 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Opponent Modeling with Graph Neural Networks, Deep Reinforcement Learning and Probabilistic Topic Modeling
Nov 14, 2025

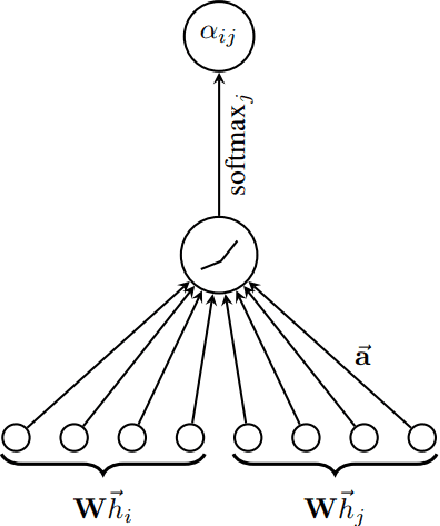

This paper provides a comprehensive review of mainly Graph Neural Networks, Deep Reinforcement Learning, and Probabilistic Topic Modeling methods with a focus on their potential incorporation in strategic multiagent settings. We draw interest in (i) Machine Learning methods currently utilized for uncovering unknown model structures adaptable to the task of strategic opponent modeling, and (ii) the integration of these methods with Game Theoretic concepts that avoid relying on assumptions often invalid in real-world scenarios, such as the Common Prior Assumption (CPA) and the Self-Interest Hypothesis (SIH). We analyze the ability to handle uncertainty and heterogeneity, two characteristics that are very common in real-world application cases, as well as scalability. As a potential answer to effectively modeling relationships and interactions in multiagent settings, we champion the use of Graph Neural Networks (GNN). Such approaches are designed to operate upon graph-structured data, and have been shown to be a very powerful tool for performing tasks such as node classification and link prediction. Next, we review the domain of Reinforcement Learning (RL), and in particular that of Multiagent Deep Reinforcement Learning (MADRL). Following, we describe existing relevant game theoretic solution concepts and consider properties such as fairness and stability. Our review comes complete with a note on the literature that utilizes PTM in domains other than that of document analysis and classification. The capability of PTM to estimate unknown underlying distributions can help with tackling heterogeneity and unknown agent beliefs. Finally, we identify certain open challenges specifically, the need to (i) fit non-stationary environments, (ii) balance the degrees of stability and adaptation, (iii) tackle uncertainty and heterogeneity, (iv) guarantee scalability and solution tractability.
Seldonian Reinforcement Learning for Ad Hoc Teamwork
Mar 05, 2025
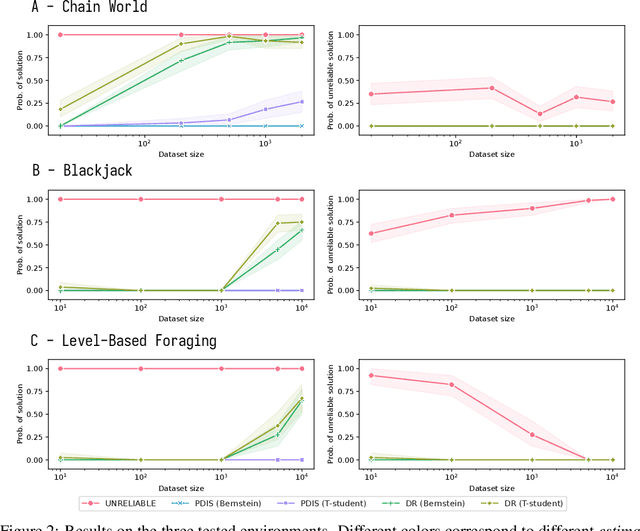
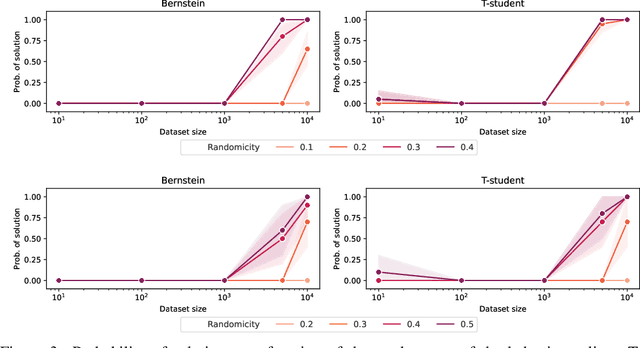
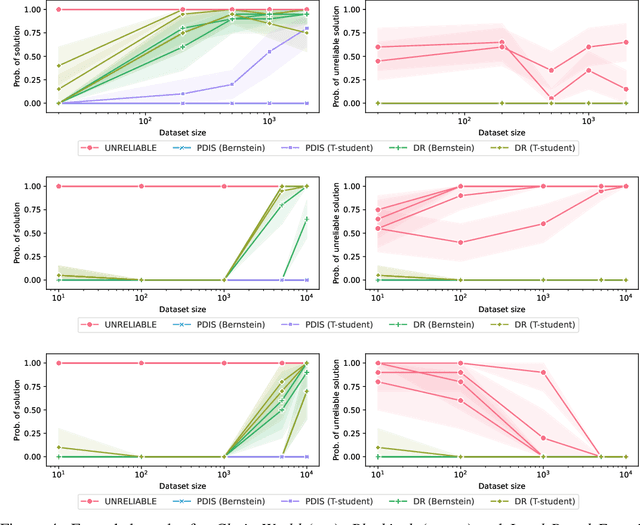
Most offline RL algorithms return optimal policies but do not provide statistical guarantees on undesirable behaviors. This could generate reliability issues in safety-critical applications, such as in some multiagent domains where agents, and possibly humans, need to interact to reach their goals without harming each other. In this work, we propose a novel offline RL approach, inspired by Seldonian optimization, which returns policies with good performance and statistically guaranteed properties with respect to predefined undesirable behaviors. In particular, our focus is on Ad Hoc Teamwork settings, where agents must collaborate with new teammates without prior coordination. Our method requires only a pre-collected dataset, a set of candidate policies for our agent, and a specification about the possible policies followed by the other players -- it does not require further interactions, training, or assumptions on the type and architecture of the policies. We test our algorithm in Ad Hoc Teamwork problems and show that it consistently finds reliable policies while improving sample efficiency with respect to standard ML baselines.