 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Logic Specifications for Soft Policy Guidance in POMCP
Mar 16, 2023Partially Observable Monte Carlo Planning (POMCP) is an efficient solver for Partially Observable Markov Decision Processes (POMDPs). It allows scaling to large state spaces by computing an approximation of the optimal policy locally and online, using a Monte Carlo Tree Search based strategy. However, POMCP suffers from sparse reward function, namely, rewards achieved only when the final goal is reached, particularly in environments with large state spaces and long horizons. Recently, logic specifications have been integrated into POMCP to guide exploration and to satisfy safety requirements. However, such policy-related rules require manual definition by domain experts, especially in real-world scenarios. In this paper, we use inductive logic programming to learn logic specifications from traces of POMCP executions, i.e., sets of belief-action pairs generated by the planner. Specifically, we learn rules expressed in the paradigm of answer set programming. We then integrate them inside POMCP to provide soft policy bias toward promising actions. In the context of two benchmark scenarios, rocksample and battery, we show that the integration of learned rules from small task instances can improve performance with fewer Monte Carlo simulations and in larger task instances. We make our modified version of POMCP publicly available at https://github.com/GiuMaz/pomcp_clingo.git.
Rule-based Shielding for Partially Observable Monte-Carlo Planning
Apr 28, 2021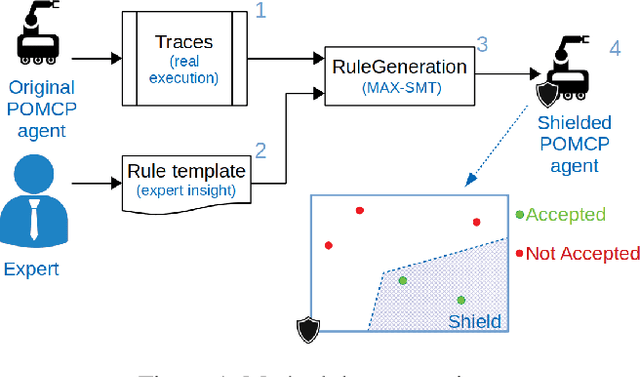


Partially Observable Monte-Carlo Planning (POMCP) is a powerful online algorithm able to generate approximate policies for large Partially Observable Markov Decision Processes. The online nature of this method supports scalability by avoiding complete policy representation. The lack of an explicit representation however hinders policy interpretability and makes policy verification very complex. In this work, we propose two contributions. The first is a method for identifying unexpected actions selected by POMCP with respect to expert prior knowledge of the task. The second is a shielding approach that prevents POMCP from selecting unexpected actions. The first method is based on Satisfiability Modulo Theory (SMT). It inspects traces (i.e., sequences of belief-action-observation triplets) generated by POMCP to compute the parameters of logical formulas about policy properties defined by the expert. The second contribution is a module that uses online the logical formulas to identify anomalous actions selected by POMCP and substitutes those actions with actions that satisfy the logical formulas fulfilling expert knowledge. We evaluate our approach on Tiger, a standard benchmark for POMDPs, and a real-world problem related to velocity regulation in mobile robot navigation. Results show that the shielded POMCP outperforms the standard POMCP in a case study in which a wrong parameter of POMCP makes it select wrong actions from time to time. Moreover, we show that the approach keeps good performance also if the parameters of the logical formula are optimized using trajectories containing some wrong actions.
Identification of Unexpected Decisions in Partially Observable Monte-Carlo Planning: a Rule-Based Approach
Dec 23, 2020

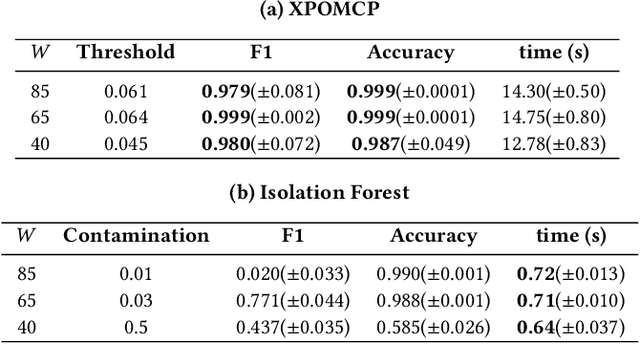

Partially Observable Monte-Carlo Planning (POMCP) is a powerful online algorithm able to generate approximate policies for large Partially Observable Markov Decision Processes. The online nature of this method supports scalability by avoiding complete policy representation. The lack of an explicit representation however hinders interpretability. In this work, we propose a methodology based on Satisfiability Modulo Theory (SMT) for analyzing POMCP policies by inspecting their traces, namely sequences of belief-action-observation triplets generated by the algorithm. The proposed method explores local properties of policy behavior to identify unexpected decisions. We propose an iterative process of trace analysis consisting of three main steps, i) the definition of a question by means of a parametric logical formula describing (probabilistic) relationships between beliefs and actions, ii) the generation of an answer by computing the parameters of the logical formula that maximize the number of satisfied clauses (solving a MAX-SMT problem), iii) the analysis of the generated logical formula and the related decision boundaries for identifying unexpected decisions made by POMCP with respect to the original question. We evaluate our approach on Tiger, a standard benchmark for POMDPs, and a real-world problem related to mobile robot navigation. Results show that the approach can exploit human knowledge on the domain, outperforming state-of-the-art anomaly detection methods in identifying unexpected decisions. An improvement of the Area Under Curve up to 47\% has been achieved in our tests.