 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Solving the Multiple Variable Gapped Longest Common Subsequence Problem
Apr 19, 2026This paper addresses the Variable Gapped Longest Common Subsequence (VGLCS) problem, a generalization of the classical LCS problem involving flexible gap constraints between consecutive solutions' characters. The problem arises in molecular sequence comparison, where structural distance constraints between residues must be respected, and in time-series analysis where events are required to occur within specified temporal delays. We propose a search framework based on the root-based state graph representation, in which the state space comprises a generally large number of rooted state subgraphs. To cope with the resulting combinatorial explosion, an iterative beam search strategy is employed, dynamically maintaining a global pool of promising candidate root nodes, enabling effective control of diversification across iterations. To exploit the search for high-quality solutions, several known heuristics from the LCS literature are utilized into the standalone beam search procedure. To the best of our knowledge, this is the first comprehensive computational study on the VGLCS problem comprising 320 synthetic instances with up to 10 input sequences and up to 500 characters. Experimental results show robustness of the designed approach over the baseline beam search in comparable runtimes.
GEAKG: Generative Executable Algorithm Knowledge Graphs
Mar 30, 2026In the context of algorithms for problem solving, procedural knowledge -- the know-how of algorithm design and operator composition -- remains implicit in code, lost between runs, and must be re-engineered for each new domain. Knowledge graphs (KGs) have proven effective for organizing declarative knowledge, yet current KG paradigms provide limited support for representing procedural knowledge as executable, learnable graph structures. We introduce \textit{Generative Executable Algorithm Knowledge Graphs} (GEAKG), a class of KGs whose nodes store executable operators, whose edges encode learned composition patterns, and whose traversal generates solutions. A GEAKG is \emph{generative} (topology and operators are synthesized by a Large Language Model), \emph{executable} (every node is runnable code), and \emph{transferable} (learned patterns generalize zero-shot across domains). The framework is domain-agnostic at the engine level: the same three-layer architecture and Ant Colony Optimization (ACO)-based learning engine can be instantiated across domains, parameterized by a pluggable ontology (\texttt{RoleSchema}). Two case studies -- sharing no domain-specific framework code -- provide concrete evidence for this framework hypothesis: (1)~Neural Architecture Search across 70 cross-dataset transfer pairs on two tabular benchmarks, and (2)~Combinatorial Optimization, where knowledge learned on the Traveling Salesman Problem transfers zero-shot to scheduling and assignment domains. Taken together, the results support that algorithmic expertise can be explicitly represented, learned, and transferred as executable knowledge graphs.
Construct, Merge, Solve & Adapt with Reinforcement Learning for the min-max Multiple Traveling Salesman Problem
Feb 27, 2026The Multiple Traveling Salesman Problem (mTSP) extends the Traveling Salesman Problem to m tours that start and end at a common depot and jointly visit all customers exactly once. In the min-max variant, the objective is to minimize the longest tour, reflecting workload balance. We propose a hybrid approach, Construct, Merge, Solve & Adapt with Reinforcement Learning (RL-CMSA), for the symmetric single-depot min-max mTSP. The method iteratively constructs diverse solutions using probabilistic clustering guided by learned pairwise q-values, merges routes into a compact pool, solves a restricted set-covering MILP, and refines solutions via inter-route remove, shift, and swap moves. The q-values are updated by reinforcing city-pair co-occurrences in high-quality solutions, while the pool is adapted through ageing and pruning. This combination of exact optimization and reinforcement-guided construction balances exploration and exploitation. Computational results on random and TSPLIB instances show that RL-CMSA consistently finds (near-)best solutions and outperforms a state-of-the-art hybrid genetic algorithm under comparable time limits, especially as instance size and the number of salesmen increase.
irace-evo: Automatic Algorithm Configuration Extended With LLM-Based Code Evolution
Nov 15, 2025Automatic algorithm configuration tools such as irace efficiently tune parameter values but leave algorithmic code unchanged. This paper introduces a first version of irace-evo, an extension of irace that integrates code evolution through large language models (LLMs) to jointly explore parameter and code spaces. The proposed framework enables multi-language support (e.g., C++, Python), reduces token consumption via progressive context management, and employs the Always-From-Original principle to ensure robust and controlled code evolution. We evaluate irace-evo on the Construct, Merge, Solve & Adapt (CMSA) metaheuristic for the Variable-Sized Bin Packing Problem (VSBPP). Experimental results show that irace-evo can discover new algorithm variants that outperform the state-of-the-art CMSA implementation while maintaining low computational and monetary costs. Notably, irace-evo generates competitive algorithmic improvements using lightweight models (e.g., Claude Haiku 3.5) with a total usage cost under 2 euros. These results demonstrate that coupling automatic configuration with LLM-driven code evolution provides a powerful, cost-efficient avenue for advancing heuristic design and metaheuristic optimization.
Combinatorial Optimization for All: Using LLMs to Aid Non-Experts in Improving Optimization Algorithms
Mar 14, 2025Large Language Models (LLMs) have shown notable potential in code generation for optimization algorithms, unlocking exciting new opportunities. This paper examines how LLMs, rather than creating algorithms from scratch, can improve existing ones without the need for specialized expertise. To explore this potential, we selected 10 baseline optimization algorithms from various domains (metaheuristics, reinforcement learning, deterministic, and exact methods) to solve the classic Travelling Salesman Problem. The results show that our simple methodology often results in LLM-generated algorithm variants that improve over the baseline algorithms in terms of solution quality, reduction in computational time, and simplification of code complexity, all without requiring specialized optimization knowledge or advanced algorithmic implementation skills.
Multi-Agent Systems Powered by Large Language Models: Applications in Swarm Intelligence
Mar 05, 2025This work examines the integration of large language models (LLMs) into multi-agent simulations by replacing the hard-coded programs of agents with LLM-driven prompts. The proposed approach is showcased in the context of two examples of complex systems from the field of swarm intelligence: ant colony foraging and bird flocking. Central to this study is a toolchain that integrates LLMs with the NetLogo simulation platform, leveraging its Python extension to enable communication with GPT-4o via the OpenAI API. This toolchain facilitates prompt-driven behavior generation, allowing agents to respond adaptively to environmental data. For both example applications mentioned above, we employ both structured, rule-based prompts and autonomous, knowledge-driven prompts. Our work demonstrates how this toolchain enables LLMs to study self-organizing processes and induce emergent behaviors within multi-agent environments, paving the way for new approaches to exploring intelligent systems and modeling swarm intelligence inspired by natural phenomena. We provide the code, including simulation files and data at https://github.com/crjimene/swarm_gpt.
Improving Existing Optimization Algorithms with LLMs
Feb 12, 2025

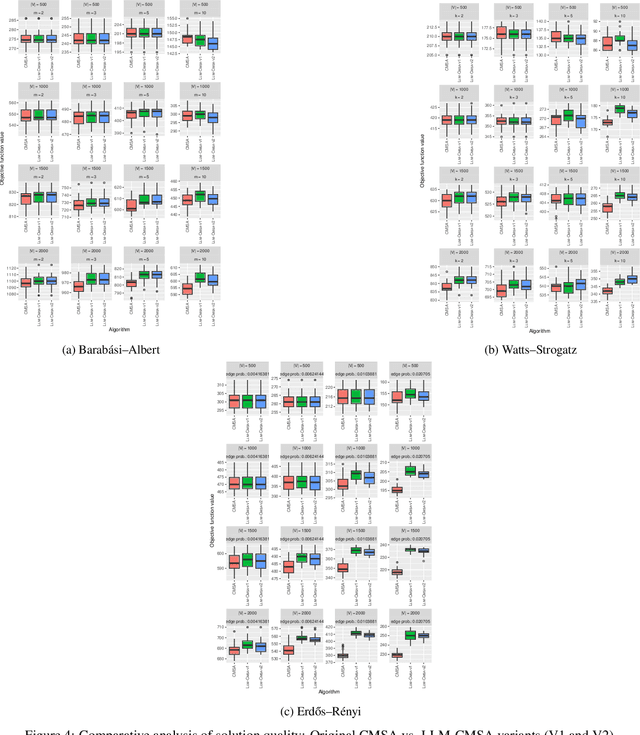

The integration of Large Language Models (LLMs) into optimization has created a powerful synergy, opening exciting research opportunities. This paper investigates how LLMs can enhance existing optimization algorithms. Using their pre-trained knowledge, we demonstrate their ability to propose innovative heuristic variations and implementation strategies. To evaluate this, we applied a non-trivial optimization algorithm, Construct, Merge, Solve and Adapt (CMSA) -- a hybrid metaheuristic for combinatorial optimization problems that incorporates a heuristic in the solution construction phase. Our results show that an alternative heuristic proposed by GPT-4o outperforms the expert-designed heuristic of CMSA, with the performance gap widening on larger and denser graphs. Project URL: https://imp-opt-algo-llms.surge.sh/
VisGraphVar: A Benchmark Generator for Assessing Variability in Graph Analysis Using Large Vision-Language Models
Nov 22, 2024



The fast advancement of Large Vision-Language Models (LVLMs) has shown immense potential. These models are increasingly capable of tackling abstract visual tasks. Geometric structures, particularly graphs with their inherent flexibility and complexity, serve as an excellent benchmark for evaluating these models' predictive capabilities. While human observers can readily identify subtle visual details and perform accurate analyses, our investigation reveals that state-of-the-art LVLMs exhibit consistent limitations in specific visual graph scenarios, especially when confronted with stylistic variations. In response to these challenges, we introduce VisGraphVar (Visual Graph Variability), a customizable benchmark generator able to produce graph images for seven distinct task categories (detection, classification, segmentation, pattern recognition, link prediction, reasoning, matching), designed to systematically evaluate the strengths and limitations of individual LVLMs. We use VisGraphVar to produce 990 graph images and evaluate six LVLMs, employing two distinct prompting strategies, namely zero-shot and chain-of-thought. The findings demonstrate that variations in visual attributes of images (e.g., node labeling and layout) and the deliberate inclusion of visual imperfections, such as overlapping nodes, significantly affect model performance. This research emphasizes the importance of a comprehensive evaluation across graph-related tasks, extending beyond reasoning alone. VisGraphVar offers valuable insights to guide the development of more reliable and robust systems capable of performing advanced visual graph analysis.
A Learning Search Algorithm for the Restricted Longest Common Subsequence Problem
Oct 15, 2024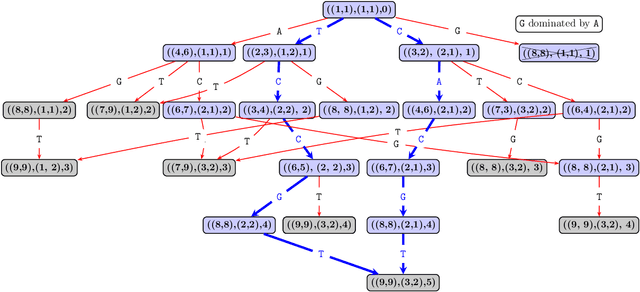
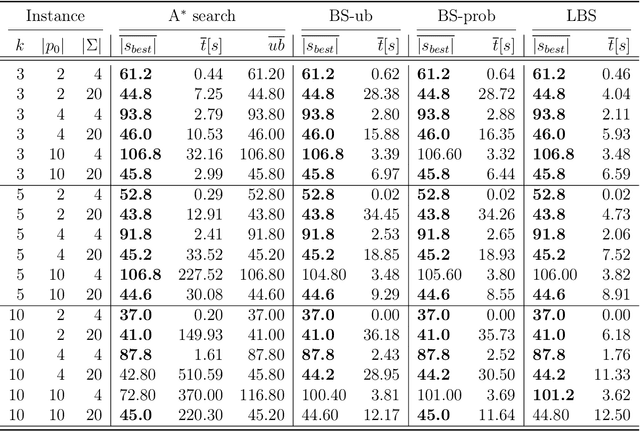
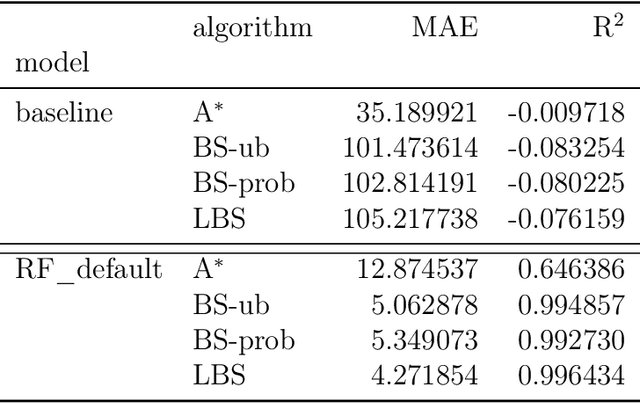
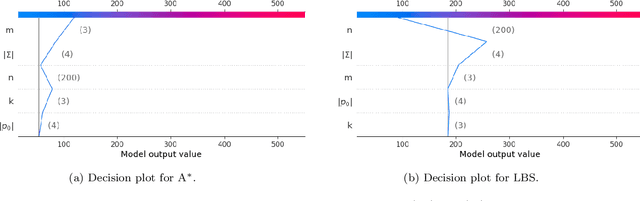
This paper addresses the Restricted Longest Common Subsequence (RLCS) problem, an extension of the well-known Longest Common Subsequence (LCS) problem. This problem has significant applications in bioinformatics, particularly for identifying similarities and discovering mutual patterns and important motifs among DNA, RNA, and protein sequences. Building on recent advancements in solving this problem through a general search framework, this paper introduces two novel heuristic approaches designed to enhance the search process by steering it towards promising regions in the search space. The first heuristic employs a probabilistic model to evaluate partial solutions during the search process. The second heuristic is based on a neural network model trained offline using a genetic algorithm. A key aspect of this approach is extracting problem-specific features of partial solutions and the complete problem instance. An effective hybrid method, referred to as the learning beam search, is developed by combining the trained neural network model with a beam search framework. An important contribution of this paper is found in the generation of real-world instances where scientific abstracts serve as input strings, and a set of frequently occurring academic words from the literature are used as restricted patterns. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed approaches in solving the RLCS problem. Finally, an empirical explainability analysis is applied to the obtained results. In this way, key feature combinations and their respective contributions to the success or failure of the algorithms across different problem types are identified.
Accelerating the k-means++ Algorithm by Using Geometric Information
Aug 23, 2024



In this paper, we propose an acceleration of the exact k-means++ algorithm using geometric information, specifically the Triangle Inequality and additional norm filters, along with a two-step sampling procedure. Our experiments demonstrate that the accelerated version outperforms the standard k-means++ version in terms of the number of visited points and distance calculations, achieving greater speedup as the number of clusters increases. The version utilizing the Triangle Inequality is particularly effective for low-dimensional data, while the additional norm-based filter enhances performance in high-dimensional instances with greater norm variance among points. Additional experiments show the behavior of our algorithms when executed concurrently across multiple jobs and examine how memory performance impacts practical speedup.