 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
Mar 31, 2026We propose Question-Asking Navigation (QAsk-Nav), the first reproducible benchmark for Collaborative Instance Object Navigation (CoIN) that enables an explicit, separate assessment of embodied navigation and collaborative question asking. CoIN tasks an embodied agent with reaching a target specified in free-form natural language under partial observability, using only egocentric visual observations and interactive natural-language dialogue with a human, where the dialogue can help to resolve ambiguity among visually similar object instances. Existing CoIN benchmarks are primarily focused on navigation success and offer no support for consistent evaluation of collaborative interaction. To address this limitation, QAsk-Nav provides (i) a lightweight question-asking protocol scored independently of navigation, (ii) an enhanced navigation protocol with realistic, diverse, high-quality target descriptions, and (iii) an open-source dataset, that includes 28,000 quality-checked reasoning and question-asking traces for training and analysis of interactive capabilities of CoIN models. Using the proposed QAsk-Nav benchmark, we develop Light-CoNav, a lightweight unified model for collaborative navigation that is 3x smaller and 70x faster than existing modular methods, while outperforming state-of-the-art CoIN approaches in generalization to unseen objects and environments. Project page at https://benchmarking-interaction.github.io/
Seldonian Reinforcement Learning for Ad Hoc Teamwork
Mar 05, 2025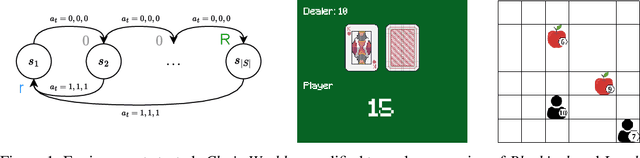
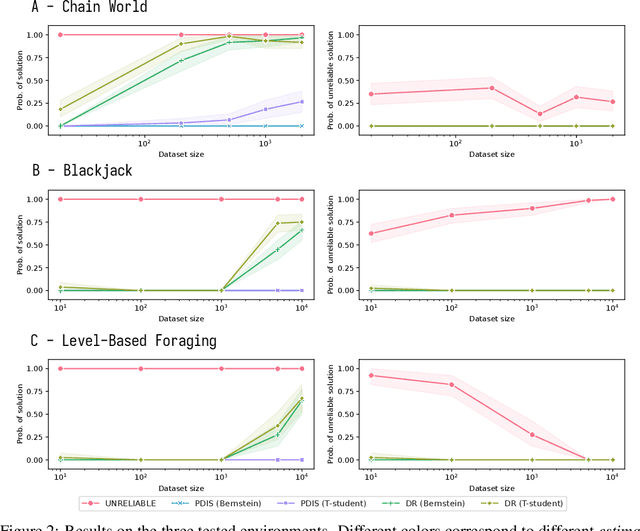
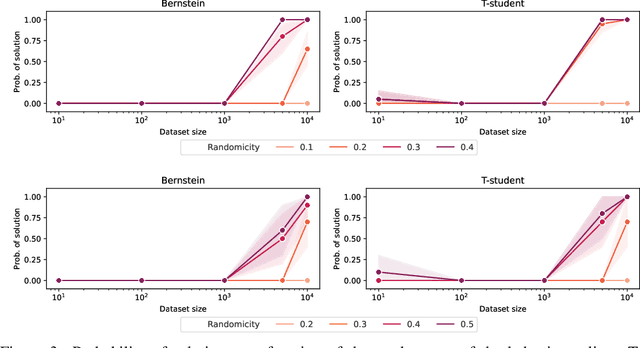
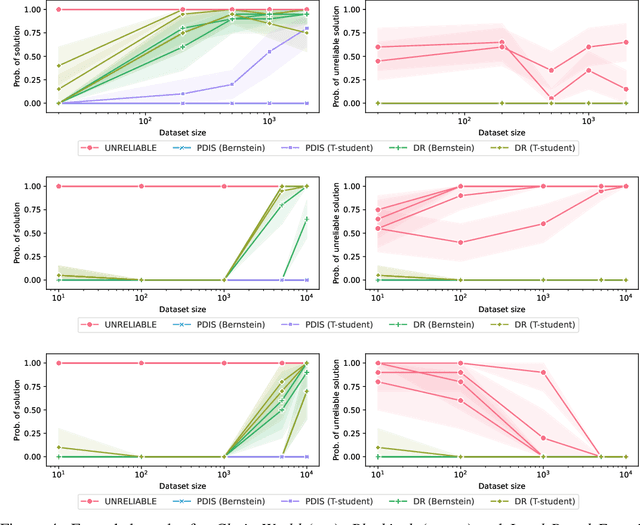
Most offline RL algorithms return optimal policies but do not provide statistical guarantees on undesirable behaviors. This could generate reliability issues in safety-critical applications, such as in some multiagent domains where agents, and possibly humans, need to interact to reach their goals without harming each other. In this work, we propose a novel offline RL approach, inspired by Seldonian optimization, which returns policies with good performance and statistically guaranteed properties with respect to predefined undesirable behaviors. In particular, our focus is on Ad Hoc Teamwork settings, where agents must collaborate with new teammates without prior coordination. Our method requires only a pre-collected dataset, a set of candidate policies for our agent, and a specification about the possible policies followed by the other players -- it does not require further interactions, training, or assumptions on the type and architecture of the policies. We test our algorithm in Ad Hoc Teamwork problems and show that it consistently finds reliable policies while improving sample efficiency with respect to standard ML baselines.
Monte Carlo Tree Search with Velocity Obstacles for safe and efficient motion planning in dynamic environments
Jan 16, 2025Online motion planning is a challenging problem for intelligent robots moving in dense environments with dynamic obstacles, e.g., crowds. In this work, we propose a novel approach for optimal and safe online motion planning with minimal information about dynamic obstacles. Specifically, our approach requires only the current position of the obstacles and their maximum speed, but it does not need any information about their exact trajectories or dynamic model. The proposed methodology combines Monte Carlo Tree Search (MCTS), for online optimal planning via model simulations, with Velocity Obstacles (VO), for obstacle avoidance. We perform experiments in a cluttered simulated environment with walls, and up to 40 dynamic obstacles moving with random velocities and directions. With an ablation study, we show the key contribution of VO in scaling up the efficiency of MCTS, selecting the safest and most rewarding actions in the tree of simulations. Moreover, we show the superiority of our methodology with respect to state-of-the-art planners, including Non-linear Model Predictive Control (NMPC), in terms of improved collision rate, computational and task performance.
Collaborative Instance Navigation: Leveraging Agent Self-Dialogue to Minimize User Input
Dec 02, 2024Existing embodied instance goal navigation tasks, driven by natural language, assume human users to provide complete and nuanced instance descriptions prior to the navigation, which can be impractical in the real world as human instructions might be brief and ambiguous. To bridge this gap, we propose a new task, Collaborative Instance Navigation (CoIN), with dynamic agent-human interaction during navigation to actively resolve uncertainties about the target instance in natural, template-free, open-ended dialogues. To address CoIN, we propose a novel method, Agent-user Interaction with UncerTainty Awareness (AIUTA), leveraging the perception capability of Vision Language Models (VLMs) and the capability of Large Language Models (LLMs). First, upon object detection, a Self-Questioner model initiates a self-dialogue to obtain a complete and accurate observation description, while a novel uncertainty estimation technique mitigates inaccurate VLM perception. Then, an Interaction Trigger module determines whether to ask a question to the user, continue or halt navigation, minimizing user input. For evaluation, we introduce CoIN-Bench, a benchmark supporting both real and simulated humans. AIUTA achieves competitive performance in instance navigation against state-of-the-art methods, demonstrating great flexibility in handling user inputs.
I2EDL: Interactive Instruction Error Detection and Localization
Jun 07, 2024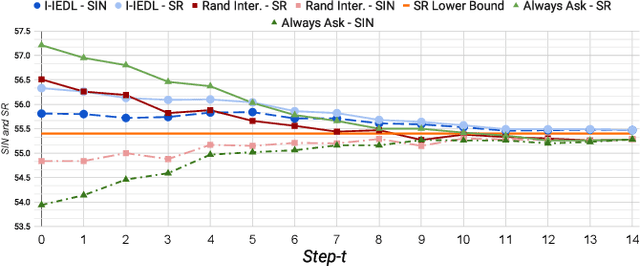
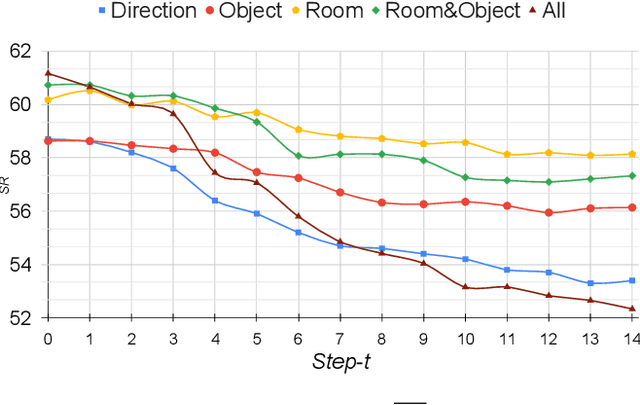

In the Vision-and-Language Navigation in Continuous Environments (VLN-CE) task, the human user guides an autonomous agent to reach a target goal via a series of low-level actions following a textual instruction in natural language. However, most existing methods do not address the likely case where users may make mistakes when providing such instruction (e.g. "turn left" instead of "turn right"). In this work, we address a novel task of Interactive VLN in Continuous Environments (IVLN-CE), which allows the agent to interact with the user during the VLN-CE navigation to verify any doubts regarding the instruction errors. We propose an Interactive Instruction Error Detector and Localizer (I2EDL) that triggers the user-agent interaction upon the detection of instruction errors during the navigation. We leverage a pre-trained module to detect instruction errors and pinpoint them in the instruction by cross-referencing the textual input and past observations. In such way, the agent is able to query the user for a timely correction, without demanding the user's cognitive load, as we locate the probable errors to a precise part of the instruction. We evaluate the proposed I2EDL on a dataset of instructions containing errors, and further devise a novel metric, the Success weighted by Interaction Number (SIN), to reflect both the navigation performance and the interaction effectiveness. We show how the proposed method can ask focused requests for corrections to the user, which in turn increases the navigation success, while minimizing the interactions.
Mind the Error! Detection and Localization of Instruction Errors in Vision-and-Language Navigation
Mar 15, 2024



Vision-and-Language Navigation in Continuous Environments (VLN-CE) is one of the most intuitive yet challenging embodied AI tasks. Agents are tasked to navigate towards a target goal by executing a set of low-level actions, following a series of natural language instructions. All VLN-CE methods in the literature assume that language instructions are exact. However, in practice, instructions given by humans can contain errors when describing a spatial environment due to inaccurate memory or confusion. Current VLN-CE benchmarks do not address this scenario, making the state-of-the-art methods in VLN-CE fragile in the presence of erroneous instructions from human users. For the first time, we propose a novel benchmark dataset that introduces various types of instruction errors considering potential human causes. This benchmark provides valuable insight into the robustness of VLN systems in continuous environments. We observe a noticeable performance drop (up to -25%) in Success Rate when evaluating the state-of-the-art VLN-CE methods on our benchmark. Moreover, we formally define the task of Instruction Error Detection and Localization, and establish an evaluation protocol on top of our benchmark dataset. We also propose an effective method, based on a cross-modal transformer architecture, that achieves the best performance in error detection and localization, compared to baselines. Surprisingly, our proposed method has revealed errors in the validation set of the two commonly used datasets for VLN-CE, i.e., R2R-CE and RxR-CE, demonstrating the utility of our technique in other tasks. Code and dataset will be made available upon acceptance at https://intelligolabs.github.io/R2RIE-CE
Learning Logic Specifications for Policy Guidance in POMDPs: an Inductive Logic Programming Approach
Feb 29, 2024



Partially Observable Markov Decision Processes (POMDPs) are a powerful framework for planning under uncertainty. They allow to model state uncertainty as a belief probability distribution. Approximate solvers based on Monte Carlo sampling show great success to relax the computational demand and perform online planning. However, scaling to complex realistic domains with many actions and long planning horizons is still a major challenge, and a key point to achieve good performance is guiding the action-selection process with domain-dependent policy heuristics which are tailored for the specific application domain. We propose to learn high-quality heuristics from POMDP traces of executions generated by any solver. We convert the belief-action pairs to a logical semantics, and exploit data- and time-efficient Inductive Logic Programming (ILP) to generate interpretable belief-based policy specifications, which are then used as online heuristics. We evaluate thoroughly our methodology on two notoriously challenging POMDP problems, involving large action spaces and long planning horizons, namely, rocksample and pocman. Considering different state-of-the-art online POMDP solvers, including POMCP, DESPOT and AdaOPS, we show that learned heuristics expressed in Answer Set Programming (ASP) yield performance superior to neural networks and similar to optimal handcrafted task-specific heuristics within lower computational time. Moreover, they well generalize to more challenging scenarios not experienced in the training phase (e.g., increasing rocks and grid size in rocksample, incrementing the size of the map and the aggressivity of ghosts in pocman).
Learning Logic Specifications for Soft Policy Guidance in POMCP
Mar 16, 2023Partially Observable Monte Carlo Planning (POMCP) is an efficient solver for Partially Observable Markov Decision Processes (POMDPs). It allows scaling to large state spaces by computing an approximation of the optimal policy locally and online, using a Monte Carlo Tree Search based strategy. However, POMCP suffers from sparse reward function, namely, rewards achieved only when the final goal is reached, particularly in environments with large state spaces and long horizons. Recently, logic specifications have been integrated into POMCP to guide exploration and to satisfy safety requirements. However, such policy-related rules require manual definition by domain experts, especially in real-world scenarios. In this paper, we use inductive logic programming to learn logic specifications from traces of POMCP executions, i.e., sets of belief-action pairs generated by the planner. Specifically, we learn rules expressed in the paradigm of answer set programming. We then integrate them inside POMCP to provide soft policy bias toward promising actions. In the context of two benchmark scenarios, rocksample and battery, we show that the integration of learned rules from small task instances can improve performance with fewer Monte Carlo simulations and in larger task instances. We make our modified version of POMCP publicly available at https://github.com/GiuMaz/pomcp_clingo.git.
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023



We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
POMP++: Pomcp-based Active Visual Search in unknown indoor environments
Jul 02, 2021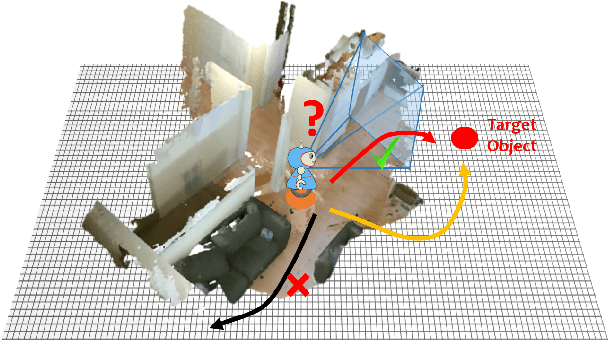
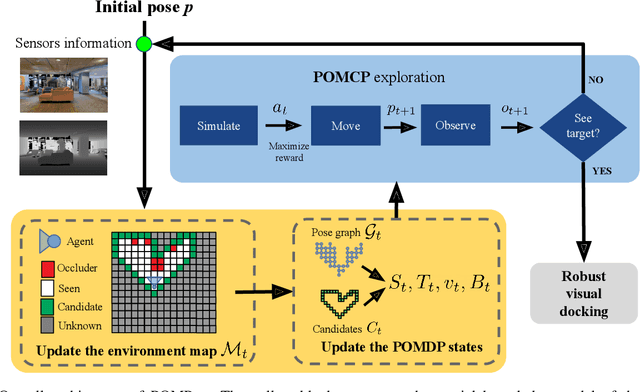
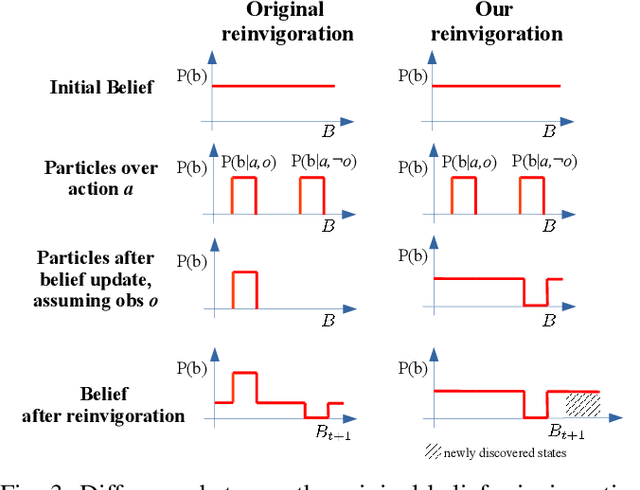

In this paper we focus on the problem of learning online an optimal policy for Active Visual Search (AVS) of objects in unknown indoor environments. We propose POMP++, a planning strategy that introduces a novel formulation on top of the classic Partially Observable Monte Carlo Planning (POMCP) framework, to allow training-free online policy learning in unknown environments. We present a new belief reinvigoration strategy which allows to use POMCP with a dynamically growing state space to address the online generation of the floor map. We evaluate our method on two public benchmark datasets, AVD that is acquired by real robotic platforms and Habitat ObjectNav that is rendered from real 3D scene scans, achieving the best success rate with an improvement of >10% over the state-of-the-art methods.