 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Interactions of Modular CMA-ES Configurations Across Problem Landscapes
Jul 03, 2025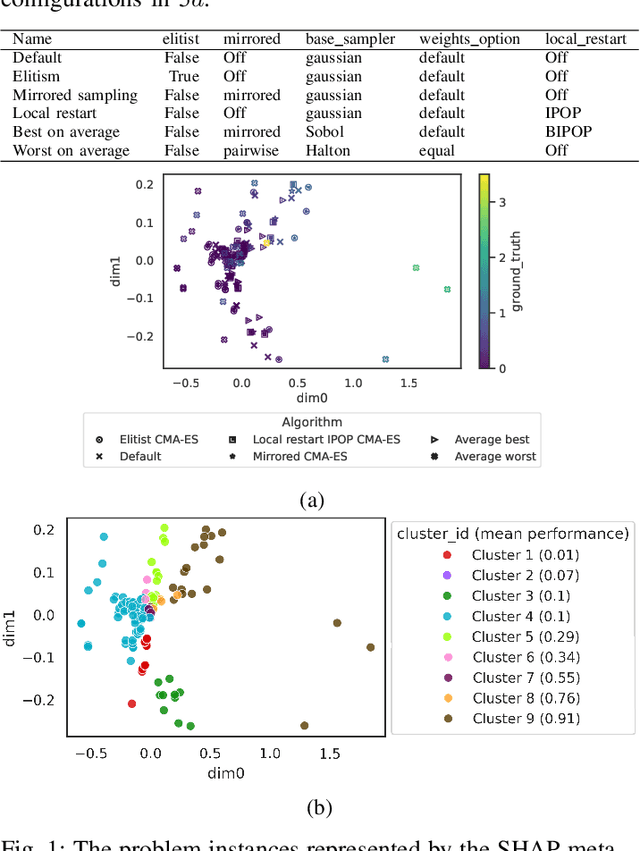
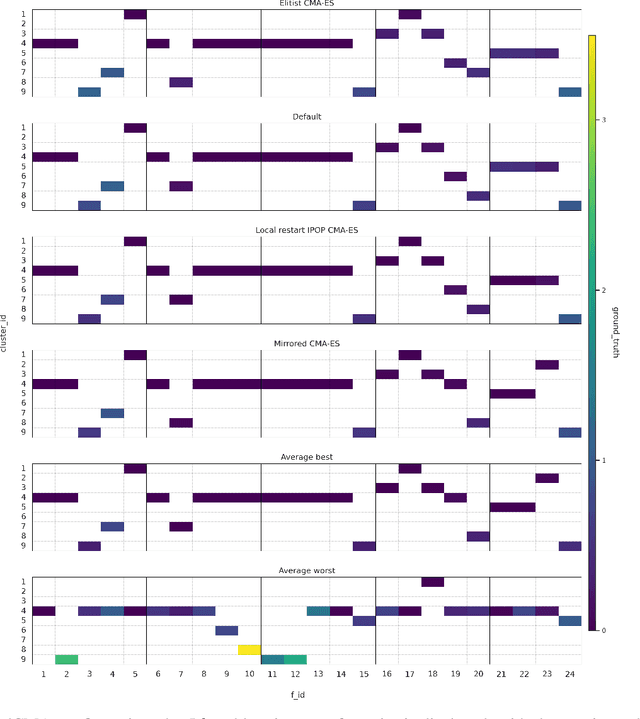
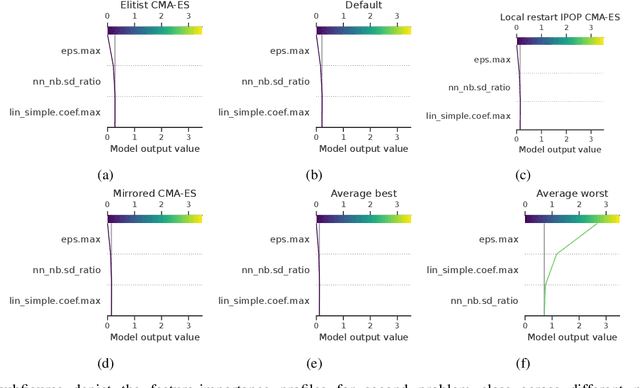
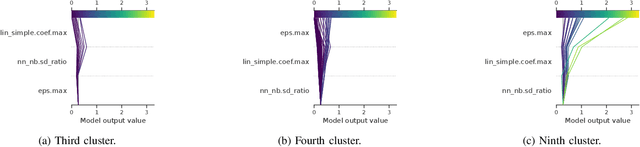
This paper leverages the recently introduced concept of algorithm footprints to investigate the interplay between algorithm configurations and problem characteristics. Performance footprints are calculated for six modular variants of the CMA-ES algorithm (modCMA), evaluated on 24 benchmark problems from the BBOB suite, across two-dimensional settings: 5-dimensional and 30-dimensional. These footprints provide insights into why different configurations of the same algorithm exhibit varying performance and identify the problem features influencing these outcomes. Our analysis uncovers shared behavioral patterns across configurations due to common interactions with problem properties, as well as distinct behaviors on the same problem driven by differing problem features. The results demonstrate the effectiveness of algorithm footprints in enhancing interpretability and guiding configuration choices.
An Item Response Theory-based R Module for Algorithm Portfolio Analysis
Aug 27, 2024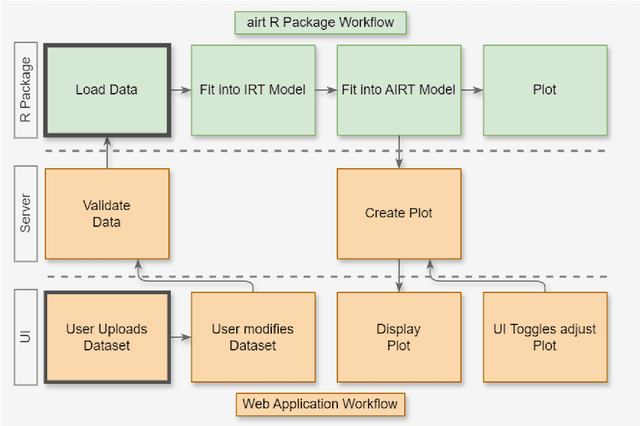
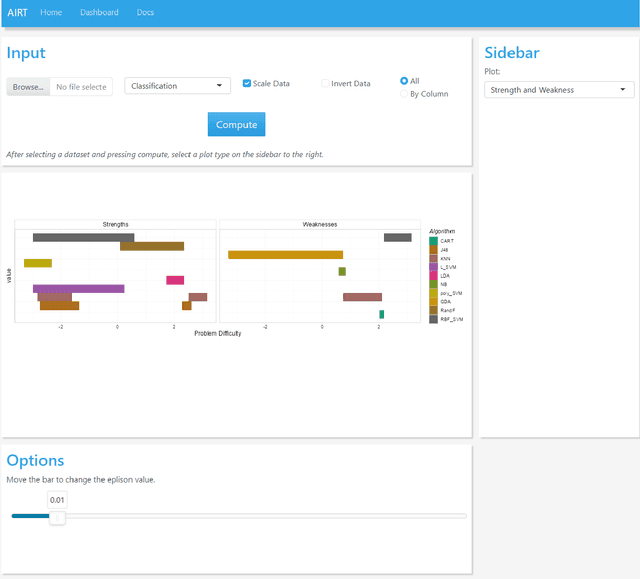
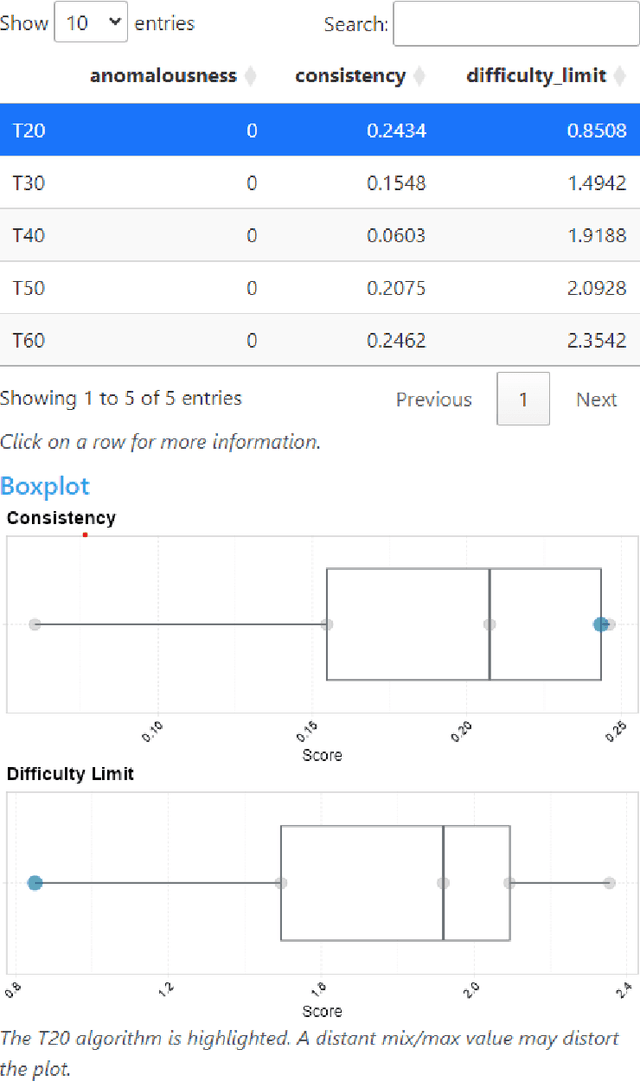
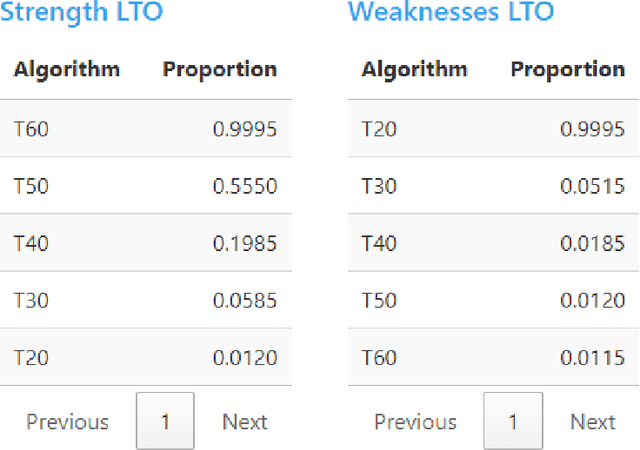
Experimental evaluation is crucial in AI research, especially for assessing algorithms across diverse tasks. Many studies often evaluate a limited set of algorithms, failing to fully understand their strengths and weaknesses within a comprehensive portfolio. This paper introduces an Item Response Theory (IRT) based analysis tool for algorithm portfolio evaluation called AIRT-Module. Traditionally used in educational psychometrics, IRT models test question difficulty and student ability using responses to test questions. Adapting IRT to algorithm evaluation, the AIRT-Module contains a Shiny web application and the R package airt. AIRT-Module uses algorithm performance measures to compute anomalousness, consistency, and difficulty limits for an algorithm and the difficulty of test instances. The strengths and weaknesses of algorithms are visualised using the difficulty spectrum of the test instances. AIRT-Module offers a detailed understanding of algorithm capabilities across varied test instances, thus enhancing comprehensive AI method assessment. It is available at https://sevvandi.shinyapps.io/AIRT/ .
Characterising harmful data sources when constructing multi-fidelity surrogate models
Mar 12, 2024



Surrogate modelling techniques have seen growing attention in recent years when applied to both modelling and optimisation of industrial design problems. These techniques are highly relevant when assessing the performance of a particular design carries a high cost, as the overall cost can be mitigated via the construction of a model to be queried in lieu of the available high-cost source. The construction of these models can sometimes employ other sources of information which are both cheaper and less accurate. The existence of these sources however poses the question of which sources should be used when constructing a model. Recent studies have attempted to characterise harmful data sources to guide practitioners in choosing when to ignore a certain source. These studies have done so in a synthetic setting, characterising sources using a large amount of data that is not available in practice. Some of these studies have also been shown to potentially suffer from bias in the benchmarks used in the analysis. In this study, we present a characterisation of harmful low-fidelity sources using only the limited data available to train a surrogate model. We employ recently developed benchmark filtering techniques to conduct a bias-free assessment, providing objectively varied benchmark suites of different sizes for future research. Analysing one of these benchmark suites with the technique known as Instance Space Analysis, we provide an intuitive visualisation of when a low-fidelity source should be used and use this analysis to provide guidelines that can be used in an applied industrial setting.
Algorithm Instance Footprint: Separating Easily Solvable and Challenging Problem Instances
Jun 01, 2023



In black-box optimization, it is essential to understand why an algorithm instance works on a set of problem instances while failing on others and provide explanations of its behavior. We propose a methodology for formulating an algorithm instance footprint that consists of a set of problem instances that are easy to be solved and a set of problem instances that are difficult to be solved, for an algorithm instance. This behavior of the algorithm instance is further linked to the landscape properties of the problem instances to provide explanations of which properties make some problem instances easy or challenging. The proposed methodology uses meta-representations that embed the landscape properties of the problem instances and the performance of the algorithm into the same vector space. These meta-representations are obtained by training a supervised machine learning regression model for algorithm performance prediction and applying model explainability techniques to assess the importance of the landscape features to the performance predictions. Next, deterministic clustering of the meta-representations demonstrates that using them captures algorithm performance across the space and detects regions of poor and good algorithm performance, together with an explanation of which landscape properties are leading to it.
An Instance Space Analysis of Constrained Multi-Objective Optimization Problems
Mar 02, 2022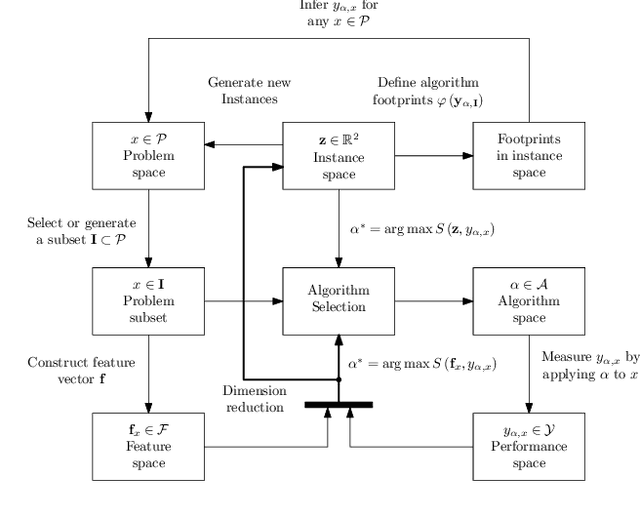

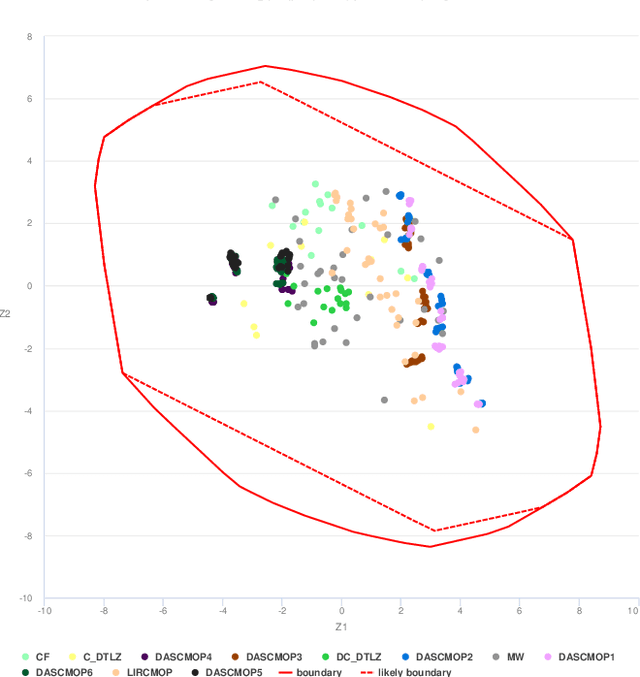
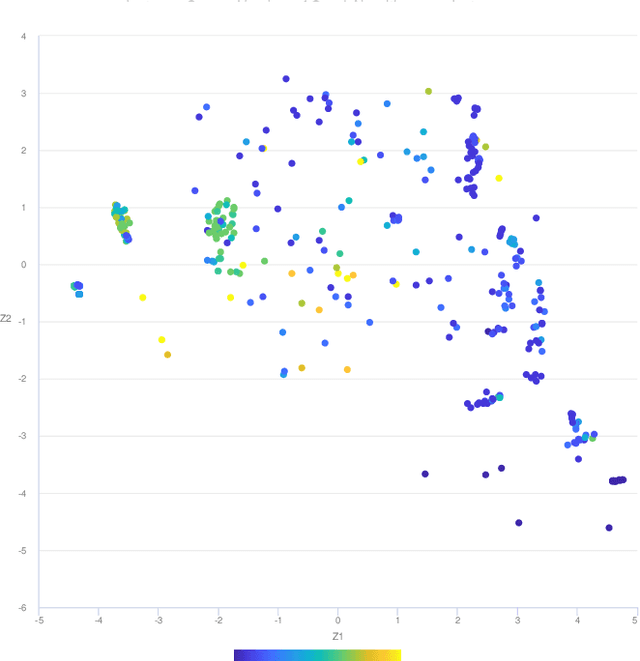
Multi-objective optimization problems with constraints (CMOPs) are generally considered more challenging than those without constraints. This in part can be attributed to the creation of infeasible regions generated by the constraint functions, and/or the interaction between constraints and objectives. In this paper, we explore the relationship between constrained multi-objective evolutionary algorithms (CMOEAs) performance and CMOP instances characteristics using Instance Space Analysis (ISA). To do this, we extend recent work focused on the use of Landscape Analysis features to characterise CMOP. Specifically, we scrutinise the multi-objective landscape and introduce new features to describe the multi-objective-violation landscape, formed by the interaction between constraint violation and multi-objective fitness. Detailed evaluation of problem-algorithm footprints spanning six CMOP benchmark suites and fifteen CMOEAs, illustrates that ISA can effectively capture the strength and weakness of the CMOEAs. We conclude that two key characteristics, the isolation of non-dominate set and the correlation between constraints and objectives evolvability, have the greatest impact on algorithm performance. However, the current benchmarks problems do not provide enough diversity to fully reveal the efficacy of CMOEAs evaluated.