 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Impact of Modules and Their Interactions in the PSO-X Framework
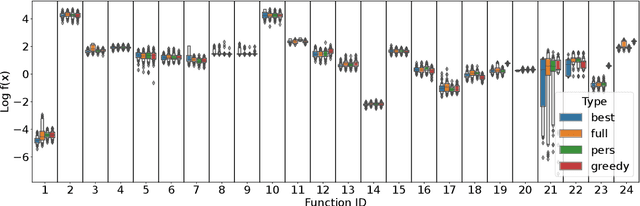
Jan 07, 2026The PSO-X framework incorporates dozens of modules that have been proposed for solving single-objective continuous optimization problems using particle swarm optimization. While modular frameworks enable users to automatically generate and configure algorithms tailored to specific optimization problems, the complexity of this process increases with the number of modules in the framework and the degrees of freedom defined for their interaction. Understanding how modules affect the performance of algorithms for different problems is critical to making the process of finding effective implementations more efficient and identifying promising areas for further investigation. Despite their practical applications and scientific relevance, there is a lack of empirical studies investigating which modules matter most in modular optimization frameworks and how they interact. In this paper, we analyze the performance of 1424 particle swarm optimization algorithms instantiated from the PSO-X framework on the 25 functions in the CEC'05 benchmark suite with 10 and 30 dimensions. We use functional ANOVA to quantify the impact of modules and their combinations on performance in different problem classes. In practice, this allows us to identify which modules have greater influence on PSO-X performance depending on problem features such as multimodality, mathematical transformations and varying dimensionality. We then perform a cluster analysis to identify groups of problem classes that share similar module effect patterns. Our results show low variability in the importance of modules in all problem classes, suggesting that particle swarm optimization performance is driven by a few influential modules.
Tracing the Interactions of Modular CMA-ES Configurations Across Problem Landscapes
Jul 03, 2025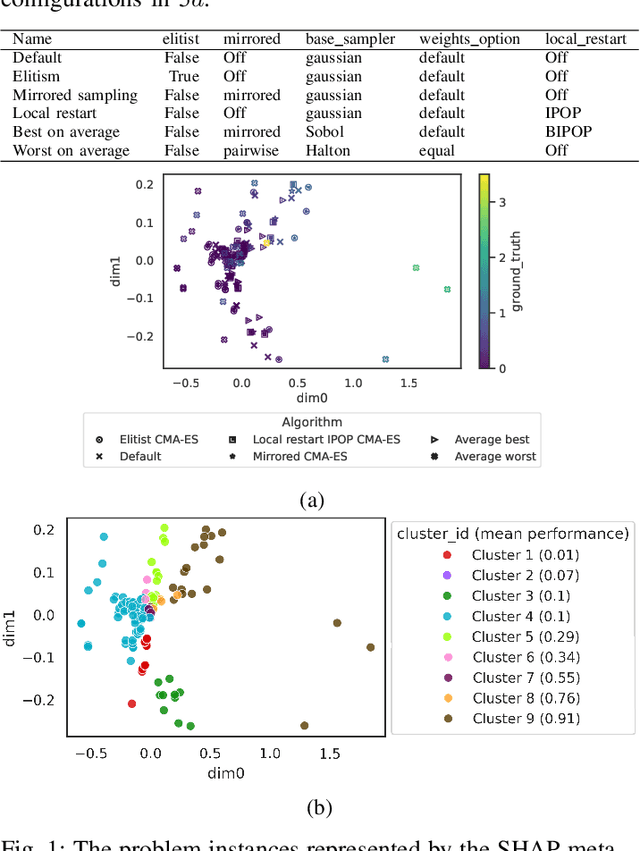
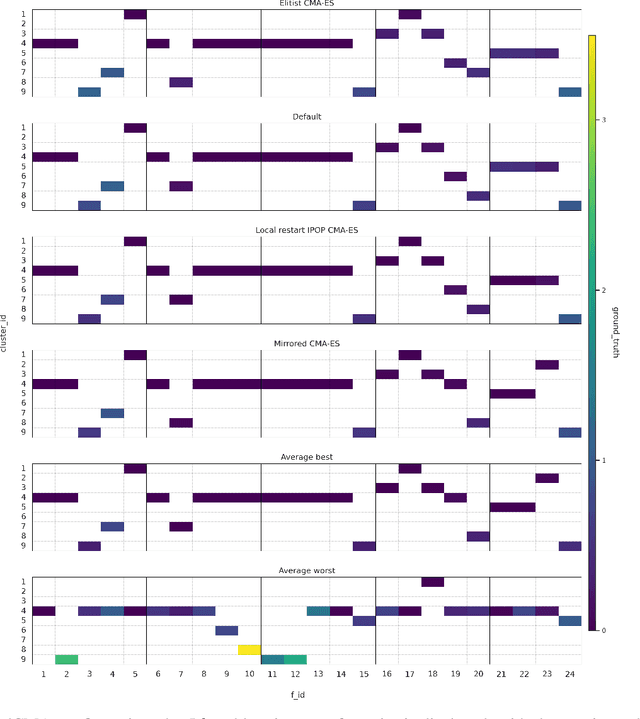
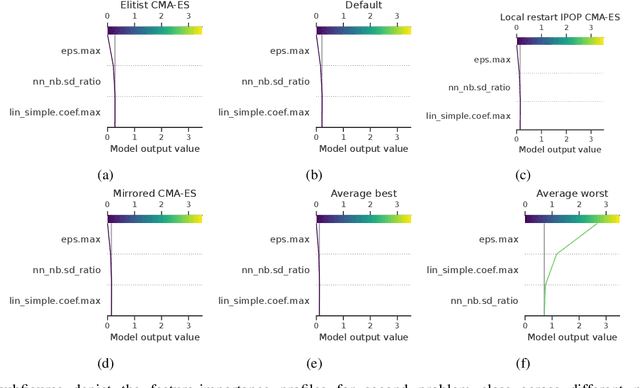
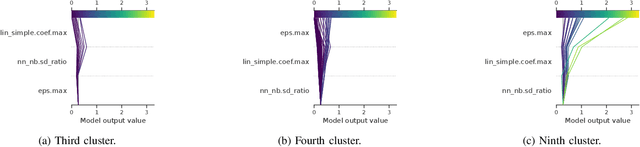
This paper leverages the recently introduced concept of algorithm footprints to investigate the interplay between algorithm configurations and problem characteristics. Performance footprints are calculated for six modular variants of the CMA-ES algorithm (modCMA), evaluated on 24 benchmark problems from the BBOB suite, across two-dimensional settings: 5-dimensional and 30-dimensional. These footprints provide insights into why different configurations of the same algorithm exhibit varying performance and identify the problem features influencing these outcomes. Our analysis uncovers shared behavioral patterns across configurations due to common interactions with problem properties, as well as distinct behaviors on the same problem driven by differing problem features. The results demonstrate the effectiveness of algorithm footprints in enhancing interpretability and guiding configuration choices.
Customized Exploration of Landscape Features Driving Multi-Objective Combinatorial Optimization Performance
Jul 02, 2025We present an analysis of landscape features for predicting the performance of multi-objective combinatorial optimization algorithms. We consider features from the recently proposed compressed Pareto Local Optimal Solutions Networks (C-PLOS-net) model of combinatorial landscapes. The benchmark instances are a set of rmnk-landscapes with 2 and 3 objectives and various levels of ruggedness and objective correlation. We consider the performance of three algorithms -- Pareto Local Search (PLS), Global Simple EMO Optimizer (GSEMO), and Non-dominated Sorting Genetic Algorithm (NSGA-II) - using the resolution and hypervolume metrics. Our tailored analysis reveals feature combinations that influence algorithm performance specific to certain landscapes. This study provides deeper insights into feature importance, tailored to specific rmnk-landscapes and algorithms.
A Learning Search Algorithm for the Restricted Longest Common Subsequence Problem
Oct 15, 2024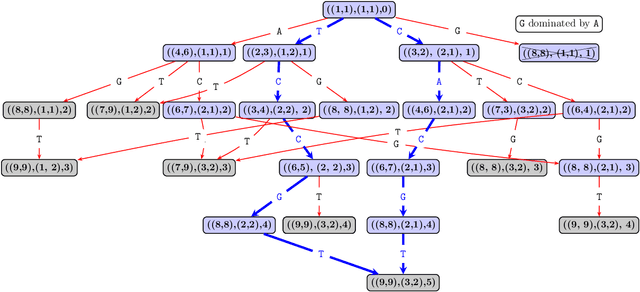
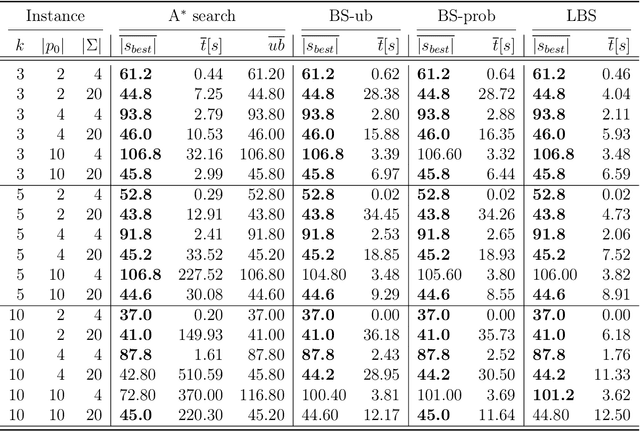
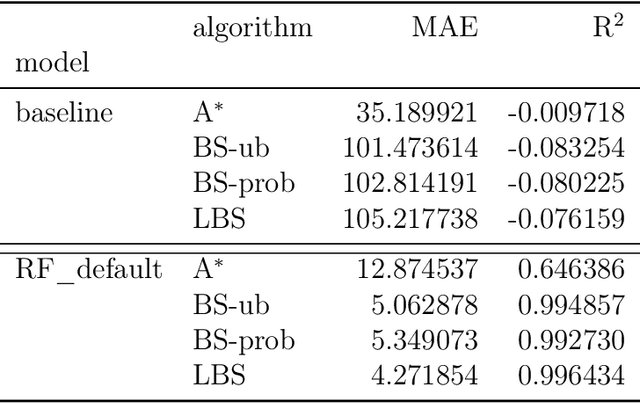
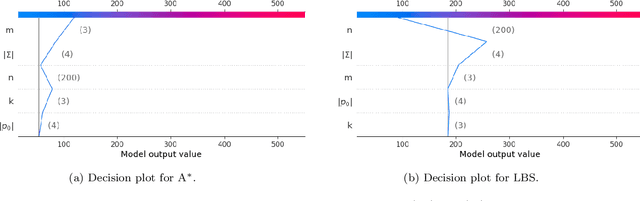
This paper addresses the Restricted Longest Common Subsequence (RLCS) problem, an extension of the well-known Longest Common Subsequence (LCS) problem. This problem has significant applications in bioinformatics, particularly for identifying similarities and discovering mutual patterns and important motifs among DNA, RNA, and protein sequences. Building on recent advancements in solving this problem through a general search framework, this paper introduces two novel heuristic approaches designed to enhance the search process by steering it towards promising regions in the search space. The first heuristic employs a probabilistic model to evaluate partial solutions during the search process. The second heuristic is based on a neural network model trained offline using a genetic algorithm. A key aspect of this approach is extracting problem-specific features of partial solutions and the complete problem instance. An effective hybrid method, referred to as the learning beam search, is developed by combining the trained neural network model with a beam search framework. An important contribution of this paper is found in the generation of real-world instances where scientific abstracts serve as input strings, and a set of frequently occurring academic words from the literature are used as restricted patterns. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed approaches in solving the RLCS problem. Finally, an empirical explainability analysis is applied to the obtained results. In this way, key feature combinations and their respective contributions to the success or failure of the algorithms across different problem types are identified.
Instance Selection for Dynamic Algorithm Configuration with Reinforcement Learning: Improving Generalization
Jul 18, 2024Dynamic Algorithm Configuration (DAC) addresses the challenge of dynamically setting hyperparameters of an algorithm for a diverse set of instances rather than focusing solely on individual tasks. Agents trained with Deep Reinforcement Learning (RL) offer a pathway to solve such settings. However, the limited generalization performance of these agents has significantly hindered the application in DAC. Our hypothesis is that a potential bias in the training instances limits generalization capabilities. We take a step towards mitigating this by selecting a representative subset of training instances to overcome overrepresentation and then retraining the agent on this subset to improve its generalization performance. For constructing the meta-features for the subset selection, we particularly account for the dynamic nature of the RL agent by computing time series features on trajectories of actions and rewards generated by the agent's interaction with the environment. Through empirical evaluations on the Sigmoid and CMA-ES benchmarks from the standard benchmark library for DAC, called DACBench, we discuss the potentials of our selection technique compared to training on the entire instance set. Our results highlight the efficacy of instance selection in refining DAC policies for diverse instance spaces.
A Survey of Meta-features Used for Automated Selection of Algorithms for Black-box Single-objective Continuous Optimization
Jun 08, 2024
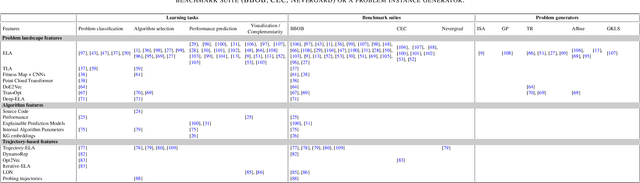
The selection of the most appropriate algorithm to solve a given problem instance, known as algorithm selection, is driven by the potential to capitalize on the complementary performance of different algorithms across sets of problem instances. However, determining the optimal algorithm for an unseen problem instance has been shown to be a challenging task, which has garnered significant attention from researchers in recent years. In this survey, we conduct an overview of the key contributions to algorithm selection in the field of single-objective continuous black-box optimization. We present ongoing work in representation learning of meta-features for optimization problem instances, algorithm instances, and their interactions. We also study machine learning models for automated algorithm selection, configuration, and performance prediction. Through this analysis, we identify gaps in the state of the art, based on which we present ideas for further development of meta-feature representations.
Generalization Ability of Feature-based Performance Prediction Models: A Statistical Analysis across Benchmarks
May 20, 2024



This study examines the generalization ability of algorithm performance prediction models across various benchmark suites. Comparing the statistical similarity between the problem collections with the accuracy of performance prediction models that are based on exploratory landscape analysis features, we observe that there is a positive correlation between these two measures. Specifically, when the high-dimensional feature value distributions between training and testing suites lack statistical significance, the model tends to generalize well, in the sense that the testing errors are in the same range as the training errors. Two experiments validate these findings: one involving the standard benchmark suites, the BBOB and CEC collections, and another using five collections of affine combinations of BBOB problem instances.
Quantifying Individual and Joint Module Impact in Modular Optimization Frameworks
May 20, 2024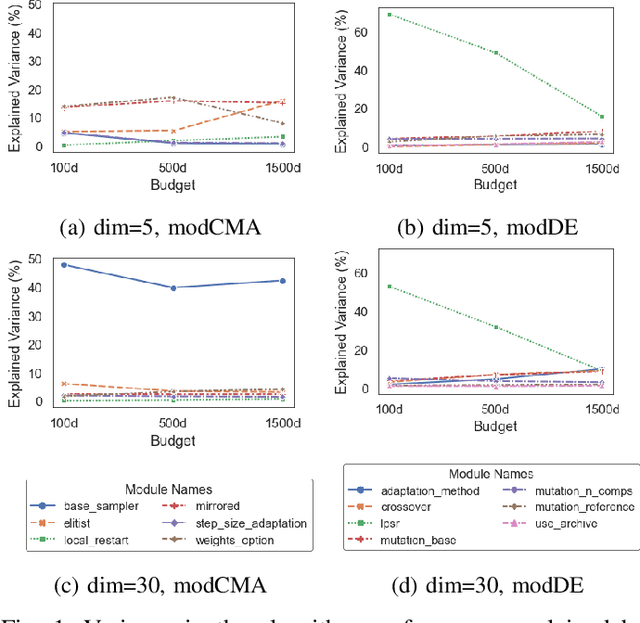



This study explores the influence of modules on the performance of modular optimization frameworks for continuous single-objective black-box optimization. There is an extensive variety of modules to choose from when designing algorithm variants, however, there is a rather limited understanding of how each module individually influences the algorithm performance and how the modules interact with each other when combined. We use the functional ANOVA (f-ANOVA) framework to quantify the influence of individual modules and module combinations for two algorithms, the modular Covariance Matrix Adaptation (modCMA) and the modular Differential Evolution (modDE). We analyze the performance data from 324 modCMA and 576 modDE variants on the BBOB benchmark collection, for two problem dimensions, and three computational budgets. Noteworthy findings include the identification of important modules that strongly influence the performance of modCMA, such as the~\textit{weights\ option} and~\textit{mirrored} modules for low dimensional problems, and the~\textit{base\ sampler} for high dimensional problems. The large individual influence of the~\textit{lpsr} module makes it very important for the performance of modDE, regardless of the problem dimensionality and the computational budget. When comparing modCMA and modDE, modDE undergoes a shift from individual modules being more influential, to module combinations being more influential, while modCMA follows the opposite pattern, with an increase in problem dimensionality and computational budget.
PS-AAS: Portfolio Selection for Automated Algorithm Selection in Black-Box Optimization
Oct 14, 2023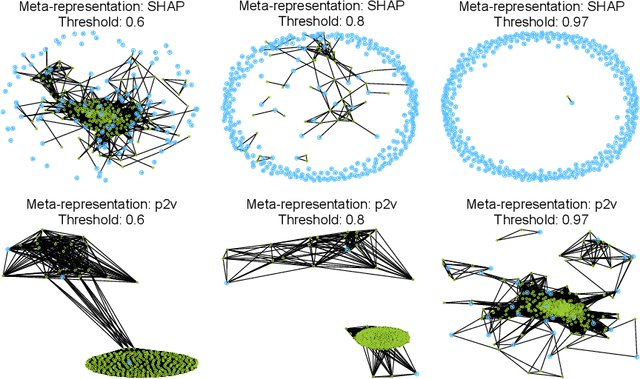
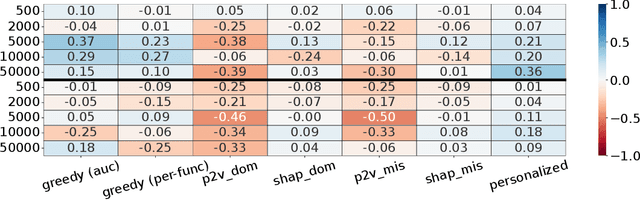
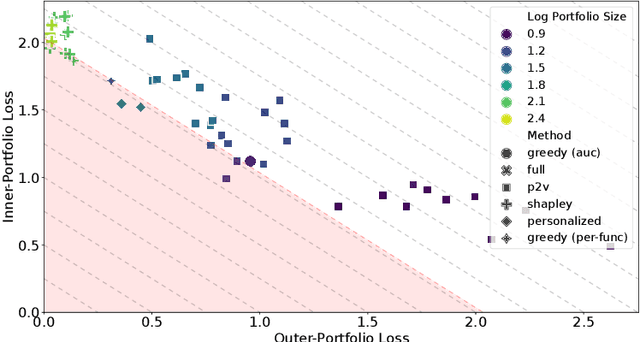
The performance of automated algorithm selection (AAS) strongly depends on the portfolio of algorithms to choose from. Selecting the portfolio is a non-trivial task that requires balancing the trade-off between the higher flexibility of large portfolios with the increased complexity of the AAS task. In practice, probably the most common way to choose the algorithms for the portfolio is a greedy selection of the algorithms that perform well in some reference tasks of interest. We set out in this work to investigate alternative, data-driven portfolio selection techniques. Our proposed method creates algorithm behavior meta-representations, constructs a graph from a set of algorithms based on their meta-representation similarity, and applies a graph algorithm to select a final portfolio of diverse, representative, and non-redundant algorithms. We evaluate two distinct meta-representation techniques (SHAP and performance2vec) for selecting complementary portfolios from a total of 324 different variants of CMA-ES for the task of optimizing the BBOB single-objective problems in dimensionalities 5 and 30 with different cut-off budgets. We test two types of portfolios: one related to overall algorithm behavior and the `personalized' one (related to algorithm behavior per each problem separately). We observe that the approach built on the performance2vec-based representations favors small portfolios with negligible error in the AAS task relative to the virtual best solver from the selected portfolio, whereas the portfolios built from the SHAP-based representations gain from higher flexibility at the cost of decreased performance of the AAS. Across most considered scenarios, personalized portfolios yield comparable or slightly better performance than the classical greedy approach. They outperform the full portfolio in all scenarios.
Algorithm Instance Footprint: Separating Easily Solvable and Challenging Problem Instances
Jun 01, 2023



In black-box optimization, it is essential to understand why an algorithm instance works on a set of problem instances while failing on others and provide explanations of its behavior. We propose a methodology for formulating an algorithm instance footprint that consists of a set of problem instances that are easy to be solved and a set of problem instances that are difficult to be solved, for an algorithm instance. This behavior of the algorithm instance is further linked to the landscape properties of the problem instances to provide explanations of which properties make some problem instances easy or challenging. The proposed methodology uses meta-representations that embed the landscape properties of the problem instances and the performance of the algorithm into the same vector space. These meta-representations are obtained by training a supervised machine learning regression model for algorithm performance prediction and applying model explainability techniques to assess the importance of the landscape features to the performance predictions. Next, deterministic clustering of the meta-representations demonstrates that using them captures algorithm performance across the space and detects regions of poor and good algorithm performance, together with an explanation of which landscape properties are leading to it.