 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Multiple Sclerosis Lesions on 7-tesla MRI Using U-net and Transformer-based Segmentation
Apr 01, 2026Ultra-high field 7-tesla (7T) MRI improves visualization of multiple sclerosis (MS) white matter lesions (WML) but differs sufficiently in contrast and artifacts from 1.5-3T imaging - suggesting that widely used automated segmentation tools may not translate directly. We analyzed 7T FLAIR scans and generated reference WML masks from Lesion Segmentation Tool (LST) outputs followed by expert manual revision. As external comparators, we applied LST-LPA and the more recent LST-AI ensemble, both originally developed on lower-field data. We then trained 3D UNETR and SegFormer transformer-based models on 7T FLAIR at multiple resolutions (0.5x0.5x0.5^3, 1.0x1.0x1.0^3, and 1.5x1.5x2.0^3) and evaluated all methods using voxel-wise and lesion-wise metrics from the BraTS 2023 framework. On the held-out test set at native 0.5x0.5x0.5^3 resolution, 7T-trained transformers achieved competitive overlap with LST-AI while recovering additional small lesions that were missed by classical methods, at the cost of some boundary variability and occasional artifact-related false positives. On a held-out 7 T test set, our best transformer model (SegFormer) achieved a voxel-wise Dice of 0.61 and lesion-wise Dice of 0.20, improving on the classical LST-LPA tool (Dice 0.39, lesion-wise Dice 0.02). Performance decreased for models trained on downsampled images, underscoring the value of native 7T resolution for small-lesion detection. By releasing our 7T-trained models, we aim to provide a reproducible, ready-to-use resource for automated lesion quantification in ultra-high field MS research (https://github.com/maynord/7T-MS-lesion-segmentation).
NeuroAI and Beyond
Jan 27, 2026Neuroscience and Artificial Intelligence (AI) have made significant progress in the past few years but have only been loosely inter-connected. Based on a workshop held in August 2025, we identify current and future areas of synergism between these two fields. We focus on the subareas of embodiment, language and communication, robotics, learning in humans and machines and Neuromorphic engineering to take stock of the progress made so far, and possible promising new future avenues. Overall, we advocate for the development of NeuroAI, a type of Neuroscience-informed Artificial Intelligence that, we argue, has the potential for significantly improving the scope and efficiency of AI algorithms while simultaneously changing the way we understand biological neural computations. We include personal statements from several leading researchers on their diverse views of NeuroAI. Two Strength-Weakness-Opportunities-Threat (SWOT) analyses by researchers and trainees are appended that describe the benefits and risks offered by NeuroAI.
ControlTac: Force- and Position-Controlled Tactile Data Augmentation with a Single Reference Image
May 28, 2025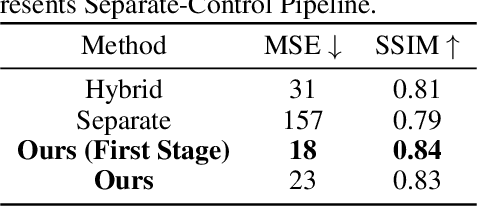
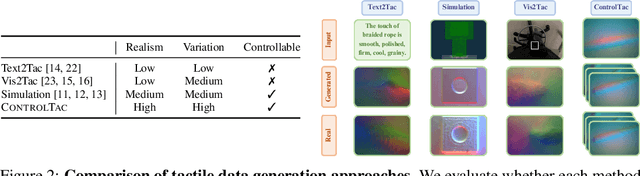
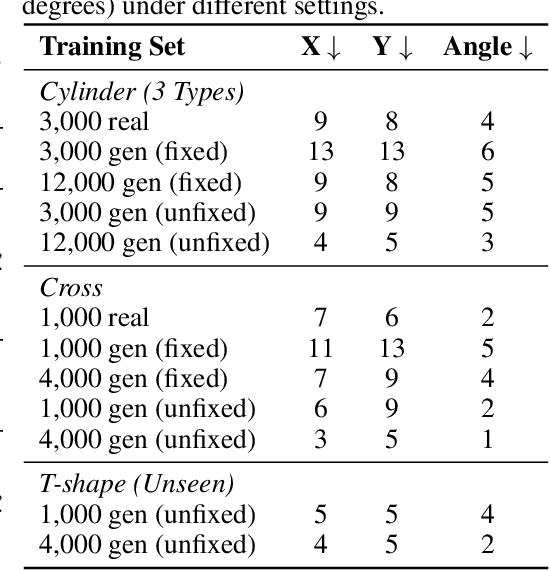
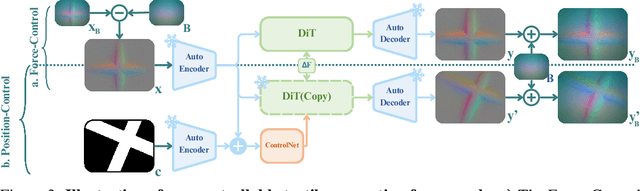
Vision-based tactile sensing has been widely used in perception, reconstruction, and robotic manipulation. However, collecting large-scale tactile data remains costly due to the localized nature of sensor-object interactions and inconsistencies across sensor instances. Existing approaches to scaling tactile data, such as simulation and free-form tactile generation, often suffer from unrealistic output and poor transferability to downstream tasks. To address this, we propose ControlTac, a two-stage controllable framework that generates realistic tactile images conditioned on a single reference tactile image, contact force, and contact position. With those physical priors as control input, ControlTac generates physically plausible and varied tactile images that can be used for effective data augmentation. Through experiments on three downstream tasks, we demonstrate that ControlTac can effectively augment tactile datasets and lead to consistent gains. Our three real-world experiments further validate the practical utility of our approach. Project page: https://dongyuluo.github.io/controltac.
A Real-Time Event-Based Normal Flow Estimator
Apr 28, 2025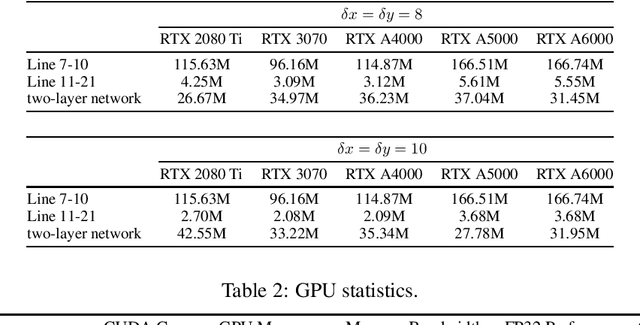

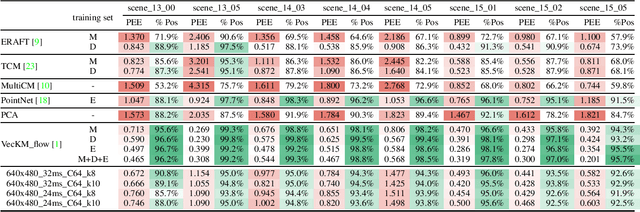
This paper presents a real-time, asynchronous, event-based normal flow estimator. It follows the same algorithm as Learning Normal Flow Directly From Event Neighborhoods, but with a more optimized implementation. The original method treats event slices as 3D point clouds, encodes each event's local geometry into a fixed-length vector, and uses a multi-layer perceptron to predict normal flow. It constructs representations by multiplying an adjacency matrix with a feature matrix, resulting in quadratic time complexity with respect to the number of events. In contrast, we leverage the fact that event coordinates are integers and reformulate the representation step as a pooling operation. This achieves the same effect as the adjacency matrix but with much lower computational cost. As a result, our method supports real-time normal flow prediction on event cameras. Our estimator uses 1 GB of CUDA memory and runs at 4 million normal flows per second on an RTX 3070, or 6 million per second on an RTX A5000. We release the CUDA implementation along with a Python interface at https://github.com/dhyuan99/VecKM_flow_cpp.
NatSGLD: A Dataset with Speech, Gesture, Logic, and Demonstration for Robot Learning in Natural Human-Robot Interaction
Feb 23, 2025Recent advances in multimodal Human-Robot Interaction (HRI) datasets emphasize the integration of speech and gestures, allowing robots to absorb explicit knowledge and tacit understanding. However, existing datasets primarily focus on elementary tasks like object pointing and pushing, limiting their applicability to complex domains. They prioritize simpler human command data but place less emphasis on training robots to correctly interpret tasks and respond appropriately. To address these gaps, we present the NatSGLD dataset, which was collected using a Wizard of Oz (WoZ) method, where participants interacted with a robot they believed to be autonomous. NatSGLD records humans' multimodal commands (speech and gestures), each paired with a demonstration trajectory and a Linear Temporal Logic (LTL) formula that provides a ground-truth interpretation of the commanded tasks. This dataset serves as a foundational resource for research at the intersection of HRI and machine learning. By providing multimodal inputs and detailed annotations, NatSGLD enables exploration in areas such as multimodal instruction following, plan recognition, and human-advisable reinforcement learning from demonstrations. We release the dataset and code under the MIT License at https://www.snehesh.com/natsgld/ to support future HRI research.
* arXiv admin note: substantial text overlap with arXiv:2403.02274
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Dec 24, 2024



Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
Learning Normal Flow Directly From Event Neighborhoods
Dec 15, 2024



Event-based motion field estimation is an important task. However, current optical flow methods face challenges: learning-based approaches, often frame-based and relying on CNNs, lack cross-domain transferability, while model-based methods, though more robust, are less accurate. To address the limitations of optical flow estimation, recent works have focused on normal flow, which can be more reliably measured in regions with limited texture or strong edges. However, existing normal flow estimators are predominantly model-based and suffer from high errors. In this paper, we propose a novel supervised point-based method for normal flow estimation that overcomes the limitations of existing event learning-based approaches. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, offering multiple unique advantages: 1) It produces temporally and spatially sharp predictions. 2) It supports more diverse data augmentation, such as random rotation, to improve robustness across various domains. 3) It naturally supports uncertainty quantification via ensemble inference, which benefits downstream tasks. 4) It enables training and inference on undistorted data in normalized camera coordinates, improving transferability across cameras. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets. Leveraging this transferability, we train our model on the union of datasets and release it for public use. Finally, we introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.
VioPose: Violin Performance 4D Pose Estimation by Hierarchical Audiovisual Inference
Nov 19, 2024



Musicians delicately control their bodies to generate music. Sometimes, their motions are too subtle to be captured by the human eye. To analyze how they move to produce the music, we need to estimate precise 4D human pose (3D pose over time). However, current state-of-the-art (SoTA) visual pose estimation algorithms struggle to produce accurate monocular 4D poses because of occlusions, partial views, and human-object interactions. They are limited by the viewing angle, pixel density, and sampling rate of the cameras and fail to estimate fast and subtle movements, such as in the musical effect of vibrato. We leverage the direct causal relationship between the music produced and the human motions creating them to address these challenges. We propose VioPose: a novel multimodal network that hierarchically estimates dynamics. High-level features are cascaded to low-level features and integrated into Bayesian updates. Our architecture is shown to produce accurate pose sequences, facilitating precise motion analysis, and outperforms SoTA. As part of this work, we collected the largest and the most diverse calibrated violin-playing dataset, including video, sound, and 3D motion capture poses. Project page: is available at https://sj-yoo.info/viopose/.
Extremum Seeking Controlled Wiggling for Tactile Insertion
Oct 03, 2024
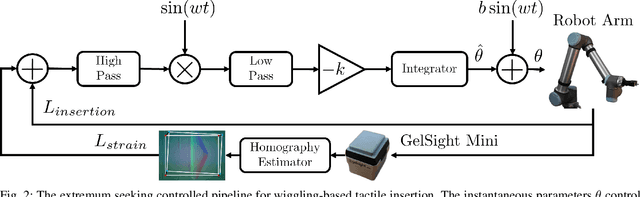


When humans perform insertion tasks such as inserting a cup into a cupboard, routing a cable, or key insertion, they wiggle the object and observe the process through tactile and proprioceptive feedback. While recent advances in tactile sensors have resulted in tactile-based approaches, there has not been a generalized formulation based on wiggling similar to human behavior. Thus, we propose an extremum-seeking control law that can insert four keys into four types of locks without control parameter tuning despite significant variation in lock type. The resulting model-free formulation wiggles the end effector pose to maximize insertion depth while minimizing strain as measured by a GelSight Mini tactile sensor that grasps a key. The algorithm achieves a 71\% success rate over 120 randomly initialized trials with uncertainty in both translation and orientation. Over 240 deterministically initialized trials, where only one translation or rotation parameter is perturbed, 84\% of trials succeeded. Given tactile feedback at 13 Hz, the mean insertion time for these groups of trials are 262 and 147 seconds respectively.
FeelAnyForce: Estimating Contact Force Feedback from Tactile Sensation for Vision-Based Tactile Sensors
Oct 02, 2024

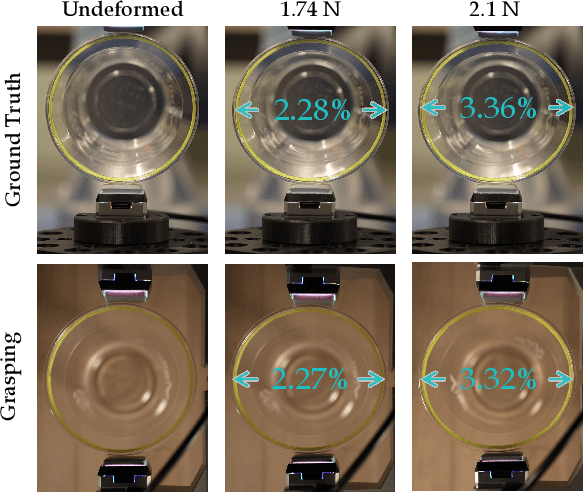

In this paper, we tackle the problem of estimating 3D contact forces using vision-based tactile sensors. In particular, our goal is to estimate contact forces over a large range (up to 15 N) on any objects while generalizing across different vision-based tactile sensors. Thus, we collected a dataset of over 200K indentations using a robotic arm that pressed various indenters onto a GelSight Mini sensor mounted on a force sensor and then used the data to train a multi-head transformer for force regression. Strong generalization is achieved via accurate data collection and multi-objective optimization that leverages depth contact images. Despite being trained only on primitive shapes and textures, the regressor achieves a mean absolute error of 4\% on a dataset of unseen real-world objects. We further evaluate our approach's generalization capability to other GelSight mini and DIGIT sensors, and propose a reproducible calibration procedure for adapting the pre-trained model to other vision-based sensors. Furthermore, the method was evaluated on real-world tasks, including weighing objects and controlling the deformation of delicate objects, which relies on accurate force feedback. Project webpage: http://prg.cs.umd.edu/FeelAnyForce