 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaelstrom Networks
Aug 29, 2024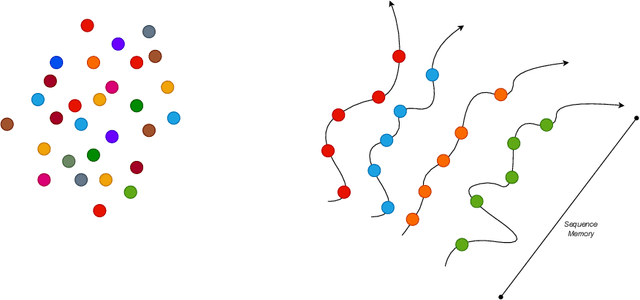
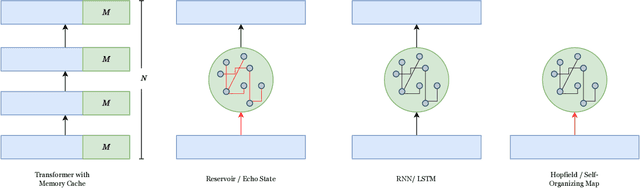
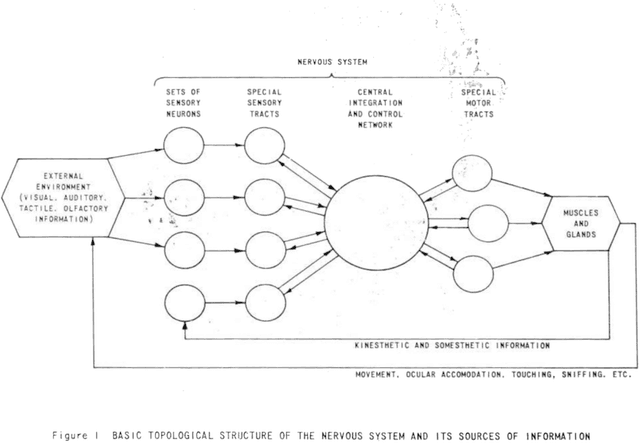
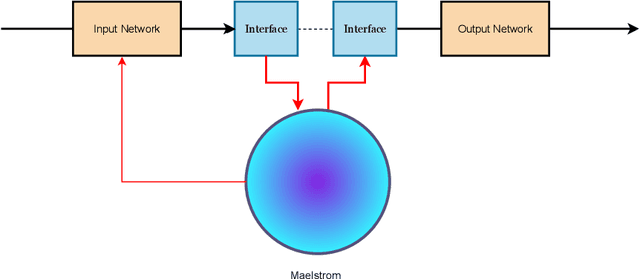
Artificial Neural Networks has struggled to devise a way to incorporate working memory into neural networks. While the ``long term'' memory can be seen as the learned weights, the working memory consists likely more of dynamical activity, that is missing from feed-forward models. Current state of the art models such as transformers tend to ``solve'' this by ignoring working memory entirely and simply process the sequence as an entire piece of data; however this means the network cannot process the sequence in an online fashion, and leads to an immense explosion in memory requirements. Here, inspired by a combination of controls, reservoir computing, deep learning, and recurrent neural networks, we offer an alternative paradigm that combines the strength of recurrent networks, with the pattern matching capability of feed-forward neural networks, which we call the \textit{Maelstrom Networks} paradigm. This paradigm leaves the recurrent component - the \textit{Maelstrom} - unlearned, and offloads the learning to a powerful feed-forward network. This allows the network to leverage the strength of feed-forward training without unrolling the network, and allows for the memory to be implemented in new neuromorphic hardware. It endows a neural network with a sequential memory that takes advantage of the inductive bias that data is organized causally in the temporal domain, and imbues the network with a state that represents the agent's ``self'', moving through the environment. This could also lead the way to continual learning, with the network modularized and ``'protected'' from overwrites that come with new data. In addition to aiding in solving these performance problems that plague current non-temporal deep networks, this also could finally lead towards endowing artificial networks with a sense of ``self''.
ProtoVAE: Prototypical Networks for Unsupervised Disentanglement
May 16, 2023Generative modeling and self-supervised learning have in recent years made great strides towards learning from data in a completely unsupervised way. There is still however an open area of investigation into guiding a neural network to encode the data into representations that are interpretable or explainable. The problem of unsupervised disentanglement is of particular importance as it proposes to discover the different latent factors of variation or semantic concepts from the data alone, without labeled examples, and encode them into structurally disjoint latent representations. Without additional constraints or inductive biases placed in the network, a generative model may learn the data distribution and encode the factors, but not necessarily in a disentangled way. Here, we introduce a novel deep generative VAE-based model, ProtoVAE, that leverages a deep metric learning Prototypical network trained using self-supervision to impose these constraints. The prototypical network constrains the mapping of the representation space to data space to ensure that controlled changes in the representation space are mapped to changes in the factors of variations in the data space. Our model is completely unsupervised and requires no a priori knowledge of the dataset, including the number of factors. We evaluate our proposed model on the benchmark dSprites, 3DShapes, and MPI3D disentanglement datasets, showing state of the art results against previous methods via qualitative traversals in the latent space, as well as quantitative disentanglement metrics. We further qualitatively demonstrate the effectiveness of our model on the real-world CelebA dataset.
Hybrid Backpropagation Parallel Reservoir Networks
Oct 27, 2020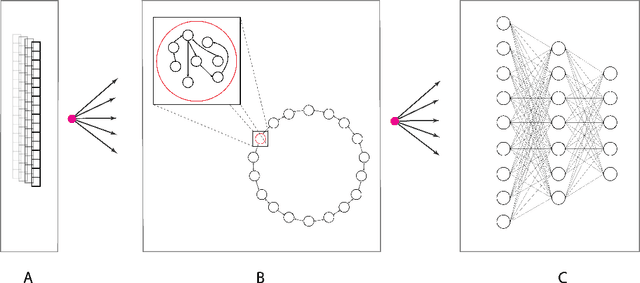
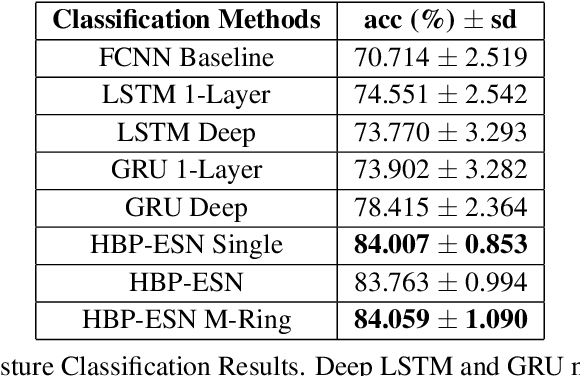

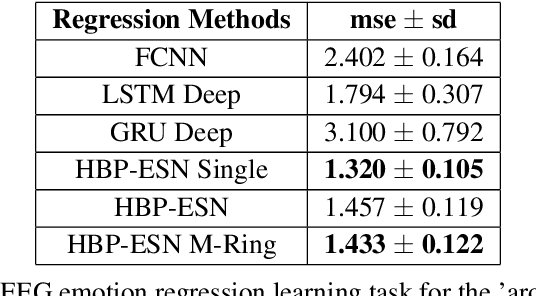
In many real-world applications, fully-differentiable RNNs such as LSTMs and GRUs have been widely deployed to solve time series learning tasks. These networks train via Backpropagation Through Time, which can work well in practice but involves a biologically unrealistic unrolling of the network in time for gradient updates, are computationally expensive, and can be hard to tune. A second paradigm, Reservoir Computing, keeps the recurrent weight matrix fixed and random. Here, we propose a novel hybrid network, which we call Hybrid Backpropagation Parallel Echo State Network (HBP-ESN) which combines the effectiveness of learning random temporal features of reservoirs with the readout power of a deep neural network with batch normalization. We demonstrate that our new network outperforms LSTMs and GRUs, including multi-layer "deep" versions of these networks, on two complex real-world multi-dimensional time series datasets: gesture recognition using skeleton keypoints from ChaLearn, and the DEAP dataset for emotion recognition from EEG measurements. We show also that the inclusion of a novel meta-ring structure, which we call HBP-ESN M-Ring, achieves similar performance to one large reservoir while decreasing the memory required by an order of magnitude. We thus offer this new hybrid reservoir deep learning paradigm as a new alternative direction for RNN learning of temporal or sequential data.
Deep Reservoir Networks with Learned Hidden Reservoir Weights using Direct Feedback Alignment
Oct 15, 2020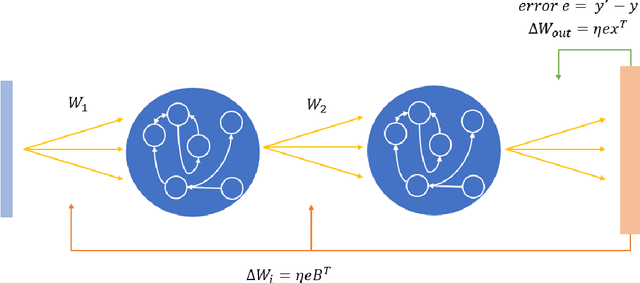

Deep Reservoir Computing has emerged as a new paradigm for deep learning, which is based around the reservoir computing principle of maintaining random pools of neurons combined with hierarchical deep learning. The reservoir paradigm reflects and respects the high degree of recurrence in biological brains, and the role that neuronal dynamics play in learning. However, one issue hampering deep reservoir network development is that one cannot backpropagate through the reservoir layers. Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artificial neural networks, but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Network for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. We demonstrate its efficacy on two real world multidimensional time series datasets.
A Deep 2-Dimensional Dynamical Spiking Neuronal Network for Temporal Encoding trained with STDP
Sep 01, 2020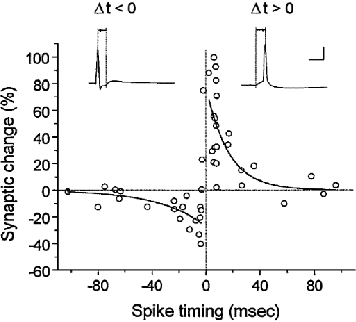


The brain is known to be a highly complex, asynchronous dynamical system that is highly tailored to encode temporal information. However, recent deep learning approaches to not take advantage of this temporal coding. Spiking Neural Networks (SNNs) can be trained using biologically-realistic learning mechanisms, and can have neuronal activation rules that are biologically relevant. This type of network is also structured fundamentally around accepting temporal information through a time-decaying voltage update, a kind of input that current rate-encoding networks have difficulty with. Here we show that a large, deep layered SNN with dynamical, chaotic activity mimicking the mammalian cortex with biologically-inspired learning rules, such as STDP, is capable of encoding information from temporal data. We argue that the randomness inherent in the network weights allow the neurons to form groups that encode the temporal data being inputted after self-organizing with STDP. We aim to show that precise timing of input stimulus is critical in forming synchronous neural groups in a layered network. We analyze the network in terms of network entropy as a metric of information transfer. We hope to tackle two problems at once: the creation of artificial temporal neural systems for artificial intelligence, as well as solving coding mechanisms in the brain.
Event-based attention and tracking on neuromorphic hardware
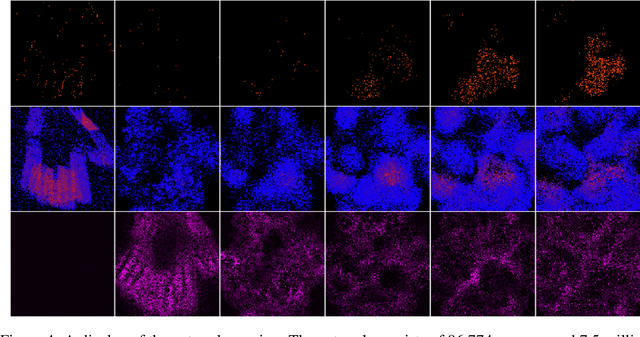
Jul 09, 2019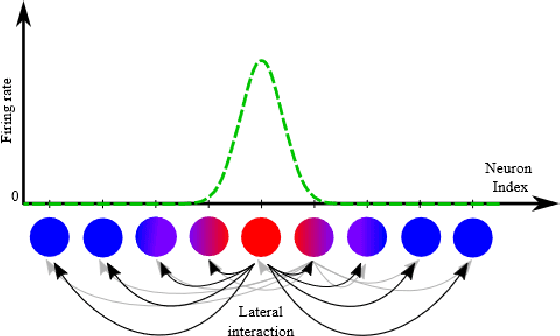
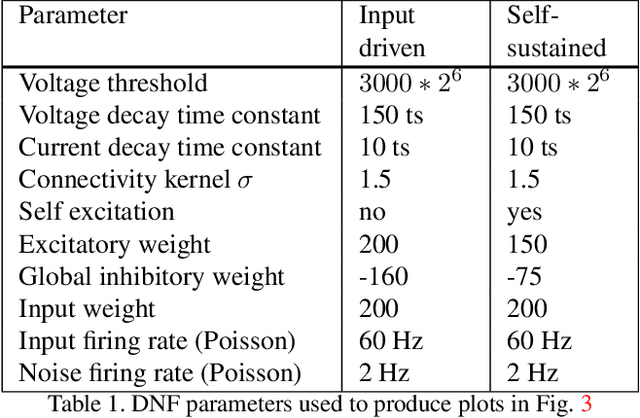
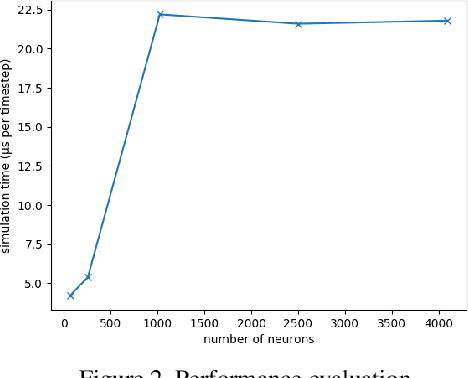
We present a fully event-driven vision and processing system for selective attention and tracking, realized on a neuromorphic processor Loihi interfaced to an event-based Dynamic Vision Sensor DAVIS. The attention mechanism is realized as a recurrent spiking neural network that implements attractor-dynamics of dynamic neural fields. We demonstrate capability of the system to create sustained activation that supports object tracking when distractors are present or when the object slows down or stops, reducing the number of generated events.
Network Deconvolution
May 28, 2019
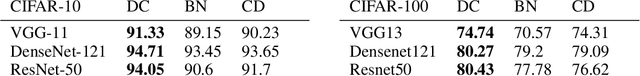
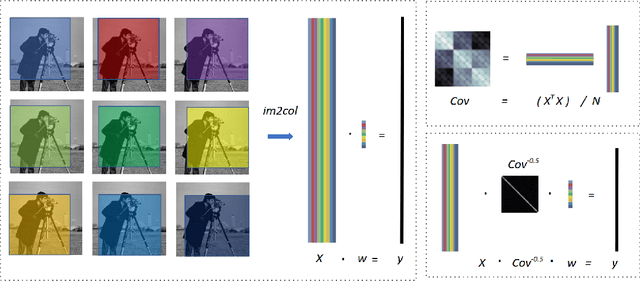

Convolution is a central operation in Convolutional Neural Networks (CNNs), which applies a kernel or mask to overlapping regions shifted across the image. In this work we show that the underlying kernels are trained with highly correlated data, which leads to co-adaptation of model weights. To address this issue we propose what we call network deconvolution, a procedure that aims to remove pixel-wise and channel-wise correlations before the data is fed into each layer. We show that by removing this correlation we are able to achieve better convergence rates during model training with superior results without the use of batch normalization on the CIFAR-10, CIFAR-100, MNIST, Fashion-MNIST datasets, as well as against reference models from "model zoo" on the ImageNet standard benchmark.