 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Scene Transfer for PointGoal Navigation via Privileged Sensor Guided Contrastive Learning
Jun 03, 2026We propose a sensor-guided adaptive contrastive learning framework for visual representation learning in PointGoal navigation. During training, privileged LiDAR sensing guides the contrastive objective through a geometry-aware similarity metric and adaptive temperature scaling, encouraging visual embeddings to capture navigation-relevant structure rather than scene-specific appearance. The resulting encoder is pretrained independently, frozen, and used as the perceptual backbone for reinforcement learning, decoupling representation learning from policy optimization. We further introduce a cross-stage domain mismatch between representation pretraining and policy learning to suppress environment-specific shortcuts and promote reliance on task-relevant features. Extensive experiments in high-fidelity simulation demonstrate that our approach significantly improves policy-level scene transfer across diverse indoor and outdoor environments. At deployment, the agent relies only on monocular RGB observations together with standard task-related inputs such as goal position and proprioceptive signals, without access to LiDAR or other privileged sensors. Our method outperforms large pretrained vision models and standard contrastive baselines under severe appearance and semantic shifts. We also release a multimodal dataset to support future research on privileged-guided visual representation learning for navigation. The code is available at:
Benchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
Mar 31, 2026We propose Question-Asking Navigation (QAsk-Nav), the first reproducible benchmark for Collaborative Instance Object Navigation (CoIN) that enables an explicit, separate assessment of embodied navigation and collaborative question asking. CoIN tasks an embodied agent with reaching a target specified in free-form natural language under partial observability, using only egocentric visual observations and interactive natural-language dialogue with a human, where the dialogue can help to resolve ambiguity among visually similar object instances. Existing CoIN benchmarks are primarily focused on navigation success and offer no support for consistent evaluation of collaborative interaction. To address this limitation, QAsk-Nav provides (i) a lightweight question-asking protocol scored independently of navigation, (ii) an enhanced navigation protocol with realistic, diverse, high-quality target descriptions, and (iii) an open-source dataset, that includes 28,000 quality-checked reasoning and question-asking traces for training and analysis of interactive capabilities of CoIN models. Using the proposed QAsk-Nav benchmark, we develop Light-CoNav, a lightweight unified model for collaborative navigation that is 3x smaller and 70x faster than existing modular methods, while outperforming state-of-the-art CoIN approaches in generalization to unseen objects and environments. Project page at https://benchmarking-interaction.github.io/
Sample-Efficient Neurosymbolic Deep Reinforcement Learning
Jan 06, 2026Reinforcement Learning (RL) is a well-established framework for sequential decision-making in complex environments. However, state-of-the-art Deep RL (DRL) algorithms typically require large training datasets and often struggle to generalize beyond small-scale training scenarios, even within standard benchmarks. We propose a neuro-symbolic DRL approach that integrates background symbolic knowledge to improve sample efficiency and generalization to more challenging, unseen tasks. Partial policies defined for simple domain instances, where high performance is easily attained, are transferred as useful priors to accelerate learning in more complex settings and avoid tuning DRL parameters from scratch. To do so, partial policies are represented as logical rules, and online reasoning is performed to guide the training process through two mechanisms: (i) biasing the action distribution during exploration, and (ii) rescaling Q-values during exploitation. This neuro-symbolic integration enhances interpretability and trustworthiness while accelerating convergence, particularly in sparse-reward environments and tasks with long planning horizons. We empirically validate our methodology on challenging variants of gridworld environments, both in the fully observable and partially observable setting. We show improved performance over a state-of-the-art reward machine baseline.
On the Probabilistic Learnability of Compact Neural Network Preimage Bounds
Nov 10, 2025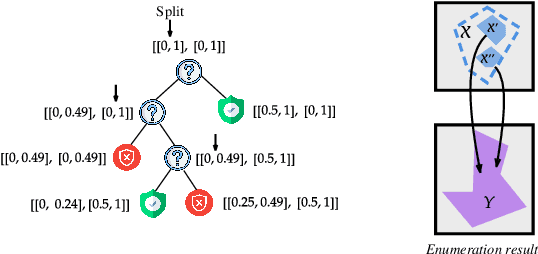
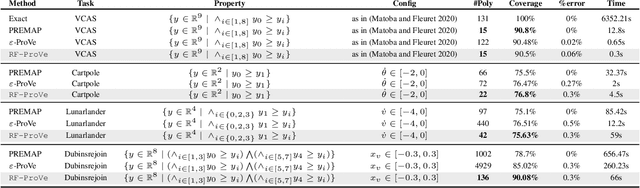
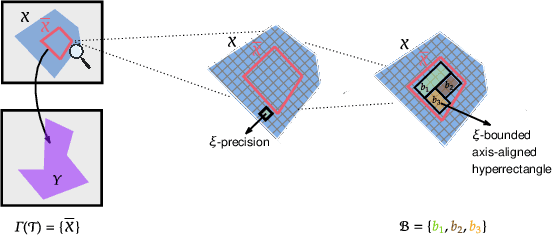
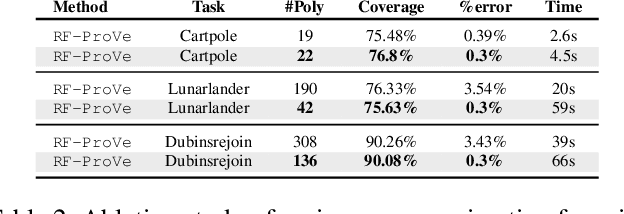
Although recent provable methods have been developed to compute preimage bounds for neural networks, their scalability is fundamentally limited by the #P-hardness of the problem. In this work, we adopt a novel probabilistic perspective, aiming to deliver solutions with high-confidence guarantees and bounded error. To this end, we investigate the potential of bootstrap-based and randomized approaches that are capable of capturing complex patterns in high-dimensional spaces, including input regions where a given output property holds. In detail, we introduce $\textbf{R}$andom $\textbf{F}$orest $\textbf{Pro}$perty $\textbf{Ve}$rifier ($\texttt{RF-ProVe}$), a method that exploits an ensemble of randomized decision trees to generate candidate input regions satisfying a desired output property and refines them through active resampling. Our theoretical derivations offer formal statistical guarantees on region purity and global coverage, providing a practical, scalable solution for computing compact preimage approximations in cases where exact solvers fail to scale.
Advancing Neural Network Verification through Hierarchical Safety Abstract Interpretation
May 08, 2025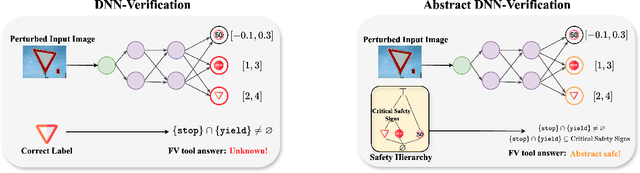
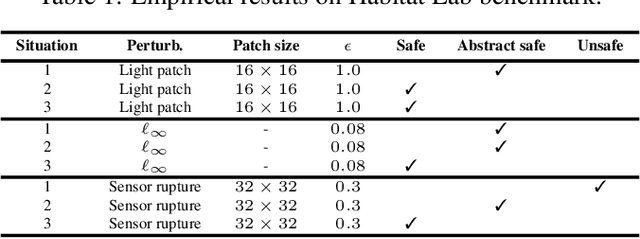
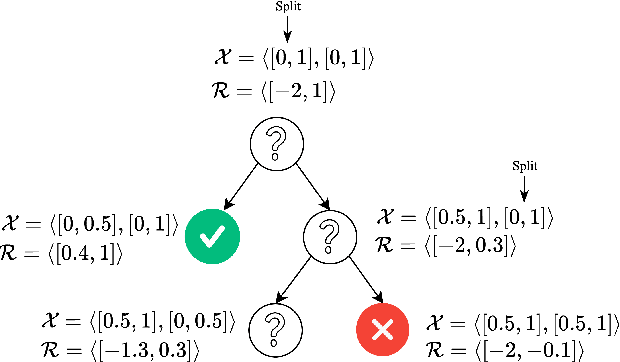
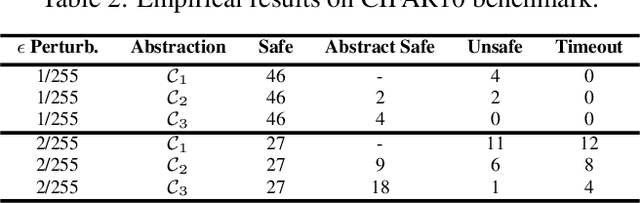
Traditional methods for formal verification (FV) of deep neural networks (DNNs) are constrained by a binary encoding of safety properties, where a model is classified as either safe or unsafe (robust or not robust). This binary encoding fails to capture the nuanced safety levels within a model, often resulting in either overly restrictive or too permissive requirements. In this paper, we introduce a novel problem formulation called Abstract DNN-Verification, which verifies a hierarchical structure of unsafe outputs, providing a more granular analysis of the safety aspect for a given DNN. Crucially, by leveraging abstract interpretation and reasoning about output reachable sets, our approach enables assessing multiple safety levels during the FV process, requiring the same (in the worst case) or even potentially less computational effort than the traditional binary verification approach. Specifically, we demonstrate how this formulation allows rank adversarial inputs according to their abstract safety level violation, offering a more detailed evaluation of the model's safety and robustness. Our contributions include a theoretical exploration of the relationship between our novel abstract safety formulation and existing approaches that employ abstract interpretation for robustness verification, complexity analysis of the novel problem introduced, and an empirical evaluation considering both a complex deep reinforcement learning task (based on Habitat 3.0) and standard DNN-Verification benchmarks.
Learning Symbolic Persistent Macro-Actions for POMDP Solving Over Time
May 06, 2025This paper proposes an integration of temporal logical reasoning and Partially Observable Markov Decision Processes (POMDPs) to achieve interpretable decision-making under uncertainty with macro-actions. Our method leverages a fragment of Linear Temporal Logic (LTL) based on Event Calculus (EC) to generate \emph{persistent} (i.e., constant) macro-actions, which guide Monte Carlo Tree Search (MCTS)-based POMDP solvers over a time horizon, significantly reducing inference time while ensuring robust performance. Such macro-actions are learnt via Inductive Logic Programming (ILP) from a few traces of execution (belief-action pairs), thus eliminating the need for manually designed heuristics and requiring only the specification of the POMDP transition model. In the Pocman and Rocksample benchmark scenarios, our learned macro-actions demonstrate increased expressiveness and generality when compared to time-independent heuristics, indeed offering substantial computational efficiency improvements.
Designing Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning Navigation
Apr 30, 2025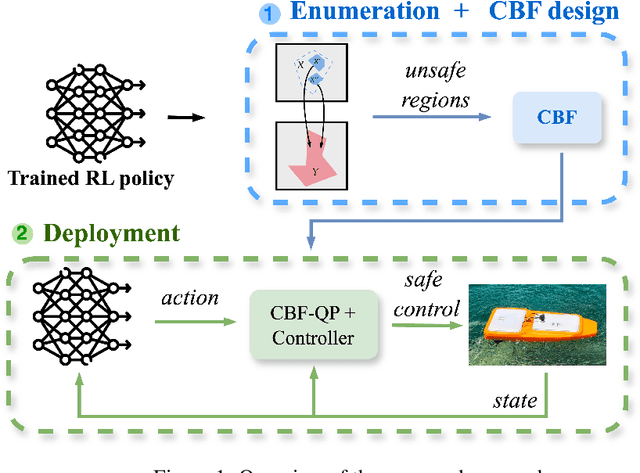


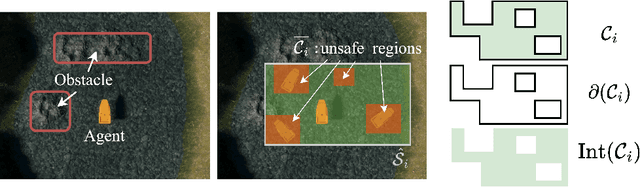
Achieving safe autonomous navigation systems is critical for deploying robots in dynamic and uncertain real-world environments. In this paper, we propose a hierarchical control framework leveraging neural network verification techniques to design control barrier functions (CBFs) and policy correction mechanisms that ensure safe reinforcement learning navigation policies. Our approach relies on probabilistic enumeration to identify unsafe regions of operation, which are then used to construct a safe CBF-based control layer applicable to arbitrary policies. We validate our framework both in simulation and on a real robot, using a standard mobile robot benchmark and a highly dynamic aquatic environmental monitoring task. These experiments demonstrate the ability of the proposed solution to correct unsafe actions while preserving efficient navigation behavior. Our results show the promise of developing hierarchical verification-based systems to enable safe and robust navigation behaviors in complex scenarios.
Depth-Constrained ASV Navigation with Deep RL and Limited Sensing
Apr 25, 2025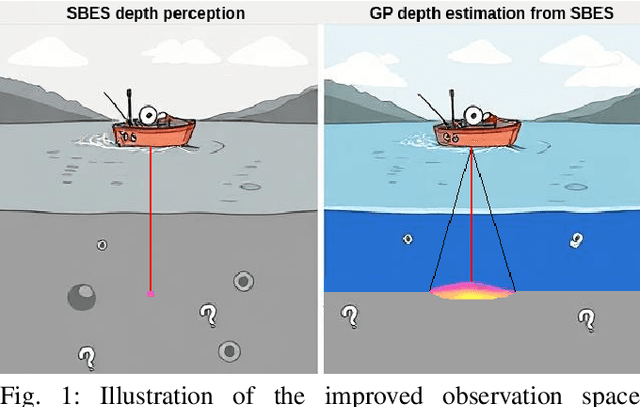

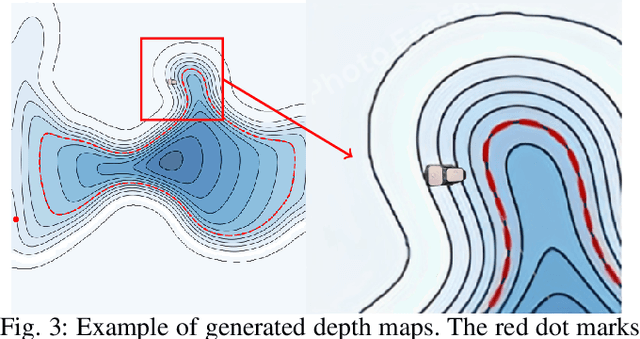
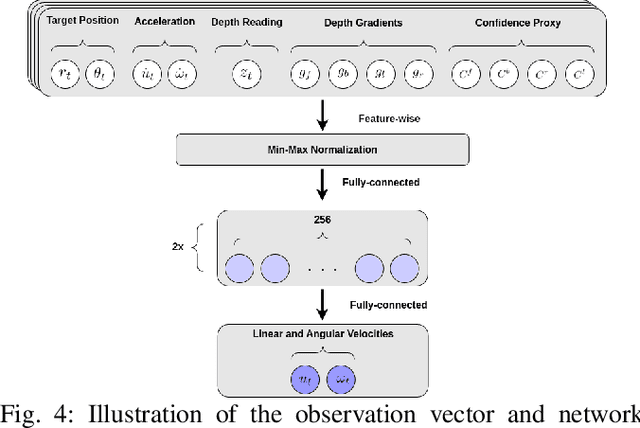
Autonomous Surface Vehicles (ASVs) play a crucial role in maritime operations, yet their navigation in shallow-water environments remains challenging due to dynamic disturbances and depth constraints. Traditional navigation strategies struggle with limited sensor information, making safe and efficient operation difficult. In this paper, we propose a reinforcement learning (RL) framework for ASV navigation under depth constraints, where the vehicle must reach a target while avoiding unsafe areas with only a single depth measurement per timestep from a downward-facing Single Beam Echosounder (SBES). To enhance environmental awareness, we integrate Gaussian Process (GP) regression into the RL framework, enabling the agent to progressively estimate a bathymetric depth map from sparse sonar readings. This approach improves decision-making by providing a richer representation of the environment. Furthermore, we demonstrate effective sim-to-real transfer, ensuring that trained policies generalize well to real-world aquatic conditions. Experimental results validate our method's capability to improve ASV navigation performance while maintaining safety in challenging shallow-water environments.
Seldonian Reinforcement Learning for Ad Hoc Teamwork
Mar 05, 2025
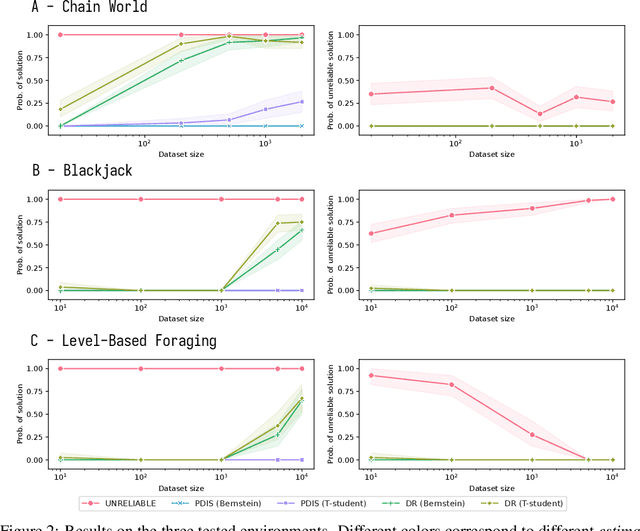
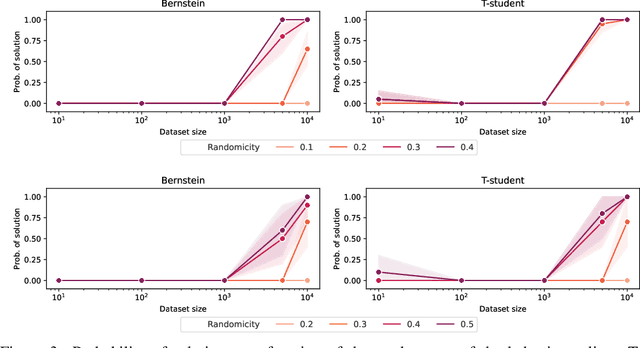
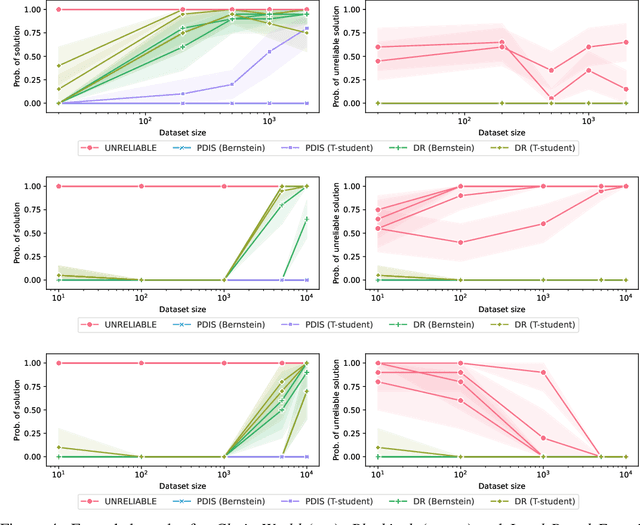
Most offline RL algorithms return optimal policies but do not provide statistical guarantees on undesirable behaviors. This could generate reliability issues in safety-critical applications, such as in some multiagent domains where agents, and possibly humans, need to interact to reach their goals without harming each other. In this work, we propose a novel offline RL approach, inspired by Seldonian optimization, which returns policies with good performance and statistically guaranteed properties with respect to predefined undesirable behaviors. In particular, our focus is on Ad Hoc Teamwork settings, where agents must collaborate with new teammates without prior coordination. Our method requires only a pre-collected dataset, a set of candidate policies for our agent, and a specification about the possible policies followed by the other players -- it does not require further interactions, training, or assumptions on the type and architecture of the policies. We test our algorithm in Ad Hoc Teamwork problems and show that it consistently finds reliable policies while improving sample efficiency with respect to standard ML baselines.
Monte Carlo Tree Search with Velocity Obstacles for safe and efficient motion planning in dynamic environments
Jan 16, 2025Online motion planning is a challenging problem for intelligent robots moving in dense environments with dynamic obstacles, e.g., crowds. In this work, we propose a novel approach for optimal and safe online motion planning with minimal information about dynamic obstacles. Specifically, our approach requires only the current position of the obstacles and their maximum speed, but it does not need any information about their exact trajectories or dynamic model. The proposed methodology combines Monte Carlo Tree Search (MCTS), for online optimal planning via model simulations, with Velocity Obstacles (VO), for obstacle avoidance. We perform experiments in a cluttered simulated environment with walls, and up to 40 dynamic obstacles moving with random velocities and directions. With an ablation study, we show the key contribution of VO in scaling up the efficiency of MCTS, selecting the safest and most rewarding actions in the tree of simulations. Moreover, we show the superiority of our methodology with respect to state-of-the-art planners, including Non-linear Model Predictive Control (NMPC), in terms of improved collision rate, computational and task performance.