 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Tree Search with Neural Network Guidance for Lane-Free Autonomous Driving
Jan 14, 2026Lane-free traffic environments allow vehicles to better harness the lateral capacity of the road without being restricted to lane-keeping, thereby increasing the traffic flow rates. As such, we have a distinct and more challenging setting for autonomous driving. In this work, we consider a Monte-Carlo Tree Search (MCTS) planning approach for single-agent autonomous driving in lane-free traffic, where the associated Markov Decision Process we formulate is influenced from existing approaches tied to reinforcement learning frameworks. In addition, MCTS is equipped with a pre-trained neural network (NN) that guides the selection phase. This procedure incorporates the predictive capabilities of NNs for a more informed tree search process under computational constraints. In our experimental evaluation, we consider metrics that address both safety (through collision rates) and efficacy (through measured speed). Then, we examine: (a) the influence of isotropic state information for vehicles in a lane-free environment, resulting in nudging behaviour--vehicles' policy reacts due to the presence of faster tailing ones, (b) the acceleration of performance for the NN-guided variant of MCTS, and (c) the trade-off between computational resources and solution quality.
Strategic Opponent Modeling with Graph Neural Networks, Deep Reinforcement Learning and Probabilistic Topic Modeling
Nov 14, 2025

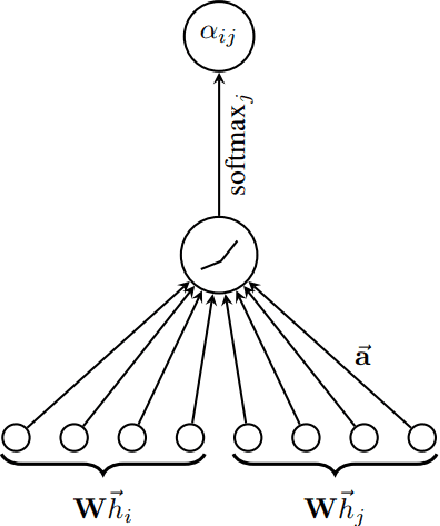

This paper provides a comprehensive review of mainly Graph Neural Networks, Deep Reinforcement Learning, and Probabilistic Topic Modeling methods with a focus on their potential incorporation in strategic multiagent settings. We draw interest in (i) Machine Learning methods currently utilized for uncovering unknown model structures adaptable to the task of strategic opponent modeling, and (ii) the integration of these methods with Game Theoretic concepts that avoid relying on assumptions often invalid in real-world scenarios, such as the Common Prior Assumption (CPA) and the Self-Interest Hypothesis (SIH). We analyze the ability to handle uncertainty and heterogeneity, two characteristics that are very common in real-world application cases, as well as scalability. As a potential answer to effectively modeling relationships and interactions in multiagent settings, we champion the use of Graph Neural Networks (GNN). Such approaches are designed to operate upon graph-structured data, and have been shown to be a very powerful tool for performing tasks such as node classification and link prediction. Next, we review the domain of Reinforcement Learning (RL), and in particular that of Multiagent Deep Reinforcement Learning (MADRL). Following, we describe existing relevant game theoretic solution concepts and consider properties such as fairness and stability. Our review comes complete with a note on the literature that utilizes PTM in domains other than that of document analysis and classification. The capability of PTM to estimate unknown underlying distributions can help with tackling heterogeneity and unknown agent beliefs. Finally, we identify certain open challenges specifically, the need to (i) fit non-stationary environments, (ii) balance the degrees of stability and adaptation, (iii) tackle uncertainty and heterogeneity, (iv) guarantee scalability and solution tractability.
Going Beyond Expert Performance via Deep Implicit Imitation Reinforcement Learning
Nov 05, 2025Imitation learning traditionally requires complete state-action demonstrations from optimal or near-optimal experts. These requirements severely limit practical applicability, as many real-world scenarios provide only state observations without corresponding actions and expert performance is often suboptimal. In this paper we introduce a deep implicit imitation reinforcement learning framework that addresses both limitations by combining deep reinforcement learning with implicit imitation learning from observation-only datasets. Our main algorithm, Deep Implicit Imitation Q-Network (DIIQN), employs an action inference mechanism that reconstructs expert actions through online exploration and integrates a dynamic confidence mechanism that adaptively balances expert-guided and self-directed learning. This enables the agent to leverage expert guidance for accelerated training while maintaining capacity to surpass suboptimal expert performance. We further extend our framework with a Heterogeneous Actions DIIQN (HA-DIIQN) algorithm to tackle scenarios where expert and agent possess different action sets, a challenge previously unaddressed in the implicit imitation learning literature. HA-DIIQN introduces an infeasibility detection mechanism and a bridging procedure identifying alternative pathways connecting agent capabilities to expert guidance when direct action replication is impossible. Our experimental results demonstrate that DIIQN achieves up to 130% higher episodic returns compared to standard DQN, while consistently outperforming existing implicit imitation methods that cannot exceed expert performance. In heterogeneous action settings, HA-DIIQN learns up to 64% faster than baselines, leveraging expert datasets unusable by conventional approaches. Extensive parameter sensitivity analysis reveals the framework's robustness across varying dataset sizes and hyperparameter configurations.
Imitation Learning in the Deep Learning Era: A Novel Taxonomy and Recent Advances
Nov 05, 2025Imitation learning (IL) enables agents to acquire skills by observing and replicating the behavior of one or multiple experts. In recent years, advances in deep learning have significantly expanded the capabilities and scalability of imitation learning across a range of domains, where expert data can range from full state-action trajectories to partial observations or unlabeled sequences. Alongside this growth, novel approaches have emerged, with new methodologies being developed to address longstanding challenges such as generalization, covariate shift, and demonstration quality. In this survey, we review the latest advances in imitation learning research, highlighting recent trends, methodological innovations, and practical applications. We propose a novel taxonomy that is distinct from existing categorizations to better reflect the current state of the IL research stratum and its trends. Throughout the survey, we critically examine the strengths, limitations, and evaluation practices of representative works, and we outline key challenges and open directions for future research.
Seldonian Reinforcement Learning for Ad Hoc Teamwork
Mar 05, 2025
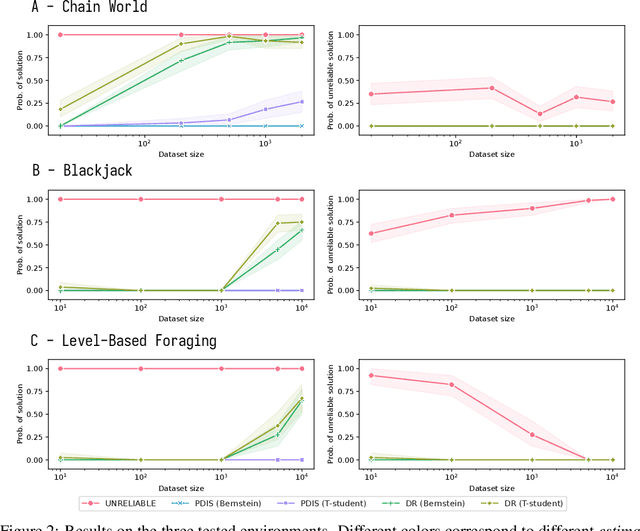
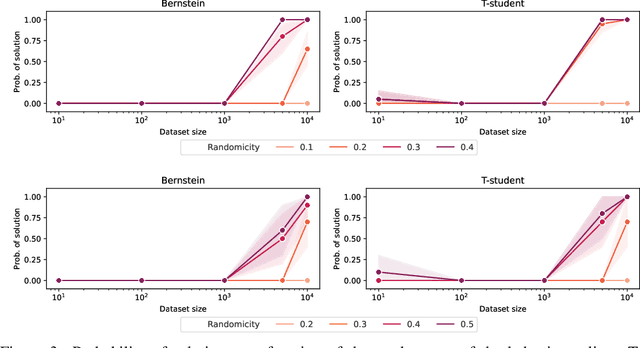
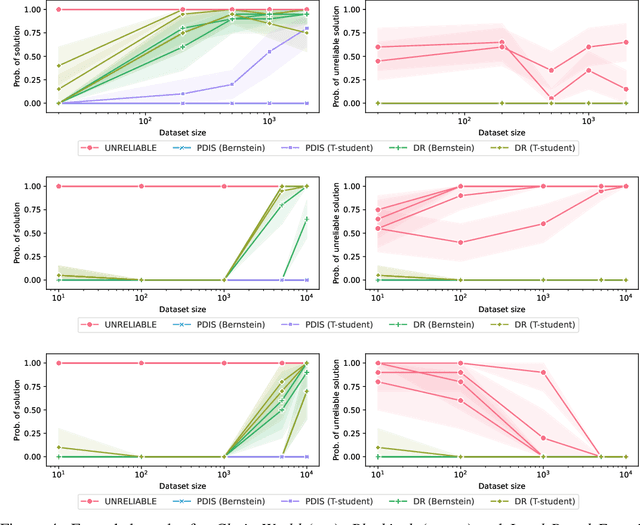
Most offline RL algorithms return optimal policies but do not provide statistical guarantees on undesirable behaviors. This could generate reliability issues in safety-critical applications, such as in some multiagent domains where agents, and possibly humans, need to interact to reach their goals without harming each other. In this work, we propose a novel offline RL approach, inspired by Seldonian optimization, which returns policies with good performance and statistically guaranteed properties with respect to predefined undesirable behaviors. In particular, our focus is on Ad Hoc Teamwork settings, where agents must collaborate with new teammates without prior coordination. Our method requires only a pre-collected dataset, a set of candidate policies for our agent, and a specification about the possible policies followed by the other players -- it does not require further interactions, training, or assumptions on the type and architecture of the policies. We test our algorithm in Ad Hoc Teamwork problems and show that it consistently finds reliable policies while improving sample efficiency with respect to standard ML baselines.
Conditional Max-Sum for Asynchronous Multiagent Decision Making
Feb 18, 2025In this paper we present a novel approach for multiagent decision making in dynamic environments based on Factor Graphs and the Max-Sum algorithm, considering asynchronous variable reassignments and distributed message-passing among agents. Motivated by the challenging domain of lane-free traffic where automated vehicles can communicate and coordinate as agents, we propose a more realistic communication framework for Factor Graph formulations that satisfies the above-mentioned restrictions, along with Conditional Max-Sum: an extension of Max-Sum with a revised message-passing process that is better suited for asynchronous settings. The overall application in lane-free traffic can be viewed as a hybrid system where the Factor Graph formulation undertakes the strategic decision making of vehicles, that of desired lateral alignment in a coordinated manner; and acts on top of a rule-based method we devise that provides a structured representation of the lane-free environment for the factors, while also handling the underlying control of vehicles regarding core operations and safety. Our experimental evaluation showcases the capabilities of the proposed framework in problems with intense coordination needs when compared to a domain-specific baseline without communication, and an increased adeptness of Conditional Max-Sum with respect to the standard algorithm.
A Novel Multiagent Flexibility Aggregation Framework
Jul 17, 2023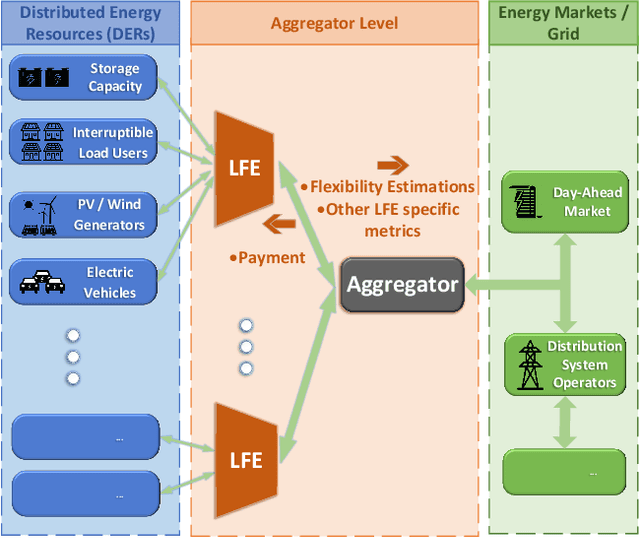

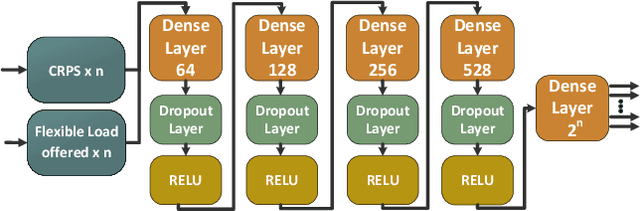
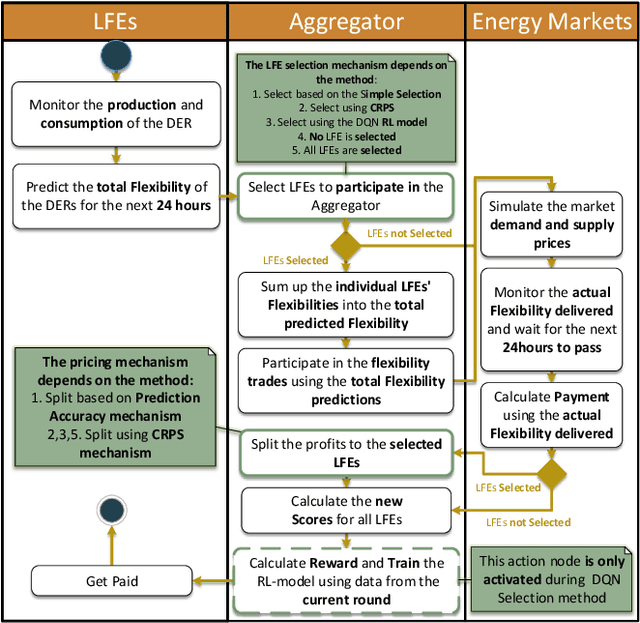
The increasing number of Distributed Energy Resources (DERs) in the emerging Smart Grid, has created an imminent need for intelligent multiagent frameworks able to utilize these assets efficiently. In this paper, we propose a novel DER aggregation framework, encompassing a multiagent architecture and various types of mechanisms for the effective management and efficient integration of DERs in the Grid. One critical component of our architecture is the Local Flexibility Estimators (LFEs) agents, which are key for offloading the Aggregator from serious or resource-intensive responsibilities -- such as addressing privacy concerns and predicting the accuracy of DER statements regarding their offered demand response services. The proposed framework allows the formation of efficient LFE cooperatives. To this end, we developed and deployed a variety of cooperative member selection mechanisms, including (a) scoring rules, and (b) (deep) reinforcement learning. We use data from the well-known PowerTAC simulator to systematically evaluate our framework. Our experiments verify its effectiveness for incorporating heterogeneous DERs into the Grid in an efficient manner. In particular, when using the well-known probabilistic prediction accuracy-incentivizing CRPS scoring rule as a selection mechanism, our framework results in increased average payments for participants, when compared with traditional commercial aggregators.
Optimising Long-Term Outcomes using Real-World Fluent Objectives: An Application to Football
Feb 18, 2021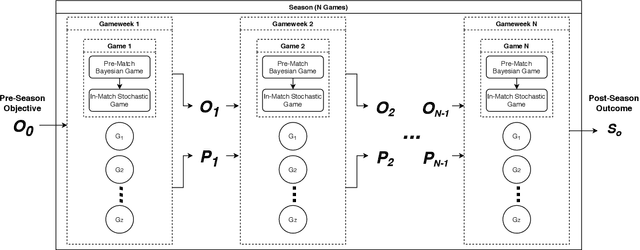
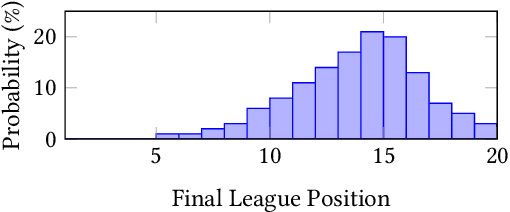
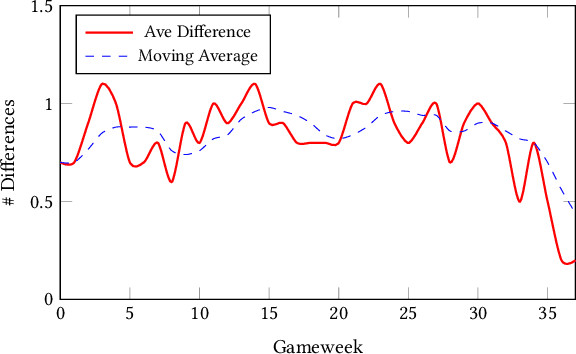
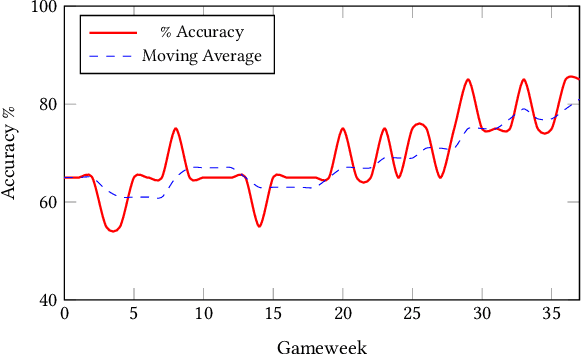
In this paper, we present a novel approach for optimising long-term tactical and strategic decision-making in football (soccer) by encapsulating events in a league environment across a given time frame. We model the teams' objectives for a season and track how these evolve as games unfold to give a fluent objective that can aid in decision-making games. We develop Markov chain Monte Carlo and deep learning-based algorithms that make use of the fluent objectives in order to learn from prior games and other games in the environment and increase the teams' long-term performance. Simulations of our approach using real-world datasets from 760 matches shows that by using optimised tactics with our fluent objective and prior games, we can on average increase teams mean expected finishing distribution in the league by up to 35.6%.
Optimising Game Tactics for Football
Mar 23, 2020
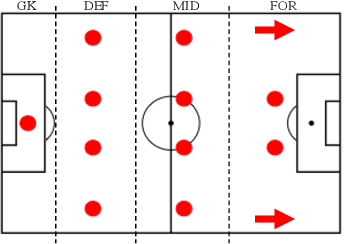
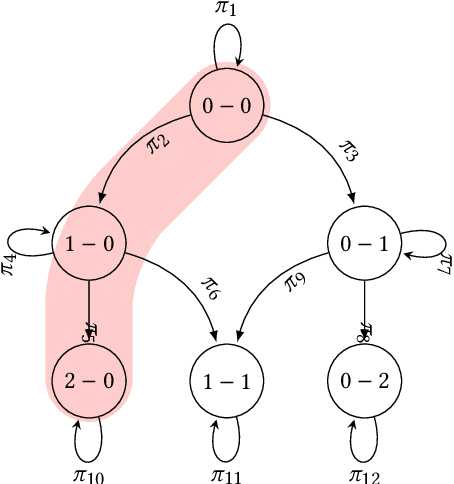

In this paper we present a novel approach to optimise tactical and strategic decision making in football (soccer). We model the game of football as a multi-stage game which is made up from a Bayesian game to model the pre-match decisions and a stochastic game to model the in-match state transitions and decisions. Using this formulation, we propose a method to predict the probability of game outcomes and the payoffs of team actions. Building upon this, we develop algorithms to optimise team formation and in-game tactics with different objectives. Empirical evaluation of our approach on real-world datasets from 760 matches shows that by using optimised tactics from our Bayesian and stochastic games, we can increase a team chances of winning by up to 16.1\% and 3.4\% respectively.