 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-based Shielding for Partially Observable Monte-Carlo Planning
Paper and Code
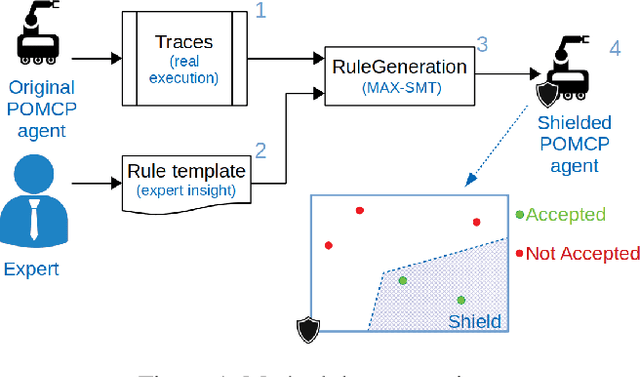


Partially Observable Monte-Carlo Planning (POMCP) is a powerful online algorithm able to generate approximate policies for large Partially Observable Markov Decision Processes. The online nature of this method supports scalability by avoiding complete policy representation. The lack of an explicit representation however hinders policy interpretability and makes policy verification very complex. In this work, we propose two contributions. The first is a method for identifying unexpected actions selected by POMCP with respect to expert prior knowledge of the task. The second is a shielding approach that prevents POMCP from selecting unexpected actions. The first method is based on Satisfiability Modulo Theory (SMT). It inspects traces (i.e., sequences of belief-action-observation triplets) generated by POMCP to compute the parameters of logical formulas about policy properties defined by the expert. The second contribution is a module that uses online the logical formulas to identify anomalous actions selected by POMCP and substitutes those actions with actions that satisfy the logical formulas fulfilling expert knowledge. We evaluate our approach on Tiger, a standard benchmark for POMDPs, and a real-world problem related to velocity regulation in mobile robot navigation. Results show that the shielded POMCP outperforms the standard POMCP in a case study in which a wrong parameter of POMCP makes it select wrong actions from time to time. Moreover, we show that the approach keeps good performance also if the parameters of the logical formula are optimized using trajectories containing some wrong actions.