 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Grounded 3D Generative Reconstruction under Hand Occlusion using Proprioception and Multi-Contact Touch
Apr 10, 2026We propose a multimodal, physically grounded approach for metric-scale amodal object reconstruction and pose estimation under severe hand occlusion. Unlike prior occlusion-aware 3D generation methods that rely only on vision, we leverage physical interaction signals: proprioception provides the posed hand geometry, and multi-contact touch constrains where the object surface must lie, reducing ambiguity in occluded regions. We represent object structure as a pose-aware, camera-aligned signed distance field (SDF) and learn a compact latent space with a Structure-VAE. In this latent space, we train a conditional flow-matching diffusion model, pretraining on vision-only images and finetuning on occluded manipulation scenes while conditioning on visible RGB evidence, occluder/visibility masks, the hand latent representation, and tactile information. Crucially, we incorporate physics-based objectives and differentiable decoder-guidance during finetuning and inference to reduce hand--object interpenetration and to align the reconstructed surface with contact observations. Because our method produces a metric, physically consistent structure estimate, it integrates naturally into existing two-stage reconstruction pipelines, where a downstream module refines geometry and predicts appearance. Experiments in simulation show that adding proprioception and touch substantially improves completion under occlusion and yields physically plausible reconstructions at correct real-world scale compared to vision-only baselines; we further validate transfer by deploying the model on a real humanoid robot with an end-effector different from those used during training.
Memory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
Mar 25, 2026Vision-Language Models (VLMs) often yield inconsistent descriptions of the same object across viewpoints, hindering the ability of embodied agents to construct consistent semantic representations over time. Previous methods resolved inconsistencies using offline multi-view aggregation or multi-stage pipelines that decouple exploration, data association, and caption learning, with limited capacity to reason over previously observed objects. In this paper, we introduce a unified, memory-augmented Vision-Language agent that simultaneously handles data association, object captioning, and exploration policy within a single autoregressive framework. The model processes the current RGB observation, a top-down explored map, and an object-level episodic memory serialized into object-level tokens, ensuring persistent object identity and semantic consistency across extended sequences. To train the model in a self-supervised manner, we collect a dataset in photorealistic 3D environments using a disagreement-based policy and a pseudo-captioning model that enforces consistency across multi-view caption histories. Extensive evaluation on a manually annotated object-level test set, demonstrate improvements of up to +11.86% in standard captioning scores and +7.39% in caption self-similarity over baseline models, while enabling scalable performance through a compact scene representation. Code, model weights, and data are available at https://github.com/hsp-iit/epos-vlm
Bayesian Active Object Recognition and 6D Pose Estimation from Multimodal Contact Sensing
Mar 22, 2026We present an active tactile exploration framework for joint object recognition and 6D pose estimation. The proposed method integrates wrist force/torque sensing, GelSight tactile sensing, and free-space constraints within a Bayesian inference framework that maintains a belief over object class and pose during active tactile exploration. By combining contact and non-contact evidence, the framework reduces ambiguity and improves robustness in the joint class-pose estimation problem. To enable efficient inference in the large hypothesis space, we employ a customized particle filter that progressively samples particles based on new observations. The inferred belief is further used to guide active exploration by selecting informative next touches under reachability constraints. For effective data collection, a motion planning and control framework is developed to plan and execute feasible paths for tactile exploration, handle unexpected contacts and GelSight-surface alignment with tactile servoing. We evaluate the framework in simulation and on a Franka Panda robot using 11 YCB objects. Results show that incorporating tactile and free-space information substantially improves recognition and pose estimation accuracy and stability, while reducing the number of action cycles compared with force/torque-only baselines. Code, dataset, and supplementary material will be made available online.
Event-based Motion & Appearance Fusion for 6D Object Pose Tracking
Mar 09, 2026Object pose tracking is a fundamental and essential task for robotics to perform tasks in the home and industrial settings. The most commonly used sensors to do so are RGB-D cameras, which can hit limitations in highly dynamic environments due to motion blur and frame-rate constraints. Event cameras have remarkable features such as high temporal resolution and low latency, which make them a potentially ideal vision sensors for object pose tracking at high speed. Even so, there are still only few works on 6D pose tracking with event cameras. In this work, we take advantage of the high temporal resolution and propose a method that uses both a propagation step fused with a pose correction strategy. Specifically, we use 6D object velocity obtained from event-based optical flow for pose propagation, after which, a template-based local pose correction module is utilized for pose correction. Our learning-free method has comparable performance to the state-of-the-art algorithms, and in some cases out performs them for fast-moving objects. The results indicate the potential for using event cameras in highly-dynamic scenarios where the use of deep network approaches are limited by low update rates.
Multifingered force-aware control for humanoid robots
Mar 09, 2026In this paper, we address force-aware control and force distribution in robotic platforms with multi-fingered hands. Given a target goal and force estimates from tactile sensors, we design a controller that adapts the motion of the torso, arm, wrist, and fingers, redistributing forces to maintain stable contact with objects of varying mass distribution or unstable contacts. To estimate forces, we collect a dataset of tactile signals and ground-truth force measurements using five Xela magnetic sensors interacting with indenters, and train force estimators. We then introduce a model-based control scheme that minimizes the distance between the Center of Pressure (CoP) and the centroid of the fingertips contact polygon. Since our method relies on estimated forces rather than raw tactile signals, it has the potential to be applied to any sensor capable of force estimation. We validate our framework on a balancing task with five objects, achieving a $82.7\%$ success rate, and further evaluate it in multi-object scenarios, achieving $80\%$ accuracy. Code and data can be found here https://github.com/hsp-iit/multifingered-force-aware-control.
A Baseline Study and Benchmark for Few-Shot Open-Set Action Recognition with Feature Residual Discrimination
Mar 04, 2026Few-Shot Action Recognition (FS-AR) has shown promising results but is often limited by a closed-set assumption that fails in real-world open-set scenarios. While Few-Shot Open-Set (FSOS) recognition is well-established for images, its extension to spatio-temporal video data remains underexplored. To address this, we propose an architectural extension based on a Feature-Residual Discriminator (FR-Disc), adapting previous work on skeletal data to the more complex video domain. Extensive experiments on five datasets demonstrate that while common open-set techniques provide only marginal gains, our FR-Disc significantly enhances unknown rejection capabilities without compromising closed-set accuracy, setting a new state-of-the-art for FSOS-AR. The project website, code, and benchmark are available at: https://hsp-iit.github.io/fsosar/.
Gaussian-Augmented Physics Simulation and System Identification with Complex Colliders
Nov 10, 2025

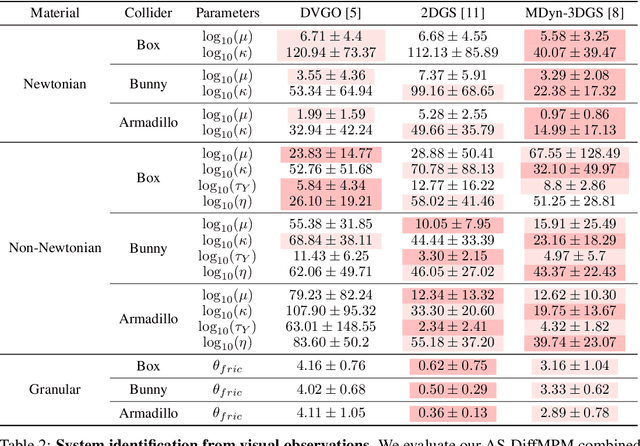

System identification involving the geometry, appearance, and physical properties from video observations is a challenging task with applications in robotics and graphics. Recent approaches have relied on fully differentiable Material Point Method (MPM) and rendering for simultaneous optimization of these properties. However, they are limited to simplified object-environment interactions with planar colliders and fail in more challenging scenarios where objects collide with non-planar surfaces. We propose AS-DiffMPM, a differentiable MPM framework that enables physical property estimation with arbitrarily shaped colliders. Our approach extends existing methods by incorporating a differentiable collision handling mechanism, allowing the target object to interact with complex rigid bodies while maintaining end-to-end optimization. We show AS-DiffMPM can be easily interfaced with various novel view synthesis methods as a framework for system identification from visual observations.
6-DoF Object Tracking with Event-based Optical Flow and Frames
Aug 20, 2025Tracking the position and orientation of objects in space (i.e., in 6-DoF) in real time is a fundamental problem in robotics for environment interaction. It becomes more challenging when objects move at high-speed due to frame rate limitations in conventional cameras and motion blur. Event cameras are characterized by high temporal resolution, low latency and high dynamic range, that can potentially overcome the impacts of motion blur. Traditional RGB cameras provide rich visual information that is more suitable for the challenging task of single-shot object pose estimation. In this work, we propose using event-based optical flow combined with an RGB based global object pose estimator for 6-DoF pose tracking of objects at high-speed, exploiting the core advantages of both types of vision sensors. Specifically, we propose an event-based optical flow algorithm for object motion measurement to implement an object 6-DoF velocity tracker. By integrating the tracked object 6-DoF velocity with low frequency estimated pose from the global pose estimator, the method can track pose when objects move at high-speed. The proposed algorithm is tested and validated on both synthetic and real world data, demonstrating its effectiveness, especially in high-speed motion scenarios.
PCHands: PCA-based Hand Pose Synergy Representation on Manipulators with N-DoF
Aug 11, 2025We consider the problem of learning a common representation for dexterous manipulation across manipulators of different morphologies. To this end, we propose PCHands, a novel approach for extracting hand postural synergies from a large set of manipulators. We define a simplified and unified description format based on anchor positions for manipulators ranging from 2-finger grippers to 5-finger anthropomorphic hands. This enables learning a variable-length latent representation of the manipulator configuration and the alignment of the end-effector frame of all manipulators. We show that it is possible to extract principal components from this latent representation that is universal across manipulators of different structures and degrees of freedom. To evaluate PCHands, we use this compact representation to encode observation and action spaces of control policies for dexterous manipulation tasks learned with RL. In terms of learning efficiency and consistency, the proposed representation outperforms a baseline that learns the same tasks in joint space. We additionally show that PCHands performs robustly in RL from demonstration, when demonstrations are provided from a different manipulator. We further support our results with real-world experiments that involve a 2-finger gripper and a 4-finger anthropomorphic hand. Code and additional material are available at https://hsp-iit.github.io/PCHands/.
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Apr 11, 2025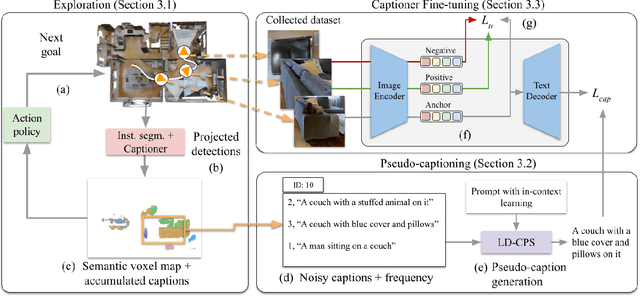
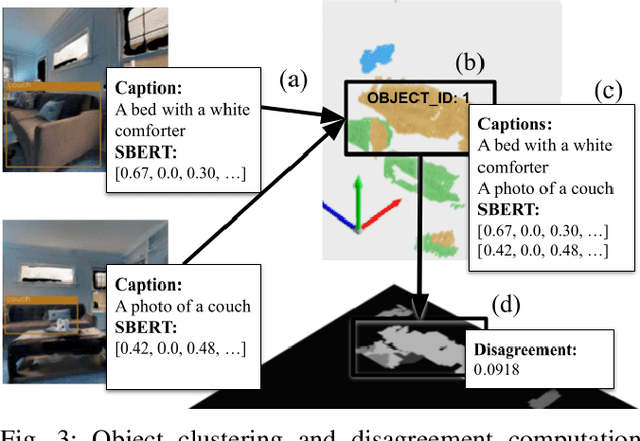
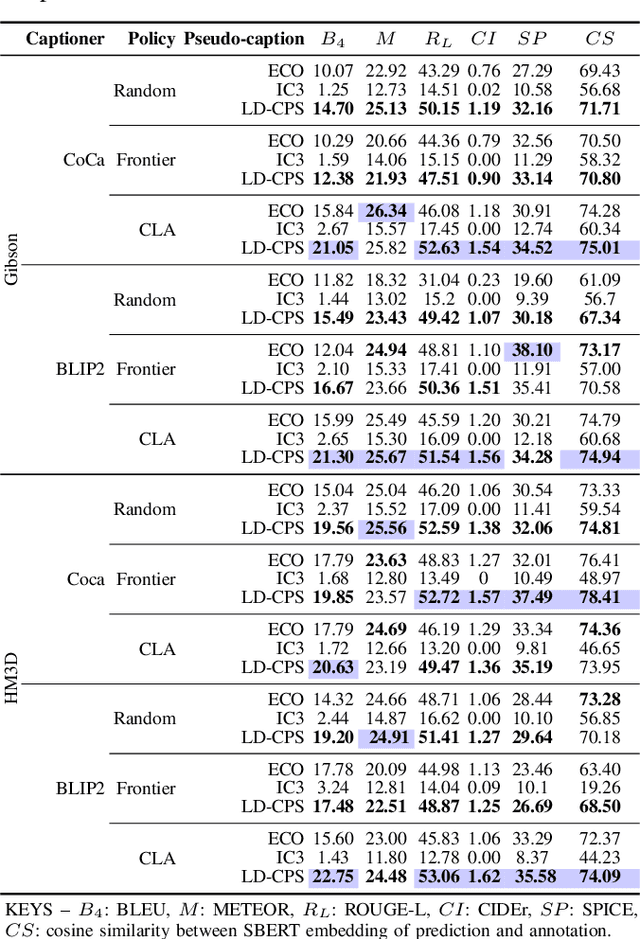

We present a self-supervised method to improve an agent's abilities in describing arbitrary objects while actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism. First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set. Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/