 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Neurosymbolic Deep Reinforcement Learning
Jan 06, 2026Reinforcement Learning (RL) is a well-established framework for sequential decision-making in complex environments. However, state-of-the-art Deep RL (DRL) algorithms typically require large training datasets and often struggle to generalize beyond small-scale training scenarios, even within standard benchmarks. We propose a neuro-symbolic DRL approach that integrates background symbolic knowledge to improve sample efficiency and generalization to more challenging, unseen tasks. Partial policies defined for simple domain instances, where high performance is easily attained, are transferred as useful priors to accelerate learning in more complex settings and avoid tuning DRL parameters from scratch. To do so, partial policies are represented as logical rules, and online reasoning is performed to guide the training process through two mechanisms: (i) biasing the action distribution during exploration, and (ii) rescaling Q-values during exploitation. This neuro-symbolic integration enhances interpretability and trustworthiness while accelerating convergence, particularly in sparse-reward environments and tasks with long planning horizons. We empirically validate our methodology on challenging variants of gridworld environments, both in the fully observable and partially observable setting. We show improved performance over a state-of-the-art reward machine baseline.
Learning Symbolic Persistent Macro-Actions for POMDP Solving Over Time
May 06, 2025This paper proposes an integration of temporal logical reasoning and Partially Observable Markov Decision Processes (POMDPs) to achieve interpretable decision-making under uncertainty with macro-actions. Our method leverages a fragment of Linear Temporal Logic (LTL) based on Event Calculus (EC) to generate \emph{persistent} (i.e., constant) macro-actions, which guide Monte Carlo Tree Search (MCTS)-based POMDP solvers over a time horizon, significantly reducing inference time while ensuring robust performance. Such macro-actions are learnt via Inductive Logic Programming (ILP) from a few traces of execution (belief-action pairs), thus eliminating the need for manually designed heuristics and requiring only the specification of the POMDP transition model. In the Pocman and Rocksample benchmark scenarios, our learned macro-actions demonstrate increased expressiveness and generality when compared to time-independent heuristics, indeed offering substantial computational efficiency improvements.
Depth-Constrained ASV Navigation with Deep RL and Limited Sensing
Apr 25, 2025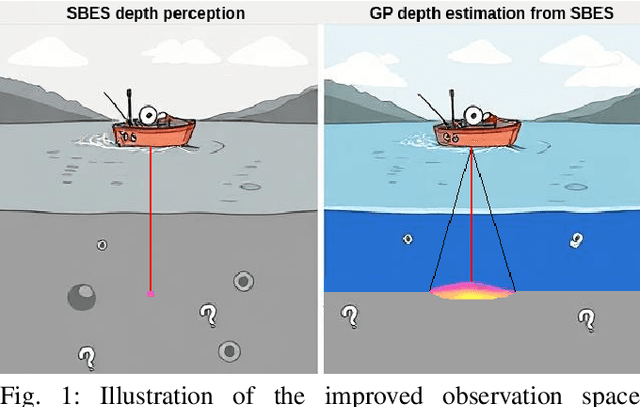

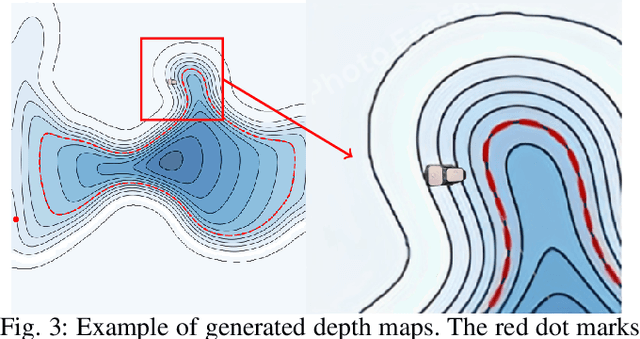
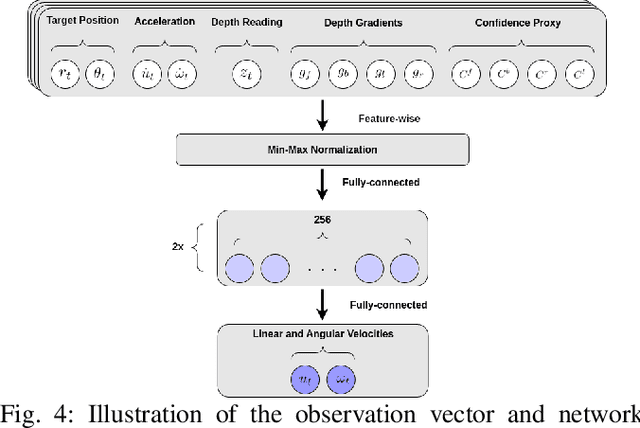
Autonomous Surface Vehicles (ASVs) play a crucial role in maritime operations, yet their navigation in shallow-water environments remains challenging due to dynamic disturbances and depth constraints. Traditional navigation strategies struggle with limited sensor information, making safe and efficient operation difficult. In this paper, we propose a reinforcement learning (RL) framework for ASV navigation under depth constraints, where the vehicle must reach a target while avoiding unsafe areas with only a single depth measurement per timestep from a downward-facing Single Beam Echosounder (SBES). To enhance environmental awareness, we integrate Gaussian Process (GP) regression into the RL framework, enabling the agent to progressively estimate a bathymetric depth map from sparse sonar readings. This approach improves decision-making by providing a richer representation of the environment. Furthermore, we demonstrate effective sim-to-real transfer, ensuring that trained policies generalize well to real-world aquatic conditions. Experimental results validate our method's capability to improve ASV navigation performance while maintaining safety in challenging shallow-water environments.
Monte Carlo Tree Search with Velocity Obstacles for safe and efficient motion planning in dynamic environments
Jan 16, 2025Online motion planning is a challenging problem for intelligent robots moving in dense environments with dynamic obstacles, e.g., crowds. In this work, we propose a novel approach for optimal and safe online motion planning with minimal information about dynamic obstacles. Specifically, our approach requires only the current position of the obstacles and their maximum speed, but it does not need any information about their exact trajectories or dynamic model. The proposed methodology combines Monte Carlo Tree Search (MCTS), for online optimal planning via model simulations, with Velocity Obstacles (VO), for obstacle avoidance. We perform experiments in a cluttered simulated environment with walls, and up to 40 dynamic obstacles moving with random velocities and directions. With an ablation study, we show the key contribution of VO in scaling up the efficiency of MCTS, selecting the safest and most rewarding actions in the tree of simulations. Moreover, we show the superiority of our methodology with respect to state-of-the-art planners, including Non-linear Model Predictive Control (NMPC), in terms of improved collision rate, computational and task performance.
Online inductive learning from answer sets for efficient reinforcement learning exploration
Jan 13, 2025This paper presents a novel approach combining inductive logic programming with reinforcement learning to improve training performance and explainability. We exploit inductive learning of answer set programs from noisy examples to learn a set of logical rules representing an explainable approximation of the agent policy at each batch of experience. We then perform answer set reasoning on the learned rules to guide the exploration of the learning agent at the next batch, without requiring inefficient reward shaping and preserving optimality with soft bias. The entire procedure is conducted during the online execution of the reinforcement learning algorithm. We preliminarily validate the efficacy of our approach by integrating it into the Q-learning algorithm for the Pac-Man scenario in two maps of increasing complexity. Our methodology produces a significant boost in the discounted return achieved by the agent, even in the first batches of training. Moreover, inductive learning does not compromise the computational time required by Q-learning and learned rules quickly converge to an explanation of the agent policy.
Inductive Learning of Robot Task Knowledge from Raw Data and Online Expert Feedback
Jan 13, 2025The increasing level of autonomy of robots poses challenges of trust and social acceptance, especially in human-robot interaction scenarios. This requires an interpretable implementation of robotic cognitive capabilities, possibly based on formal methods as logics for the definition of task specifications. However, prior knowledge is often unavailable in complex realistic scenarios. In this paper, we propose an offline algorithm based on inductive logic programming from noisy examples to extract task specifications (i.e., action preconditions, constraints and effects) directly from raw data of few heterogeneous (i.e., not repetitive) robotic executions. Our algorithm leverages on the output of any unsupervised action identification algorithm from video-kinematic recordings. Combining it with the definition of very basic, almost task-agnostic, commonsense concepts about the environment, which contribute to the interpretability of our methodology, we are able to learn logical axioms encoding preconditions of actions, as well as their effects in the event calculus paradigm. Since the quality of learned specifications depends mainly on the accuracy of the action identification algorithm, we also propose an online framework for incremental refinement of task knowledge from user feedback, guaranteeing safe execution. Results in a standard manipulation task and benchmark for user training in the safety-critical surgical robotic scenario, show the robustness, data- and time-efficiency of our methodology, with promising results towards the scalability in more complex domains.
Explainable Online Unsupervised Anomaly Detection for Cyber-Physical Systems via Causal Discovery from Time Series
Apr 15, 2024Online unsupervised detection of anomalies is crucial to guarantee the correct operation of cyber-physical systems and the safety of humans interacting with them. State-of-the-art approaches based on deep learning via neural networks achieve outstanding performance at anomaly recognition, evaluating the discrepancy between a normal model of the system (with no anomalies) and the real-time stream of sensor time series. However, large training data and time are typically required, and explainability is still a challenge to identify the root of the anomaly and implement predictive maintainance. In this paper, we use causal discovery to learn a normal causal graph of the system, and we evaluate the persistency of causal links during real-time acquisition of sensor data to promptly detect anomalies. On two benchmark anomaly detection datasets, we show that our method has higher training efficiency, outperforms the accuracy of state-of-the-art neural architectures and correctly identifies the sources of $>10$ different anomalies. The code for experimental replication is at http://tinyurl.com/case24causal.
Planning and Inverse Kinematics of Hyper-Redundant Manipulators with VO-FABRIK
Mar 08, 2024

Hyper-redundant Robotic Manipulators (HRMs) offer great dexterity and flexibility of operation, but solving Inverse Kinematics (IK) is challenging. In this work, we introduce VO-FABRIK, an algorithm combining Forward and Backward Reaching Inverse Kinematics (FABRIK) for repeatable deterministic IK computation, and an approach inspired from velocity obstacles to perform path planning under collision and joint limits constraints. We show preliminary results on an industrial HRM with 19 actuated joints. Our algorithm achieves good performance where a state-of-the-art IK solver fails.
Learning Logic Specifications for Policy Guidance in POMDPs: an Inductive Logic Programming Approach
Feb 29, 2024



Partially Observable Markov Decision Processes (POMDPs) are a powerful framework for planning under uncertainty. They allow to model state uncertainty as a belief probability distribution. Approximate solvers based on Monte Carlo sampling show great success to relax the computational demand and perform online planning. However, scaling to complex realistic domains with many actions and long planning horizons is still a major challenge, and a key point to achieve good performance is guiding the action-selection process with domain-dependent policy heuristics which are tailored for the specific application domain. We propose to learn high-quality heuristics from POMDP traces of executions generated by any solver. We convert the belief-action pairs to a logical semantics, and exploit data- and time-efficient Inductive Logic Programming (ILP) to generate interpretable belief-based policy specifications, which are then used as online heuristics. We evaluate thoroughly our methodology on two notoriously challenging POMDP problems, involving large action spaces and long planning horizons, namely, rocksample and pocman. Considering different state-of-the-art online POMDP solvers, including POMCP, DESPOT and AdaOPS, we show that learned heuristics expressed in Answer Set Programming (ASP) yield performance superior to neural networks and similar to optimal handcrafted task-specific heuristics within lower computational time. Moreover, they well generalize to more challenging scenarios not experienced in the training phase (e.g., increasing rocks and grid size in rocksample, incrementing the size of the map and the aggressivity of ghosts in pocman).
Learning Logic Specifications for Soft Policy Guidance in POMCP
Mar 16, 2023Partially Observable Monte Carlo Planning (POMCP) is an efficient solver for Partially Observable Markov Decision Processes (POMDPs). It allows scaling to large state spaces by computing an approximation of the optimal policy locally and online, using a Monte Carlo Tree Search based strategy. However, POMCP suffers from sparse reward function, namely, rewards achieved only when the final goal is reached, particularly in environments with large state spaces and long horizons. Recently, logic specifications have been integrated into POMCP to guide exploration and to satisfy safety requirements. However, such policy-related rules require manual definition by domain experts, especially in real-world scenarios. In this paper, we use inductive logic programming to learn logic specifications from traces of POMCP executions, i.e., sets of belief-action pairs generated by the planner. Specifically, we learn rules expressed in the paradigm of answer set programming. We then integrate them inside POMCP to provide soft policy bias toward promising actions. In the context of two benchmark scenarios, rocksample and battery, we show that the integration of learned rules from small task instances can improve performance with fewer Monte Carlo simulations and in larger task instances. We make our modified version of POMCP publicly available at https://github.com/GiuMaz/pomcp_clingo.git.