test question difficulty and discrimination power. More recently, IRT has been applied to evaluate machine learning algorithm performance on a single classification dataset, where the student is now an algorithm, and the test question is an observation to be classified by the algorithm. In this paper we present a modified IRT-based framework for evaluating a portfolio of algorithms across a repository of datasets, while simultaneously eliciting a richer suite of characteristics - such as algorithm consistency and anomalousness - that describe important aspects of algorithm performance. These characteristics arise from a novel inversion and reinterpretation of the traditional IRT model without requiring additional dataset feature computations. We test this framework on algorithm portfolios for a wide range of applications, demonstrating the broad applicability of this method as an insightful algorithm evaluation tool. Furthermore, the explainable nature of IRT parameters yield an increased understanding of algorithm portfolios.
An Efficient Transformer for Simultaneous Learning of BEV and Lane Representations in 3D Lane Detection
Jun 08, 2023
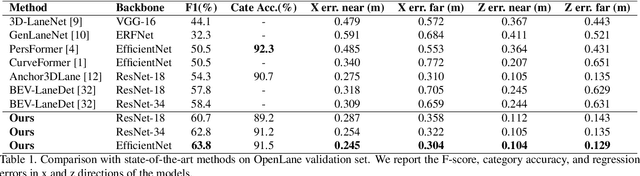

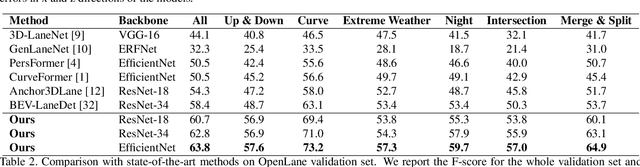
Accurately detecting lane lines in 3D space is crucial for autonomous driving. Existing methods usually first transform image-view features into bird-eye-view (BEV) by aid of inverse perspective mapping (IPM), and then detect lane lines based on the BEV features. However, IPM ignores the changes in road height, leading to inaccurate view transformations. Additionally, the two separate stages of the process can cause cumulative errors and increased complexity. To address these limitations, we propose an efficient transformer for 3D lane detection. Different from the vanilla transformer, our model contains a decomposed cross-attention mechanism to simultaneously learn lane and BEV representations. The mechanism decomposes the cross-attention between image-view and BEV features into the one between image-view and lane features, and the one between lane and BEV features, both of which are supervised with ground-truth lane lines. Our method obtains 2D and 3D lane predictions by applying the lane features to the image-view and BEV features, respectively. This allows for a more accurate view transformation than IPM-based methods, as the view transformation is learned from data with a supervised cross-attention. Additionally, the cross-attention between lane and BEV features enables them to adjust to each other, resulting in more accurate lane detection than the two separate stages. Finally, the decomposed cross-attention is more efficient than the original one. Experimental results on OpenLane and ONCE-3DLanes demonstrate the state-of-the-art performance of our method.
PyHard: a novel tool for generating hardness embeddings to support data-centric analysis
Sep 29, 2021
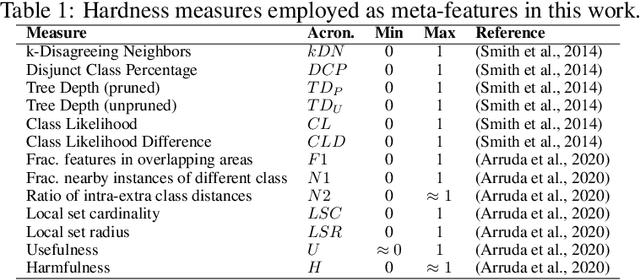

For building successful Machine Learning (ML) systems, it is imperative to have high quality data and well tuned learning models. But how can one assess the quality of a given dataset? And how can the strengths and weaknesses of a model on a dataset be revealed? Our new tool PyHard employs a methodology known as Instance Space Analysis (ISA) to produce a hardness embedding of a dataset relating the predictive performance of multiple ML models to estimated instance hardness meta-features. This space is built so that observations are distributed linearly regarding how hard they are to classify. The user can visually interact with this embedding in multiple ways and obtain useful insights about data and algorithmic performance along the individual observations of the dataset. We show in a COVID prognosis dataset how this analysis supported the identification of pockets of hard observations that challenge ML models and are therefore worth closer inspection, and the delineation of regions of strengths and weaknesses of ML models.
Anomaly Detection in High Dimensional Data
Aug 12, 2019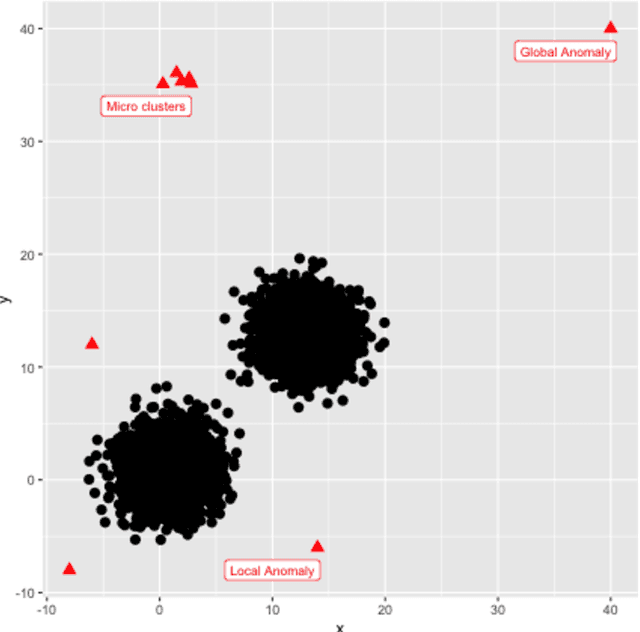
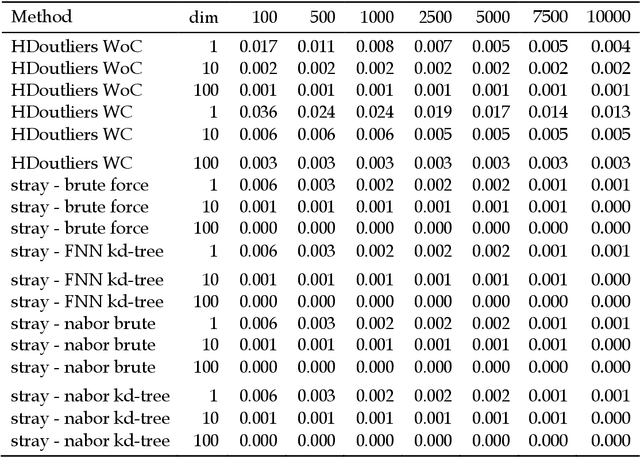
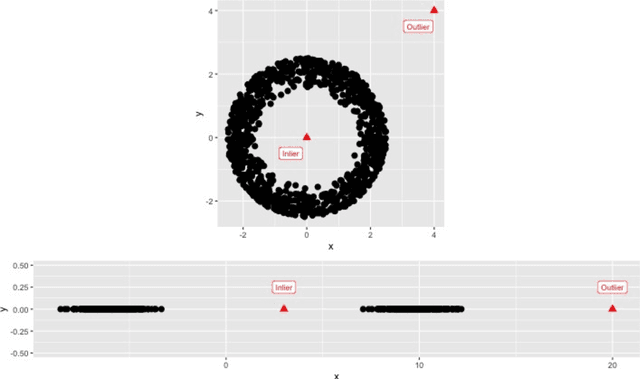
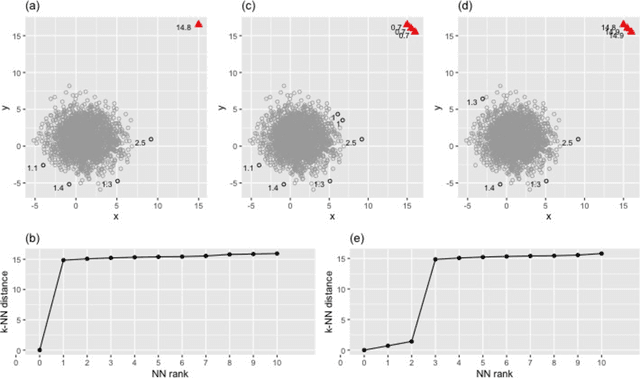
The HDoutliers algorithm is a powerful unsupervised algorithm for detecting anomalies in high-dimensional data, with a strong theoretical foundation. However, it suffers from some limitations that significantly hinder its performance level, under certain circumstances. In this article, we propose an algorithm that addresses these limitations. We define an anomaly as an observation that deviates markedly from the majority with a large distance gap. An approach based on extreme value theory is used for the anomalous threshold calculation. Using various synthetic and real datasets, we demonstrate the wide applicability and usefulness of our algorithm, which we call the stray algorithm. We also demonstrate how this algorithm can assist in detecting anomalies present in other data structures using feature engineering. We show the situations where the stray algorithm outperforms the HDoutliers algorithm both in accuracy and computational time. This framework is implemented in the open source R package stray.