 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Constraint Reasoning to Build Graphical Explanations for Mixed-Integer Linear Programming
Jul 17, 2025


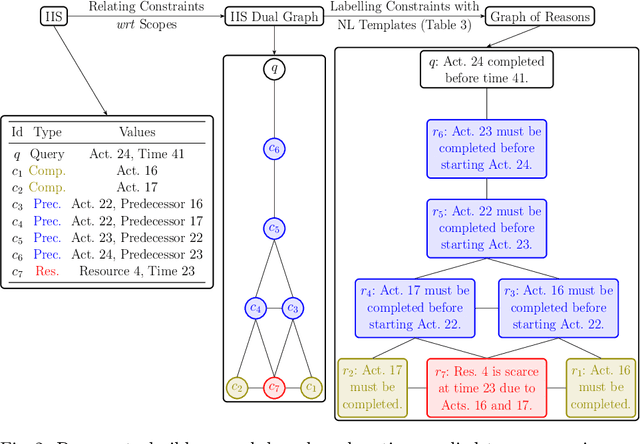
Following the recent push for trustworthy AI, there has been an increasing interest in developing contrastive explanation techniques for optimisation, especially concerning the solution of specific decision-making processes formalised as MILPs. Along these lines, we propose X-MILP, a domain-agnostic approach for building contrastive explanations for MILPs based on constraint reasoning techniques. First, we show how to encode the queries a user makes about the solution of an MILP problem as additional constraints. Then, we determine the reasons that constitute the answer to the user's query by computing the Irreducible Infeasible Subsystem (IIS) of the newly obtained set of constraints. Finally, we represent our explanation as a "graph of reasons" constructed from the IIS, which helps the user understand the structure among the reasons that answer their query. We test our method on instances of well-known optimisation problems to evaluate the empirical hardness of computing explanations.
VisGraphVar: A Benchmark Generator for Assessing Variability in Graph Analysis Using Large Vision-Language Models
Nov 22, 2024



The fast advancement of Large Vision-Language Models (LVLMs) has shown immense potential. These models are increasingly capable of tackling abstract visual tasks. Geometric structures, particularly graphs with their inherent flexibility and complexity, serve as an excellent benchmark for evaluating these models' predictive capabilities. While human observers can readily identify subtle visual details and perform accurate analyses, our investigation reveals that state-of-the-art LVLMs exhibit consistent limitations in specific visual graph scenarios, especially when confronted with stylistic variations. In response to these challenges, we introduce VisGraphVar (Visual Graph Variability), a customizable benchmark generator able to produce graph images for seven distinct task categories (detection, classification, segmentation, pattern recognition, link prediction, reasoning, matching), designed to systematically evaluate the strengths and limitations of individual LVLMs. We use VisGraphVar to produce 990 graph images and evaluate six LVLMs, employing two distinct prompting strategies, namely zero-shot and chain-of-thought. The findings demonstrate that variations in visual attributes of images (e.g., node labeling and layout) and the deliberate inclusion of visual imperfections, such as overlapping nodes, significantly affect model performance. This research emphasizes the importance of a comprehensive evaluation across graph-related tasks, extending beyond reasoning alone. VisGraphVar offers valuable insights to guide the development of more reliable and robust systems capable of performing advanced visual graph analysis.
Metaheuristics and Large Language Models Join Forces: Towards an Integrated Optimization Approach
May 28, 2024



Since the rise of Large Language Models (LLMs) a couple of years ago, researchers in metaheuristics (MHs) have wondered how to use their power in a beneficial way within their algorithms. This paper introduces a novel approach that leverages LLMs as pattern recognition tools to improve MHs. The resulting hybrid method, tested in the context of a social network-based combinatorial optimization problem, outperforms existing state-of-the-art approaches that combine machine learning with MHs regarding the obtained solution quality. By carefully designing prompts, we demonstrate that the output obtained from LLMs can be used as problem knowledge, leading to improved results. Lastly, we acknowledge LLMs' potential drawbacks and limitations and consider it essential to examine them to advance this type of research further.
An attention model for the formation of collectives in real-world domains
Apr 30, 2022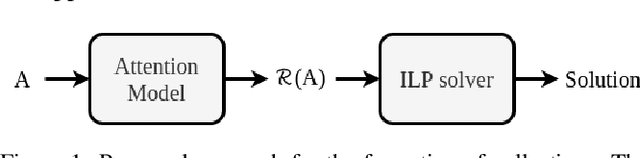
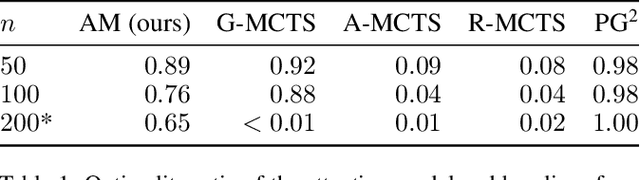
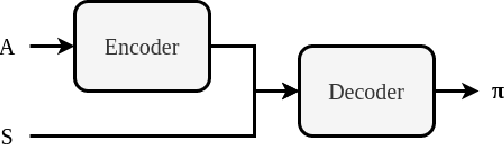

We consider the problem of forming collectives of agents for real-world applications aligned with Sustainable Development Goals (e.g., shared mobility, cooperative learning). We propose a general approach for the formation of collectives based on a novel combination of an attention model and an integer linear program (ILP). In more detail, we propose an attention encoder-decoder model that transforms a collective formation instance to a weighted set packing problem, which is then solved by an ILP. Results on two real-world domains (i.e., ridesharing and team formation for cooperative learning) show that our approach provides solutions that are comparable (in terms of quality) to the ones produced by state-of-the-art approaches specific to each domain. Moreover, our solution outperforms the most recent general approach for forming collectives based on Monte Carlo tree search.
A Concise Function Representation for Faster Exact MPE and Constrained Optimisation in Graphical Models
Aug 09, 2021



We propose a novel concise function representation for graphical models, a central theoretical framework that provides the basis for many reasoning tasks. We then show how we exploit our concise representation based on deterministic finite state automata within Bucket Elimination (BE), a general approach based on the concept of variable elimination that accommodates many inference and optimisation tasks such as most probable explanation and constrained optimisation. We denote our version of BE as FABE. By using our concise representation within FABE, we dramatically improve the performance of BE in terms of runtime and memory requirements. Results on standard benchmarks obtained using an established experimental methodology show that FABE often outperforms the best available approach (RBFAOO), leading to significant runtime improvements (up to 2 orders of magnitude in our tests).
Predicting Requests in Large-Scale Online P2P Ridesharing
Sep 07, 2020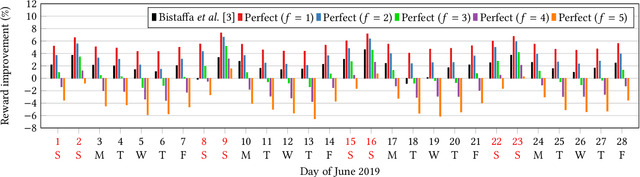
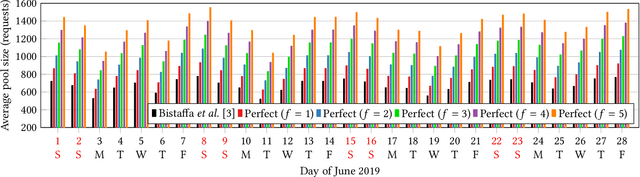

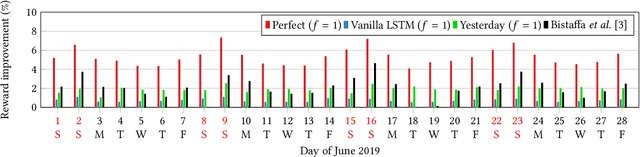
Peer-to-peer ridesharing (P2P-RS) enables people to arrange one-time rides with their own private cars, without the involvement of professional drivers. It is a prominent collective intelligence application producing significant benefits both for individuals (reduced costs) and for the entire community (reduced pollution and traffic), as we showed in a recent publication where we proposed an online approximate solution algorithm for large-scale P2P-RS. In this paper we tackle the fundamental question of assessing the benefit of predicting ridesharing requests in the context of P2P-RS optimisation. Results on a public real-world show that, by employing a perfect predictor, the total reward can be improved by 5.27% with a forecast horizon of 1 minute. On the other hand, a vanilla long short-term memory neural network cannot improve upon a baseline predictor that simply replicates the previous day's requests, whilst achieving an almost-double accuracy.
Synergistic Team Composition: A Computational Approach to Foster Diversity in Teams
Sep 26, 2019
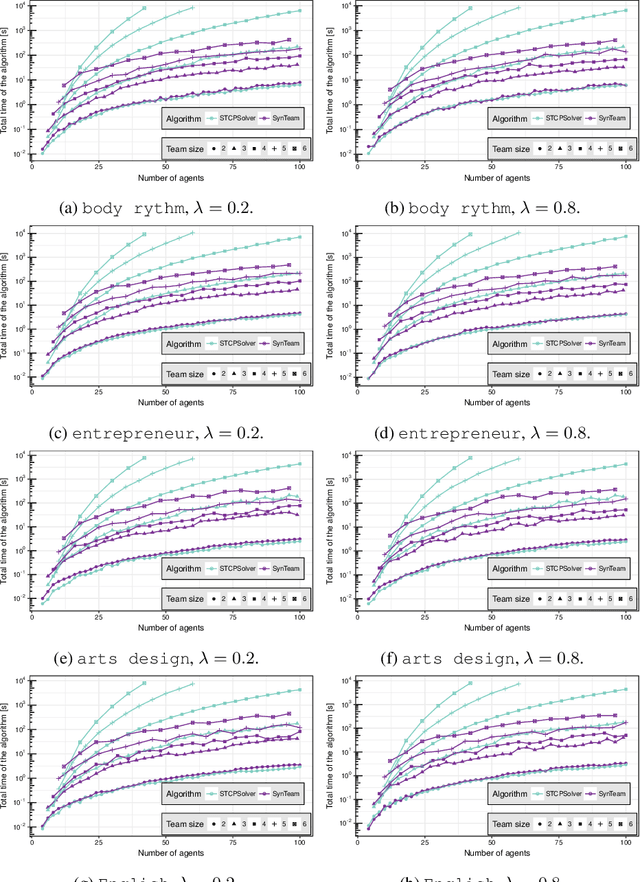

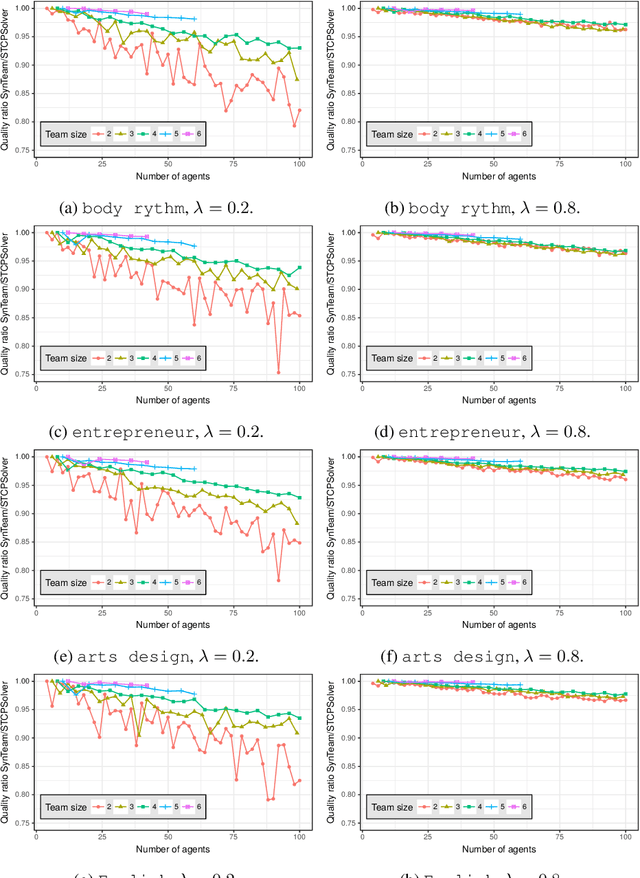
Co-operative learning in heterogeneous teams refers to learning methods in which teams are organised both to accomplish academic tasks and for individuals to gain knowledge. Competencies, personality and the gender of team members are key factors that influence team performance. Here, we introduce a team composition problem, the so-called synergistic team composition problem (STCP), which incorporates such key factors when arranging teams. Thus, the goal of the STCP is to partition a set of individuals into a set of synergistic teams: teams that are diverse in personality and gender and whose members cover all required competencies to complete a task. Furthermore, the STCP requires that all teams are balanced in that they are expected to exhibit similar performances when completing the task. We propose two efficient algorithms to solve the STCP. Our first algorithm is based on a linear programming formulation and is appropriate to solve small instances of the problem. Our second algorithm is an anytime heuristic that is effective for large instances of the STCP. Finally, we thoroughly study the computational properties of both algorithms in an educational context when grouping students in a classroom into teams using actual-world data.
* Accepted version
Algorithms for Graph-Constrained Coalition Formation in the Real World
Dec 13, 2016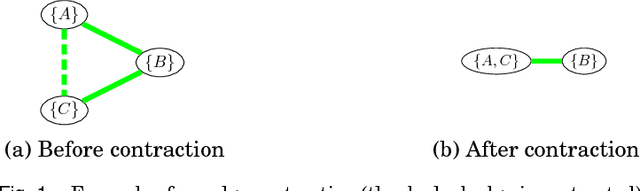

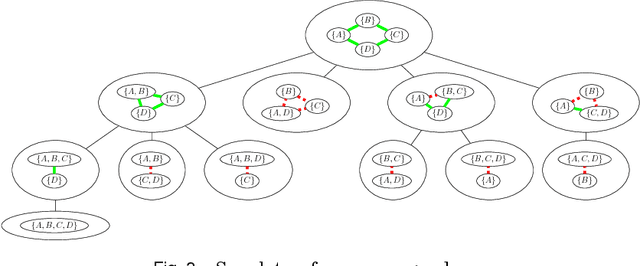
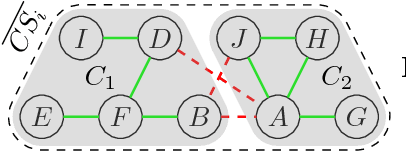
Coalition formation typically involves the coming together of multiple, heterogeneous, agents to achieve both their individual and collective goals. In this paper, we focus on a special case of coalition formation known as Graph-Constrained Coalition Formation (GCCF) whereby a network connecting the agents constrains the formation of coalitions. We focus on this type of problem given that in many real-world applications, agents may be connected by a communication network or only trust certain peers in their social network. We propose a novel representation of this problem based on the concept of edge contraction, which allows us to model the search space induced by the GCCF problem as a rooted tree. Then, we propose an anytime solution algorithm (CFSS), which is particularly efficient when applied to a general class of characteristic functions called $m+a$ functions. Moreover, we show how CFSS can be efficiently parallelised to solve GCCF using a non-redundant partition of the search space. We benchmark CFSS on both synthetic and realistic scenarios, using a real-world dataset consisting of the energy consumption of a large number of households in the UK. Our results show that, in the best case, the serial version of CFSS is 4 orders of magnitude faster than the state of the art, while the parallel version is 9.44 times faster than the serial version on a 12-core machine. Moreover, CFSS is the first approach to provide anytime approximate solutions with quality guarantees for very large systems of agents (i.e., with more than 2700 agents).
* Accepted for publication, cite as "in press"